

はじめに
Web サイトの閲覧時やシステムの運用管理中に、「503 Service Unavailable(または 503 Service Temporarily Unavailable)」 というエラー画面に遭遇することがあります。
このエラーは、アクセス先のサーバが一時的に過負荷状態にある、メンテナンス中である、あるいは バックエンドのサービスやプロセスが停止していて応答できない ことを示す HTTP ステータスコードです。原因は単純なアクセス集中から、内部サービスの停止、設定不整合まで多岐にわたります。
特にシステム管理の現場では、vCSA(VMware vCenter Server Appliance) や Apache リバースプロキシ環境 で 503 エラーに遭遇するケースが多く、それぞれ典型的な原因と対処手順があります。本記事では、503 エラーの概要と類似コード(502 / 504)との違いを整理したうえで、これら 2 つの環境における具体的なトラブルシューティング手順を Broadcom 公式ドキュメントに基づいて解説します。
- 503 Service Unavailable の概要と意味
- 5xx 系エラー(500 / 502 / 503 / 504)の違い
- 503 エラーが発生する主な原因と一般的な対策
- vCSA 7.0 / 8.0 で発生する 503 エラーの 5 つの典型原因と対処手順(vpxd 停止、DB 肥大化、証明書期限切れ、vpxd.cfg 破損、リバースプロキシ停止)
- Apache リバースプロキシでの SELinux 起因 503 エラーの切り分け方法
503 Service Unavailable とは?
503 Service Unavailable は、Web サイトや Web アプリケーションにアクセスした際、サーバが一時的にリクエストを処理できない状態であることを示す HTTP ステータスコードです(「503 Service Temporarily Unavailable」とも表記)。
このエラーが返される場合、サーバのネットワーク機能自体は稼働して通信に応答できていますが、過負荷状態やメンテナンスなどの理由により、要求された処理を実行する余裕がないことを意味しています。「Temporarily(一時的に)」 とあるように、サーバの物理的な故障などの恒久的な障害ではなく、原因が解消されれば復旧する性質を持っています。
参考: HTTP Status Code 503 – MDN Web Docs
“The HTTP 503 Service Unavailable server error response status code indicates that the server is not ready to handle the request. Common causes are a server that is down for maintenance or that is overloaded.”
(HTTP 503 Service Unavailable は、サーバがリクエストを処理する準備が整っていないことを示すステータスコードです。一般的な原因は、メンテナンスでサーバが停止しているか過負荷状態にあることです)
https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/503
サーバ管理者として 503 エラーに遭遇した場合、「ネットワークやハードウェアそのものは生きている可能性が高い」 という前提で、稼働中のプロセスやサービスのほうから切り分けを進めるのが効率的です。
5xx 系エラーの違い(500 / 502 / 503 / 504)
503 と並んで遭遇しやすい 5xx 系のエラーには 500 / 502 / 504 があります。「サーバ側で何か起きている」という共通点はあるものの、実際の発生箇所と原因が異なる ため、切り分けの第一歩として違いを押さえておくと有効です。
| エラーコード | 名称 | 発生箇所 | 主な原因 |
|---|---|---|---|
| 500 | Internal Server Error | サーバ内部のアプリケーション層 | アプリケーションコードのバグ、未処理の例外 |
| 502 | Bad Gateway | プロキシ / ロードバランサー | バックエンドサーバから不正な応答、または通信不可 |
| 503 | Service Unavailable | サーバ自身またはバックエンドサービス | サーバ過負荷、メンテナンス中、サービス停止 |
| 504 | Gateway Timeout | プロキシ / ロードバランサー | バックエンドサーバへの応答待ちタイムアウト |
502 と 503 の違い
503 と特に混同されやすいのが 502 Bad Gateway です。両者はいずれも「Web ページが表示されない」結果になりますが、システム内部で問題が発生している箇所が異なります。
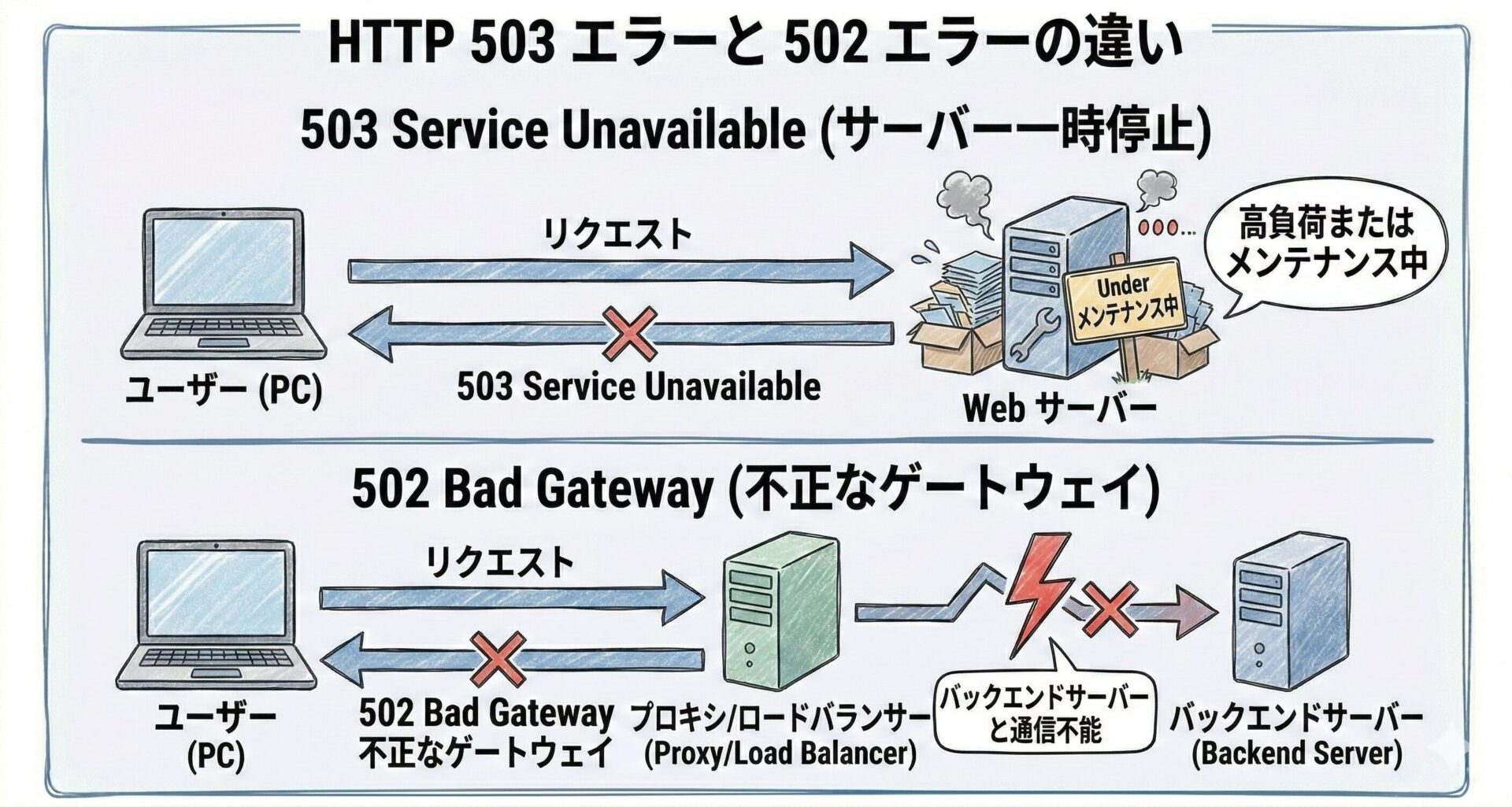
- 503 Service Unavailable
-
アクセス先のサーバ自身が「現在、リクエストを処理する余裕がない」と応答している状態。サーバのリソース不足やバックエンドサービスの停止が主な原因
- 502 Bad Gateway
-
アクセス先のプロキシやロードバランサーが、その背後の別サーバから「不正な応答を受け取った」または「通信できなかった」状態。サーバ間の連携エラーが主な原因
503 と 504 の違い
503 と 504 も似た状況で発生します。両者の違いは「バックエンドが応答するかどうか」です。
- 503: バックエンドサービスが起動していない、または明示的に「処理できない」と応答している
- 504: バックエンドは存在するが応答が遅く、プロキシ側でタイムアウトに到達
vCSA や Apache リバースプロキシ環境では、設定不整合の場合は 503、ネットワーク経路の問題やバックエンドの応答遅延の場合は 502 / 504 という形で切り分けの起点にできます。
503 エラーが発生する主な原因
503 エラーは「サーバが一時的に処理を拒否している」状態ですが、その背景には主に以下のような原因があります。
アクセス集中によるリソース(CPU・メモリ)の枯渇
最も一般的な原因は、Web サイトへの突発的なアクセス集中です。SNS での拡散やメディアでの紹介などにより、想定を大きく超えるトラフィックが発生すると、サーバの CPU やメモリ、あるいは同時接続数の上限に達してしまい、新たなリクエストを処理しきれずに 503 エラーを返します。
計画的なメンテナンスやサービスの再起動中
システム管理者が意図的に Web サーバをメンテナンスモードに設定している場合や、サーバの再起動処理を行っている最中にも 503 エラーが表示されます。この場合は、システム側が「現在サービスを提供できない」ことを正しく応答している正常な動作とも言えます。
バックエンドサービス(データベース、内部プロセス等)の停止・異常
Web サーバ自体は正常に稼働していても、その裏側で連携しているアプリケーションプロセスやデータベースのサービスがダウンしている場合、要求された処理を完了できず 503 エラーとなることがあります。後述する vCSA や Apache リバースプロキシでの 503 エラーは、主にこの「バックエンドの停止・異常」に該当 します。
設定不整合やリソース不足の波及
直接的な原因ではないものの、ディスク領域不足、証明書の期限切れ、設定ファイルの破損などが、結果としてサービスを停止させ、間接的に 503 エラーを引き起こすケースもあります。
503 エラーの一般的な対策
503 エラーに直面した場合の対策は、「Web サイトの閲覧者(ユーザ)」 であるか、「システムの管理者」 であるかによって大きく異なります。
ユーザ側の対策(時間を置いて再アクセス)
Web サイトを閲覧していて 503 エラーが出た場合、ユーザ側で根本的に解決できる手段はありません。エラー画面に「Service Temporarily Unavailable(一時的に利用不可)」とあるとおり、しばらく時間を置いてから再度アクセスを試みるのが基本的な対応となります。
注意点として、エラー画面のままページ更新を連続して行うと、サーバにさらなる負荷をかけ、復旧を遅らせる原因になる ため控えることをおすすめします。
サーバ管理者側の対策(ログ確認、リソース拡張、サービス再起動)
自身の管理する Web サイトやシステムで 503 エラーが発生している場合、以下の視点で調査と対策を行います。
ログの確認
まず Web サーバ(Apache / Nginx 等)のエラーログを確認し、アクセス集中によるリソース不足なのか、内部プロセスのエラーなのか、あるいは設定不整合なのかを切り分けます。
# Apache のエラーログを確認(RHEL 系)
tail -100 /var/log/httpd/error_log
# エラー行のみ絞り込み
grep -i "error" /var/log/httpd/error_log | tail -20
# Nginx のエラーログを確認
tail -100 /var/log/nginx/error.logリソースの拡張と負荷分散
アクセス集中が原因であれば、サーバスペックの引き上げ(スケールアップ)や、ロードバランサーを用いた複数台構成(スケールアウト)、CDN によるキャッシュ配信などの導入を検討します。
停止プロセスの再起動
バックエンドのサービスやデータベースが停止している場合は、該当プロセスの状態(ステータス)を確認し、再起動を試みます。サービス停止の原因(設定変更、リソース不足、証明書期限切れなど)を特定しないまま再起動を繰り返すと根本解決につながらないため、原因の切り分けと並行して対応することが重要です。
【実例 1】vCSA 環境での 503 エラー: 原因別の対処手順
システム管理の現場における具体例として、VMware vCenter Server Appliance(vCSA 7.0 / 8.0) の Web 管理画面(vSphere Client)にアクセスした際、以下のような 503 エラーで接続できないケースがあります。
503 Service Unavailable (Failed to connect to endpoint:
[N7Vmacore4Http20NamedPipeServiceSpecE:0x0000562eebf99a50]
_serverNamespace = / action = Allow
_pipeName =/var/run/vmware/vpxd-webserver-pipe)vCSA の 503 エラーは 複数の原因で発生し得る ため、原因の特定と対処の順序が重要です。Broadcom 公式ドキュメントで案内されている主な原因は以下の 5 つです。
参考: Error “503 Service Unavailable” when attempting to access vCenter Server vSphere Client – Broadcom Knowledge
“Errors may appear as: 503 Service Unavailable. Common causes include: vCenter Server services not started, vCenter Server is down because of maintenance, the reverse Proxy service on vCenter Server is down, the vSphere web client service is down, mis-configured Firewall settings.”
(503 Service Unavailable エラーの典型的な原因として、vCenter サービスの未起動、メンテナンスによる停止、リバースプロキシサービスの停止、vSphere Web Client サービスの停止、ファイアウォール設定の誤りなどが挙げられます)
https://knowledge.broadcom.com/external/article?legacyId=67818
原因 1: vpxd サービスの停止
最も頻発する原因が、vCSA のコアサービスである vpxd(VMware vCenter Server デーモン) の停止です。エラーメッセージに vpxd-webserver-pipe という文言が含まれていれば、このパターンの可能性が高いと判断できます。
サービス状態の確認
vCSA に SSH でログインし、service-control コマンドを使用してサービスの稼働状態を確認します。
# 全サービスのステータス確認
service-control --status
# 特定サービス(vpxd)のステータス確認
service-control --status vmware-vpxdStopped: の項目に vmware-vpxd が含まれている場合、サービスが停止しています。service-control コマンドは vCSA 7.0 / 8.0 でも継続して使用できます。
サービスの起動
# vpxd サービスの起動
service-control --start vmware-vpxd
# 起動後のステータス確認
service-control --status vmware-vpxdRunning: に vmware-vpxd が含まれていれば復旧完了です。10〜15 分待っても起動しない、あるいは起動直後に再び Stopped へ遷移する場合は、別の原因(次に挙げる DB 肥大化や設定不整合など)を疑います。
原因 2: データベース(/storage/seat)の肥大化
vpxd を再起動しても安定稼働しない場合、vCSA 内部の PostgreSQL データベース領域(/storage/seat)が容量上限に達している可能性があります。
参考: VPXD Service Fails to Start – Broadcom Knowledge
“vpxd service may be shut down by the operating system under some conditions to prevent database corruption.”
(vpxd サービスは、データベースの破損を防ぐため、一定の条件下で OS によって停止されることがあります)
https://knowledge.broadcom.com/external/article/322158/vpxd-service-fails-to-start.html
ディスク使用率の確認
# /storage/seat 領域の使用率を確認
df -h /storage/seat
# vCSA 全体のディスク使用状況
df -hUse% が 95% 以上 となっている場合、不要なデータを削除して容量を空ける必要があります。なお vCSA 6.5 以降では仮想ディスクが 12 個に分割されており、/storage/seat は履歴・統計データ専用のパーティションです。
肥大化テーブルの特定
PostgreSQL に接続し、容量を圧迫しているテーブルを確認します。
# PostgreSQL に接続
cd /opt/vmware/vpostgres/current/bin
./psql -d VCDB -U postgres-- 上位 5 つの大容量テーブルを表示
SELECT nspname || '.' || relname AS "relation",
pg_size_pretty(pg_total_relation_size(C.oid)) AS "total_size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY pg_total_relation_size(C.oid) DESC
LIMIT 5;テーブルのデータ削除(Truncate)
肥大化しているテーブル(タスク履歴の vc.vpx_task やイベント履歴の vc.vpx_event など)が特定できたら、内部のデータを削除します。
-- タスク履歴テーブルのデータを削除(カスケード)
TRUNCATE TABLE vc.vpx_task CASCADE;重要: TRUNCATE は履歴データを完全に削除する操作であり、事前にスナップショットまたはバックアップの取得を強くおすすめします。また、Broadcom サポートに問い合わせ中の場合は、サポート対応への影響を考慮して事前にケース担当者へ確認することを推奨します。
ディスク使用率が 90% 以下になるまで履歴テーブルの削除を繰り返し、最後に vCSA を再起動することで 503 エラーが解消されます。再発防止策 として、vSphere Client の [vCenter Server の設定] → [データベース] から 「タスクとイベントの保持日数」を短く調整(既定 30 日 → 7〜14 日程度)することを検討します。
原因 3: 証明書の期限切れ
vCSA は内部で複数の証明書(STS 証明書、マシン SSL 証明書、ソリューションユーザ証明書 など)を使用しており、いずれかが期限切れになるとサービスが起動できず 503 エラーにつながります。本番運用 2 年以上の vCSA で頻発するパターンです。
vCSA 7.0 / 8.0 では Broadcom が vCert(vCenter Certificate Manager Tool) を提供しており、期限切れ証明書の特定と交換を半自動で実施できます。詳細な手順は Broadcom Knowledge Base の vCert 関連記事を参照することをおすすめします。
期限切れ証明書を対処するには、/usr/lib/vmware-vmca/bin/certificate-manager を使用した個別証明書の再生成、または vCSA の VAMI(5480 ポート)から実施できる証明書管理機能の利用が選択肢になります。本番環境で発生した場合は、Broadcom サポートに問い合わせのうえで対応することをおすすめします。
原因 4: vpxd.cfg 設定ファイルの破損
service-control --start vmware-vpxd を実行しても起動に失敗し、/var/log/vmware/vpxd/vpxd.log にログが書き込まれない、または起動直後に /var/core ディレクトリにダンプファイルが生成されるケースは、/etc/vmware-vpx/vpxd.cfg の破損 が疑われます。
参考: Validating corrupt VCSA (vpxd.cfg) – Broadcom Knowledge
“The following are possibilities with a corrupt vpxd.cfg file: VCSA is inaccessible through the web client with error ‘503 service unavailable’. vmware-vpxd service crashes and produces a dump file in the /var/core directory immediately on start.”
(vpxd.cfg ファイルが破損している場合の症状として、503 エラーで VCSA にアクセス不可、vmware-vpxd サービスがクラッシュして /var/core にダンプファイルを生成するなどがあります)
https://knowledge.broadcom.com/external/article/316610/validating-corrupt-vcsa-vpxdcfg.html
# 設定ファイルとダンプファイルの存在を確認
ls -l /etc/vmware-vpx/vpxd.cfg
ls -lh /var/core/破損が確認された場合は、Broadcom KB の手順に従って 同バージョンの vCenter VM を一時的にデプロイし、そこから取得した vpxd.cfg をコピーして書き換える という復旧手順を取ることになります。本番環境で発生した場合は、Broadcom サポートに問い合わせのうえで対応することをおすすめします。
原因 5: リバースプロキシサービス(rhttpproxy)の停止
vpxd は稼働しているのに 503 が返される場合、vCSA のフロントに位置する リバースプロキシサービス(vmware-rhttpproxy) の停止が原因のことがあります。
# rhttpproxy のステータス確認
service-control --status vmware-rhttpproxy
# 停止していれば起動
service-control --start vmware-rhttpproxyこのパターンは「vpxd は Running なのに vSphere Client が 503 を返す」というやや判別しづらい状況になるため、service-control --status ですべてのサービスの状態を一覧確認する習慣があると切り分けがスムーズです。
切り分けフロー(まとめ)
vCSA で 503 エラーが発生したときの切り分けは、以下の順序で進めるのが効率的です。
service-control --statusで全サービスの状態確認(vpxd / rhttpproxy / vsphere-client 等)- 停止サービスがあれば
--startで起動を試みる - 起動失敗 / 即停止する場合は
df -hでディスク容量確認(/storage/seatの 95% 超は要対処) - ディスクに問題がなければ 証明書期限の確認(特に STS 証明書)
- それでも解消しない場合は
/etc/vmware-vpx/vpxd.cfgの破損確認 - ログ(
/var/log/vmware/vpxd/vpxd.log)から具体的な失敗原因を特定
vCSA のリソース問題(CPU 競合・メモリ逼迫)が複合的に発生しているケースもあります。CPU 競合の確認手順については関連記事『VMware CPU Ready と Steal の見方|esxtop での確認手順』、メモリ管理の挙動については『VMware メモリバルーニングとは|仕組みと esxtop での確認手順』も参考にしてください。
【実例 2】Apache リバースプロキシでの 503 エラー(SELinux 起因)
Web サーバのフロントに Apache を用いたリバースプロキシ(RHEL 9 / AlmaLinux 9 / Rocky Linux 9 等)を配置している環境で、クライアントからのアクセス時に 503 エラーが発生するケースがあります。本セクションでは典型的な SELinux 起因のケースを取り上げます。
なお、本記事執筆時点で CentOS 7 は 2024 年 6 月 30 日に EOL を迎えているため、現行の RHEL 系ディストリビューションを前提とします。
エラーの典型的な兆候
Apache のエラーログ(/var/log/httpd/error_log)を確認し、以下のような出力があれば SELinux による接続ブロックが疑われます。
[error] (13)Permission denied: proxy: HTTP: attempt to connect to 10.1.x.x:8080 (10.1.x.x) failed
[error] ap_proxy_connect_backend disabling worker for (10.1.x.x)Permission denied と (13) というエラーコードがキーポイントです。Apache プロセス自体は動いているにもかかわらず、バックエンドサーバへのネットワーク接続が拒否されている状態を示しています。
原因: SELinux ブール値による接続ブロック
このエラーは、SELinux のセキュリティ機能によって、httpd(Apache)プロセスがバックエンドの Web サーバへネットワーク接続することがブロックされている ために発生します。RHEL / AlmaLinux / Rocky Linux などのディストリビューションでは、SELinux のデフォルトポリシーで Apache の外向き接続が制限されています。
参考: How to Set Up Apache as a Reverse Proxy on RHEL – OneUptime
“SELinux on RHEL blocks Apache from making outgoing network connections by default. You need to enable the httpd_can_network_connect boolean.”
(RHEL の SELinux はデフォルトで Apache の外向きネットワーク接続をブロックします。httpd_can_network_connectブール値を有効化する必要があります)
https://oneuptime.com/blog/post/2026-03-04-setup-apache-reverse-proxy-rhel-9/view
切り分け手順
# SELinux が有効かどうかを確認(Enforcing / Permissive / Disabled)
getenforce
# httpd 関連ブール値の現状を確認
getsebool -a | grep httpdhttpd_can_network_connect が off になっていれば、これが原因の可能性が高くなります。
SELinux が実際に接続をブロックしているかを確認するには、ausearch コマンドが有効です。
# 直近の httpd 関連の SELinux 拒否ログを確認
sudo ausearch -m avc -c httpd --start recentavc: denied { name_connect } for ... scontext=...httpd_t ... のような出力があれば、SELinux による接続ブロックが確定します。
対処: SELinux ブール値の有効化
httpd_can_network_connect を有効化することで、Apache のバックエンドサーバへのネットワーク接続を許可します。-P オプションを付けることで、再起動後も設定が永続化 されます。
# httpd プロセスのネットワーク接続を許可(永続化)
sudo setsebool -P httpd_can_network_connect 1
# 設定を確認
getsebool httpd_can_network_connect
# → httpd_can_network_connect --> on設定後、Apache を再起動して動作を確認します。
sudo systemctl restart httpd
curl -I http://your-proxy.example.com/より細かいポリシー制御(参考)
セキュリティ要件が厳しい環境では、すべてのポートへの接続を許可するのではなく、接続先ポートを SELinux で個別に許可 する方法もあります。
# 8080 ポートを http_port_t として SELinux に登録
sudo semanage port -a -t http_port_t -p tcp 8080この方法であれば、httpd_can_network_connect を off のまま維持しつつ、特定ポートへの接続のみ許可できます。
SELinux 自体の無効化について
検証目的などで一時的に SELinux 自体を無効化する場合は、以下の方法があります。ただし 本番環境での恒久的な無効化はセキュリティ上のリスクが大きいため推奨されません。
# 一時的に Permissive モード(ログのみ、ブロックしない)に変更
sudo setenforce 0
# 恒久的に無効化する場合は /etc/selinux/config を編集
# SELINUX=enforcing → SELINUX=disabled に変更後、OS を再起動
sudo vi /etc/selinux/config
sudo reboot設定ファイルのパスは RHEL 8 / 9 系では /etc/selinux/config が標準です。古い CentOS 6 / 7 系で使われていた /etc/sysconfig/selinux はシンボリックリンクとして残っているケースがありますが、最新環境では /etc/selinux/config を直接編集する形が一般的です。
まとめ
本記事では、503 Service Unavailable エラーの概要と、vCSA / Apache リバースプロキシ環境での具体的なトラブルシューティング手順を整理しました。
- 503 は サーバの過負荷・メンテナンス・バックエンドサービス停止 によって一時的に処理ができない状態を示す
- 5xx 系では 500(アプリ層)/ 502(ゲートウェイ不正応答)/ 503(処理不可)/ 504(応答タイムアウト) で発生箇所が異なる
- vCSA の 503 エラーには 5 つの典型原因: vpxd 停止 / DB 肥大化 / 証明書期限切れ / vpxd.cfg 破損 / rhttpproxy 停止
- vCSA の切り分けは
service-control --status→df -h→ 証明書 → vpxd.cfg → ログ確認 の順が効率的 - DB の
TRUNCATE操作前には スナップショット / バックアップ取得を強く推奨 - Apache リバースプロキシでは SELinux ブール値
httpd_can_network_connectの有効化(setsebool -Pで永続化)で対処 - AVC 拒否ログの確認には
ausearch -m avc -c httpdが有効
以上、最後までお読みいただきありがとうございました。

