

はじめに
毎日の進捗確認、複数サイトの巡回チェック、検索結果や課題一覧の収集とレポート化。こうした定型作業は、一度仕組みを作れば Python で自動化できます。手作業を置き換えることで、本来注力したい業務に時間を回せます。
一方で、いざ自動化を始めようとすると「何から手をつければよいか」「どんな構成で組めば後から再利用しやすいか」で迷いがちです。個別のライブラリの使い方を断片的に覚えるより、自動化に共通する型を先に押さえておくと、対象が変わっても応用が利きます。
本記事は、Python で業務を自動化するための共通の型と勘所を整理する入口です。個別の API やツールの詳しい手順は、関連記事(スポーク記事)へ案内します。
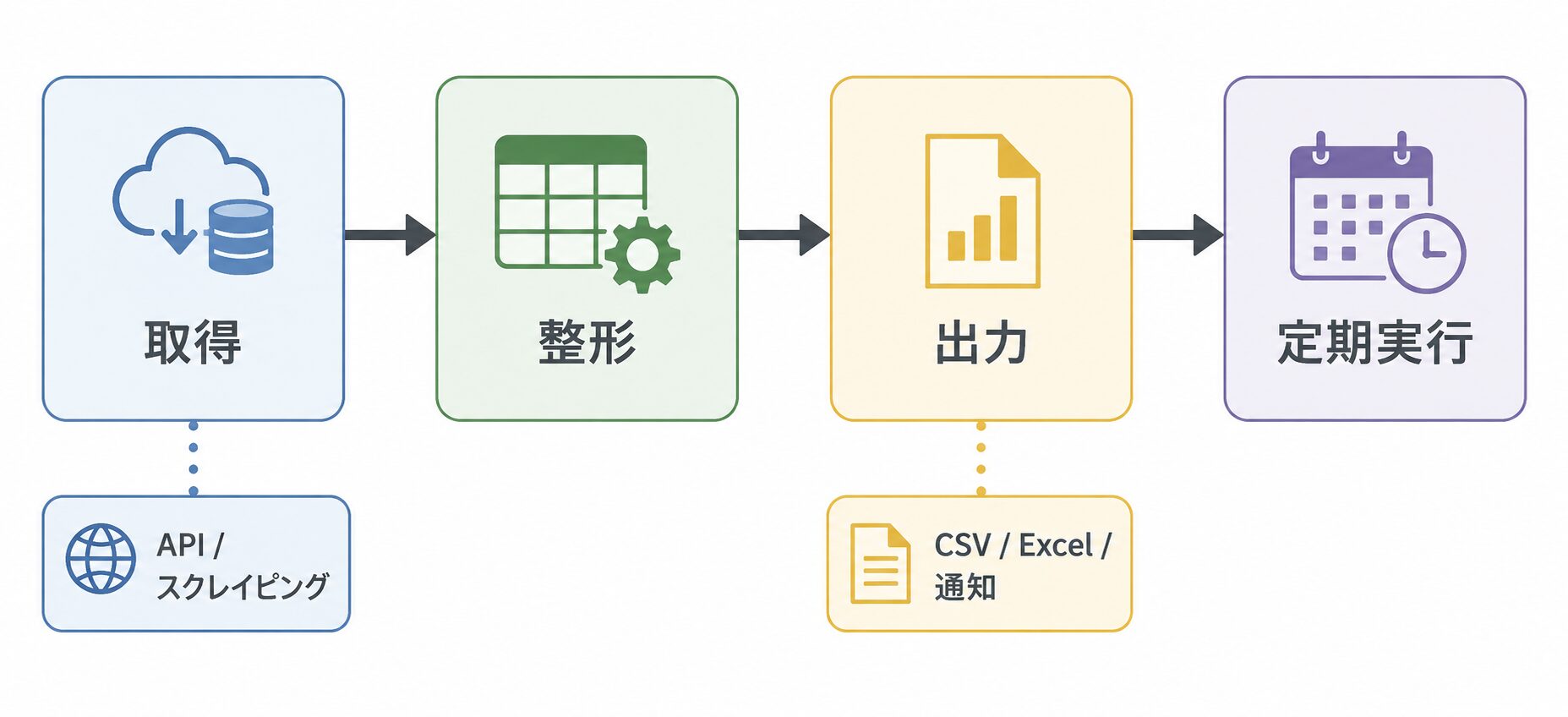
- Python 自動化の全体像(取得 → 整形 → 出力 → 定期実行の 4 段の型)
- データ取得で API とスクレイピングをどう使い分けるか
- 認証情報の管理・ページネーション・レート制限・エラー処理という共通の勘所
- 取得したデータを CSV や Excel に出力し、定期実行へつなげる方法
結論を先に述べると、多くの自動化は「データを取得し、整形し、出力し、定期的に実行する」という 4 段の流れに整理できます。この型を軸にすれば、対象が API でもスクレイピングでも、出力先が CSV でも通知でも、同じ骨格で組み立てられます。本記事ではこの型を俯瞰し、各段の具体的な実装は関連記事へつなげていきます。
Python 自動化の全体像: 4 段の型
Python による業務自動化は、次の 4 段に分けて考えると見通しが良くなります。多くの自動化スクリプトは、この組み合わせで成り立っています。
自動化の起点は、データの取得です。取得元は大きく 2 つに分かれます。1 つは API で、サービスが公式に提供する窓口から、構造化されたデータ(多くは JSON)を受け取ります。もう 1 つはスクレイピングで、Web ページの HTML から必要な情報を抜き出します。API が用意されている場合は、安定性や利用規約の面から API を優先するのが基本です。詳しい使い分けは後述します。
この blog では、用途別に取得の実装例を用意しています。GraphQL での取得は『AniList API でデータを取得してグラフ化する手順』、REST での取得は『Backlog API で課題一覧を取得し CSV 出力する手順』、検索結果(SERP)の取得は『Python で Google 検索結果を取得する方法』が該当します。
取得した生データは、そのままでは使いにくいことが多いため、必要な項目を抜き出し、並べ替え、欠損を補うといった整形を行います。JSON の入れ子から目的の値を取り出したり、複数の取得結果を 1 つの表にまとめたりする工程です。
整形したデータを、CSV や Excel、あるいは通知メッセージなどの成果物として出力します。Excel で開く前提なら CSV の文字コードに配慮する、可視化するならグラフ画像にする、というように、用途に応じて出力先を選びます。
最後に、作成したスクリプトを定期的に実行する仕組みを用意すると、文字どおりの自動化になります。手元の PC なら cron(Linux/Mac)やタスクスケジューラ(Windows)、常時稼働させたいならクラウド上での実行が選択肢です。これにより、毎朝・毎週といった頻度で、人手を介さずに処理が回ります。
この 4 段のうち、1 と 2 と 3 を 1 つのスクリプトにまとめ、4 で定期的に呼び出す、というのが基本構成です。以降、各段の具体的な実装と、つまずきやすい共通の勘所を順に見ていきます。
データの取得: API とスクレイピングの使い分け
自動化の起点となるデータ取得には、API とスクレイピングの 2 つの手段があります。どちらを使うかは、対象サービスが API を提供しているかで決まります。
API が使えるなら API を優先する
API は、サービスが公式に提供するデータ取得の窓口です。構造化された JSON が返るため整形が容易で、利用規約の範囲が明確という利点があります。公式 API が提供されている場合は、それを使うのが最も安全でマナーの良い方法とされています。SNS や検索サービスのように、HTML の直接取得を規約で禁じつつ API を用意しているサービスも多く、API があるなら API を選ぶのが基本です。
この blog の取得スポークは、いずれも API ベースです。プロトコル別に、GraphQL は『AniList API でデータを取得してグラフ化する手順』、REST は『Backlog API で課題一覧を取得し CSV 出力する手順』、検索結果(SERP)は『Python で Google 検索結果を取得する方法』で、それぞれ具体的な実装を解説しています。
スクレイピングは事前確認を前提に
API が用意されていない場合は、requests と BeautifulSoup などで HTML から情報を抜き出すスクレイピングが選択肢になります。ただし、取得できることと取得してよいことは別です。実行前に、対象サイトの利用規約、robots.txt、公式 API の有無を確認するのが前提になります。法的・規約上の注意点は本記事の後半で詳しく扱います。
requests の基本形
API でもスクレイピングでも、HTTP リクエストの土台は共通です。requests でリクエストを送り、ステータスを確認し、結果を受け取る、という流れになります。
import requests
url = "https://api.example.com/v1/items"
params = {"limit": 20}
response = requests.get(url, params=params, timeout=30)
response.raise_for_status() # エラーなら例外を発生させる
data = response.json() # JSON を辞書・リストとして受け取るraise_for_status() を呼ぶと、認証エラーや見つからないエンドポイントなどで例外が発生し、問題に早く気付けます。timeout を指定しておくと、応答が返らないまま処理が止まり続けるのを防げます。
共通の勘所: 認証情報・ページネーション・レート制限・エラー処理
取得の対象が変わっても、つまずきやすいポイントは共通しています。ここを型として押さえておくと、どの API でも応用が利きます。
認証情報はコードに直書きしない
API キーやトークンは、ソースコードに直接書き込まず、環境変数から読み込むのが基本です。コードを共有・公開した際の漏えいを防げます。とくに、API キーをリクエストの URL に付与する方式のサービスでは、URL がログに残ってキーが漏れる経路にもなるため注意します。
import os
API_KEY = os.environ["EXAMPLE_API_KEY"] # 事前に環境変数へ設定しておくページネーションで全件を取得する
多くの API は、1 回のリクエストで返す件数に上限があります。上限を超えるデータを扱う場合は、offset や cursor、ページ番号を進めながら複数回リクエストして全件を集めます。返却件数が上限未満になったら最後のページと判断する、という形が定番です。具体的な実装は、offset を進める例を『Backlog API の記事』で解説しています。
レート制限に配慮する
API には、単位時間あたりのリクエスト数に上限(レート制限)が設けられています。超過すると一般に HTTP 429 が返ります。過剰なリクエストはサーバーに負荷をかけ、不法行為や業務妨害と判断される可能性もあるため、リクエストは直列で行い、間に待機を入れて分散させるのが安全です。429 が返った場合は、応答ヘッダーの待機時間(Retry-After など)を参照してリトライ間隔を調整します。
import time
import requests
def get_with_retry(url, params, max_retries=3):
for _ in range(max_retries):
response = requests.get(url, params=params, timeout=30)
if response.status_code == 429:
wait = int(response.headers.get("Retry-After", 60))
time.sleep(wait)
continue
response.raise_for_status()
return response.json()
raise RuntimeError("リトライ上限に達しました。")エラー処理で止まらないようにする
自動化スクリプトは無人で動くため、エラーで止まったままにならない設計が重要です。通信エラーやタイムアウトを例外として捕捉し、ログに残す、一定回数までリトライする、といった備えをしておきます。定期実行では、失敗時に通知を送る仕組みを足すと、異常に気付きやすくなります。
これらの勘所は、各スポークの実装にも共通して登場します。レート制限への対処は SerpApi や Backlog の記事、認証情報の環境変数管理は各取得記事で、それぞれ具体例を確認できます。
データの整形と出力: CSV・Excel
取得した生データは、そのままでは扱いにくいことが多いため、必要な項目を抜き出し、表として並べてから出力します。
JSON から必要な項目を取り出す
API が返す JSON は、辞書とリストの入れ子構造です。目的の値を取り出す際は、キーが存在しない要素が混ざってもエラーになりにくいよう、get() で安全に参照します。複数の取得結果は、1 件 1 行のリストにまとめておくと、後段の CSV 出力や集計が容易になります。
rows = []
for item in data.get("items", []):
rows.append({
"id": item.get("id"),
"title": item.get("title", ""),
"url": item.get("url", ""),
})CSV に出力する
整形したデータは、CSV として保存すると Excel や表計算ソフトでそのまま開けます。日本語を含む場合は、Excel での文字化けを防ぐため utf_8_sig(BOM 付き UTF-8)を指定します。csv.DictWriter を使うと、列名を定義して辞書をそのまま書き出せます。実装例は『Backlog API で課題一覧を取得し CSV 出力する手順』で詳しく解説しています。
import csv
with open("output.csv", "w", encoding="utf_8_sig", newline="") as f:
writer = csv.DictWriter(f, fieldnames=["id", "title", "url"])
writer.writeheader()
writer.writerows(rows)なお、CSV の文字コードでつまずいた場合は、関連記事『Python の SyntaxError: Non-UTF-8 code starting with を解決』も参考になります。
Excel やグラフとして出力する
セルの書式や複数シートが必要なら、openpyxl や pandas で Excel ファイルとして出力します。さらに、数値の傾向を可視化したい場合は、グラフ画像として出力する選択肢もあります。可視化は別の専門領域になるため、本記事では深入りせず、相関のヒートマップは『Python で相関分析を行う手順』、対話的なガントチャートは『Plotly でガントチャートを作成する手順』へ案内します。データ分析・可視化の全体像は、別途のまとめ記事で扱う予定です。
定期実行: 自動で繰り返す仕組み
取得から出力までを 1 つのスクリプトにまとめたら、最後にそれを定期的に実行する仕組みを用意します。代表的な選択肢は次の 3 つです。
OS のスケジューラ(cron・タスクスケジューラ)
最も手軽なのは、OS 標準のスケジューラです。Linux/Mac では cron、Windows ではタスクスケジューラを使います。この方式は、Python プログラムを起動したままにする必要がなく、システムが毎回スクリプトを呼び出すため、定期実行自体が途中で止まりにくい利点があります。
cron の場合は crontab -e で設定を編集し、「分 時 日 月 曜日 コマンド」の形式で記述します。たとえば毎日 9 時に実行するなら次のようになります。
0 9 * * * /usr/bin/python3 /home/user/script.pycron で動かす際によくあるつまずきが、パスと環境変数です。スクリプトや出力先は相対パスではなく絶対パスで指定し、対話シェルでしか読まれない環境変数(API キーなど)は、cron からも参照できる形で設定しておく必要があります。Windows のタスクスケジューラでは、GUI で基本タスクを作成し、Python の実行ファイルとスクリプトのパスを指定します。
GitHub Actions(クラウドで定期実行)
PC を起動していなくても動かしたい場合は、GitHub Actions の schedule トリガーが手軽な選択肢です。cron と同じ記法でスケジュールを書けます。ただし注意点があります。スケジュールは UTC 基準で指定する必要があり(日本時間は UTC+9 時間)、実行は指定時刻から数分から、場合によっては 1 時間以上遅延することがあります。最短は 5 分間隔が推奨で、パブリックリポジトリは無料、プライベートでも一定の無料枠があります。厳密な時刻が必要な処理には向きませんが、毎朝・毎週といった用途には十分です。API キーは GitHub の Secrets に登録し、コードに含めないようにします。
クラウドのサーバーレス実行
より本格的に運用するなら、クラウドのサーバーレス実行も選択肢です。AWS Lambda や Google Cloud Functions を使うと、サーバーを常時起動せずにタスクを実行できます。スケジュール起動と組み合わせれば、定期的なデータ収集を低コストで運用できます。
どれを選ぶかは、PC 常時起動の可否、共有の必要性、求める時刻の厳密さで決まります。手元で完結するなら OS のスケジューラ、PC を起動せず動かすなら GitHub Actions、本格運用ならクラウド、という整理が目安です。これらの各手段の詳しい設定は、今後スポーク記事として個別に扱う予定です。
自動化の注意点
自動化スクリプトは無人で繰り返し動くため、手作業以上に配慮が必要な点があります。とくにスクレイピングを伴う場合は、事前の確認が欠かせません。
利用規約・robots.txt・公式 API の確認
データ取得を伴う自動化では、実行前に対象サイトの利用規約、robots.txt、公式 API の有無を確認します。利用規約で自動アクセスやスクレイピングを禁止しているサイトは少なくありません。robots.txt は法的拘束力を持つものではありませんが、サイト運営者の意思表示として尊重するのが適切です。公式 API が用意されている場合は、API を使うのが最も安全です。
サーバーへの負荷をかけない
短時間に大量のリクエストを送ると、対象サーバーに負荷をかけ、業務妨害と判断される可能性があります。リクエストの間隔を空け、低頻度で実行することが、トラブル回避とマナーの両面で重要です。レート制限や待機の実装は、前述の共通の勘所が役立ちます。
認証突破・個人情報・著作権
ログインが必要な領域へ正規の権限なくアクセスする行為は、単なる情報収集とは別次元の問題を含みます。また、取得対象に個人情報や著作物が含まれる場合は、利用目的や再利用の範囲に法的な制約が生じます。商用利用や大規模な収集を予定している場合は、必要に応じて法律の専門家に相談するのが安全です。本記事は法的助言ではなく、判断の前提として確認すべき観点の整理にとどまります。
文字コードのトラブル
取得したデータを保存・読み込みする際、文字コードの不一致で処理が止まることがあります。CSV の文字化けや、ファイル読み込み時のエラーに遭遇した場合は、関連記事『Python の SyntaxError: Non-UTF-8 code starting with を解決』で原因と対処を解説しています。
まとめ
本記事では、Python で業務を自動化するための共通の型を解説しました。取得 → 整形 → 出力 → 定期実行という 4 段の流れと、各段でつまずきやすい勘所を整理しました。
- 自動化は取得・整形・出力・定期実行の 4 段に整理できる
- データ取得は、API が使えるなら API を優先する
- 認証情報はコードに直書きせず環境変数で管理する
- 全件取得はページネーション、混雑時はレート制限に配慮
- 出力は CSV や Excel、可視化は専門記事へ
- 定期実行は OS スケジューラ・GitHub Actions・クラウドから選ぶ
- スクレイピングは利用規約と robots.txt の事前確認が前提
各段の具体的な実装は、AniList・Backlog・検索 API の取得記事や、相関分析・ガントチャートの可視化記事で詳しく解説しています。本記事を地図として、目的に合った記事から実装を進めてください。
以上、最後までお読みいただきありがとうございました。

