
カテゴリー




記事一覧
-

【Docker】AI エージェント「NanoClaw」環境の構築と docker compose build 手順
-
【FortiGate】強制アップグレード(自動アップグレード)の仕様と回避対策
-
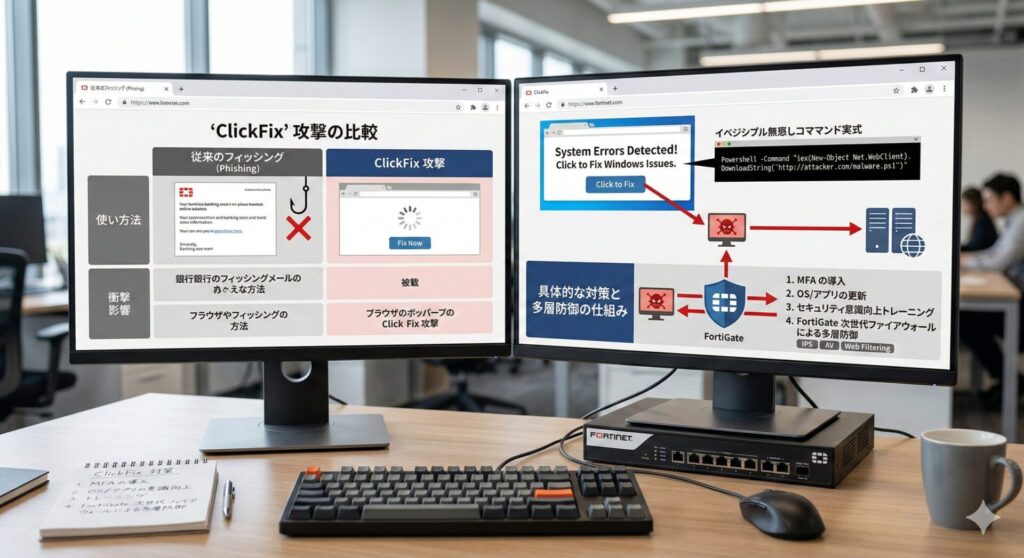
【セキュリティ】急増する ClickFix 攻撃とは?巧妙な手口と有効な対策
-
【Linux】CentOS の移行先比較 | AlmaLinux・Rocky Linux・MIRACLE LINUX の違い
-
【OpenClaw】オープンソースの自律型 AI エージェントとは?仕組みと基本機能
-
【FortiGate】Upgrade Path Tool とは?安全なバージョンアップ手順と使い方
-
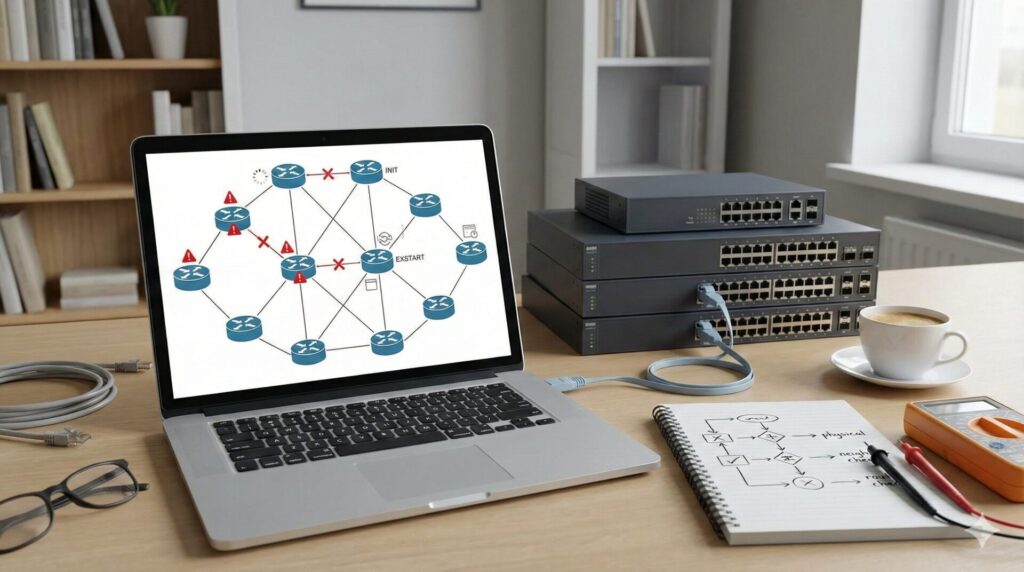
【OSPF】ネイバーが確立しない原因とトラブルシューティング手順
-
【OSPF】基本設定の手順とネットワーク構築のコンフィグ例
-
【Cisco】実機は不要 |「Packet Tracer」のインストールから使い方まで