

はじめに
取得したデータをそのまま眺めていても、傾向や関係は見えてきません。数字の表を、傾向や関係が読み取れる形に変えていく工程がデータ分析です。Python には、データ分析のための定番ライブラリが揃っており、読み込みから前処理、集計、可視化までを一貫して行えます。
一方で、いざ分析を始めようとすると「どんな順序で進めればよいか」「可視化はどのライブラリを使えばよいか」で迷いがちです。Matplotlib・Seaborn・Plotly といった可視化ライブラリは、それぞれ得意分野が異なり、目的に合わないものを選ぶと手間が増えます。分析の流れとライブラリ選定の基準を先に押さえておくと、対象データが変わっても応用が利きます。
本記事は、Python でデータ分析を進めるための流れと、可視化ライブラリ選定の基準を整理する入口です。個別の手法(相関分析や各グラフの作成)の詳しい手順は、関連記事(スポーク記事)へ案内します。
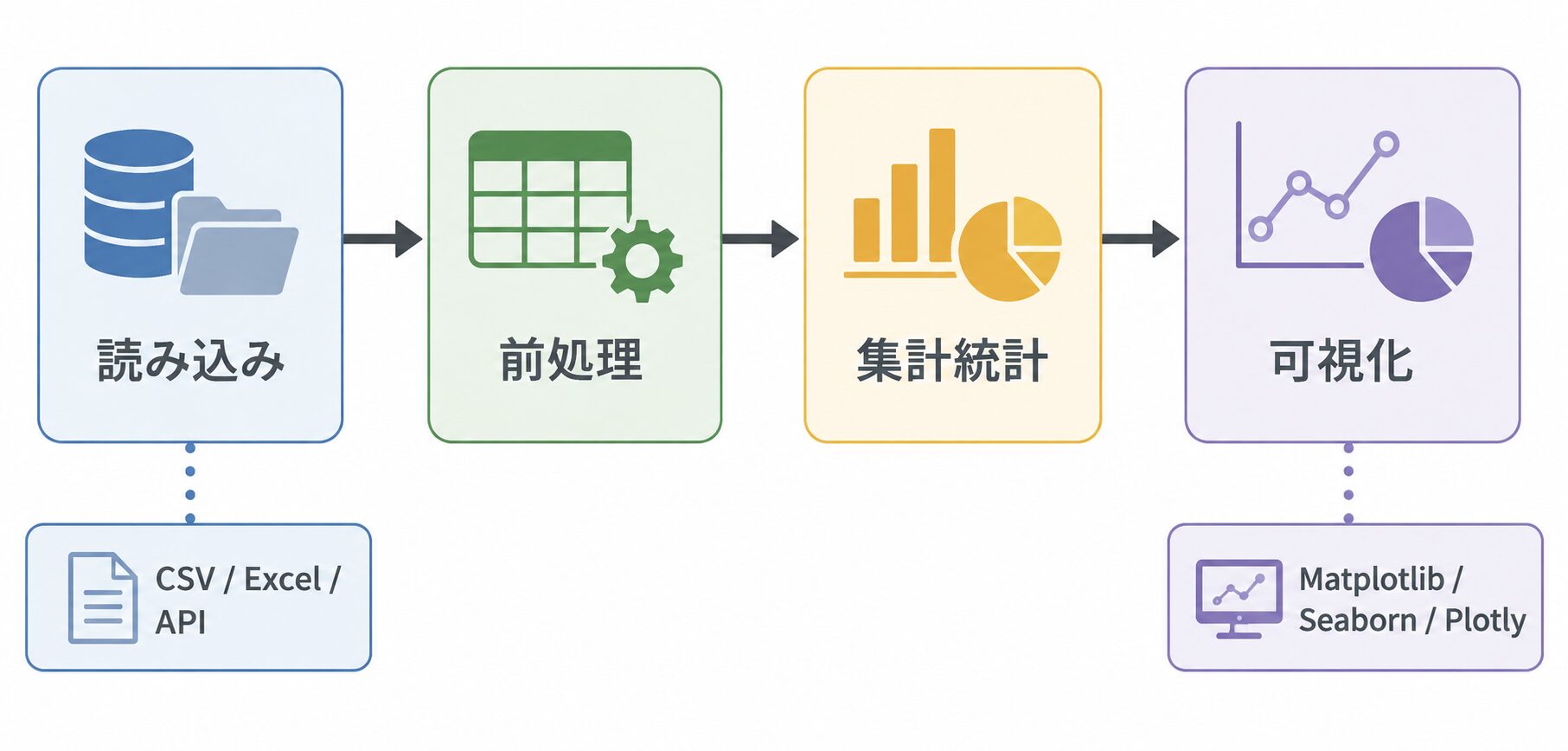
- データ分析の全体像(読み込み → 前処理 → 集計・統計 → 可視化の 4 工程)
- pandas でのデータ読み込みと、前処理の基本
- 相関などで変数間の関係を掴む集計・統計の考え方
- Matplotlib・Seaborn・Plotly の使い分けと、日本語フォントの対応
結論を先に述べると、データ分析は「データを読み込み、前処理で整え、集計・統計で傾向を掴み、可視化で伝える」という 4 工程に整理できます。可視化ライブラリは、静的なレポート向けか、Web で共有する対話的なグラフ向けかで選び分けるのが基本です。本記事ではこの流れと選定基準を俯瞰し、各工程の具体的な実装は関連記事へつなげていきます。
なお、データの取得や自動化(API からの取得、CSV 出力、定期実行)は別のテーマのため、関連記事『Python で業務を自動化する方法』で扱っています。本記事は、取得済みのデータ(CSV や DataFrame)を分析・可視化する工程に焦点を当てます。
データ分析の全体像: 4 工程の型
Python によるデータ分析は、次の 4 工程に分けて考えると見通しが良くなります。多くの分析作業は、この流れで進みます。
分析の起点は、データの読み込みです。CSV や Excel、あるいは API から取得した JSON を、pandas の DataFrame という表形式のデータ構造に取り込みます。ここで、文字コードや欠損値、データ型といった、後段に影響する要素を確認します。
読み込んだ生データは、そのままでは分析に使いにくいことがほとんどです。欠損値を埋めるか除く、数値であるべき列を数値型に変換する、不要な列を落とす、といった前処理を行います。分析の品質は、この前処理で大きく左右されます。
整えたデータから、平均や合計といった集計値や、変数間の関係を表す統計量を計算します。たとえば相関係数を見れば、2 つの数値がどの程度連動しているかを把握できます。この工程で、データが持つ傾向の仮説を立てます。
最後に、集計・統計の結果をグラフにして、傾向を視覚的に伝えます。数値の表では見えにくい分布の形や関係の強さも、グラフにすると把握しやすくなります。ここで、目的に合った可視化ライブラリを選ぶことが重要になります。
この 4 工程のうち、1 と 2 で土台を整え、3 で傾向を掴み、4 で伝える、という流れが基本です。以降、各工程の具体的な進め方と、可視化ライブラリの選び方を順に見ていきます。
データの読み込みと前処理(pandas)
データ分析の土台となるのが、pandas での読み込みと前処理です。ここを丁寧に行うことで、後段の集計や可視化が安定します。
データを読み込む
CSV を読み込むには read_csv を使います。日本語を含むファイルでは、文字コードの指定が重要です。UTF-8 以外(Shift-JIS/CP932 など)で保存されたファイルは、encoding を指定しないと読み込み時にエラーになります。
import pandas as pd
# UTF-8 のファイル
df = pd.read_csv("data.csv")
# CP932(Shift-JIS 系)のファイル
df = pd.read_csv("data_sjis.csv", encoding="cp932")読み込みでエンコーディングのエラーに遭遇した場合は、関連記事『Python の SyntaxError: Non-UTF-8 code starting with を解決』で原因と対処を解説しています。また、API から取得したデータを分析する場合の取得方法は、『Python で業務を自動化する方法』を参照してください。
欠損値を確認・処理する
実データには、値が入っていない欠損値(NaN)が含まれることがよくあります。まず、列ごとの欠損数を把握します。
# 列ごとの欠損値の数を確認する
print(df.isna().sum())欠損値の扱いは、行を削除するか、何らかの値で補完するかの 2 通りが基本です。削除には dropna()、補完には fillna() を使います。
# 欠損値を含む行を削除する
df_dropped = df.dropna()
# 欠損値を 0 で補完する
df_filled = df.fillna(0)
# 欠損値を列の平均値で補完する
df["価格"] = df["価格"].fillna(df["価格"].mean())前後の値で補完したい場合は、ffill()(直前の値)や bfill()(直後の値)を使います。なお、かつて使われていた fillna(method="ffill") という書き方は現在では非推奨のため、ffill()/bfill() を直接使う形が推奨されます。
df_ffill = df.ffill() # 直前の値で補完
df_bfill = df.bfill() # 直後の値で補完どの方法を選ぶかは、データの性質によります。欠損をそのままにすると集計や可視化で誤った結果につながるため、分析の目的に応じて適切に処理します。
データ型を整える
数値であるべき列が文字列として読み込まれていると、集計や可視化が正しく行えません。astype() で型を変換し、日付は pd.to_datetime() で日時型に変換します。日時型にしておくと、期間の計算や時系列の並べ替えが容易になります。
# 文字列を整数型に変換する
df["売上個数"] = df["売上個数"].astype(int)
# 文字列を日時型に変換する
df["日付"] = pd.to_datetime(df["日付"])重複の削除とメソッドチェーン
重複行は drop_duplicates() で除けます。前処理は、複数の操作をメソッドチェーンでつなげると、流れが追いやすく再利用しやすくなります。
df_clean = (
pd.read_csv("data.csv")
.drop_duplicates()
.fillna({"age": 0})
.assign(age=lambda x: x["age"].astype(int))
)集計と統計: 関係性を掴む
データが整ったら、集計や統計量で傾向を掴みます。
グループ集計
groupby を使うと、カテゴリごとに集計できます。たとえば、店舗ごとの売上合計や、カテゴリごとの平均値などを求められます。
# 店舗ごとの売上合計
summary = df.groupby("店舗")["売上"].sum()
# カテゴリごとの平均価格
mean_price = df.groupby("カテゴリ")["価格"].mean()相関で関係の強さを見る
2 つの数値がどの程度連動しているかは、相関係数で把握できます。DataFrame の corr() で、数値列どうしの相関を一括で計算できます。
# 数値列どうしの相関係数を計算する
correlation = df.corr(numeric_only=True)
print(correlation)ただし、相関の解釈には注意が必要です。相関は因果関係を意味しないこと、外れ値の影響を受けること、カテゴリ変数には別の指標が必要なことなど、踏まえるべき点があります。相関係数の計算から、p 値による有意性の確認、カテゴリ変数の扱い、解釈上の注意までは、専門の記事『Python で相関分析を行う手順』で詳しく解説しています。集計・統計で関係の仮説を掴んだら、次の工程の可視化で傾向を確認・共有します。
可視化ライブラリの選び方: Matplotlib・Seaborn・Plotly
Python の可視化ライブラリは複数あり、目的に合わないものを選ぶと手間が増えます。選定の基本は、静的な画像として出力したいのか、Web 上で操作できる対話的なグラフにしたいのか、という軸です。代表的な 3 つの特徴を整理します。
Matplotlib: すべての基盤となる静的グラフ
Matplotlib は、Python の可視化で最も歴史が長く、多くのライブラリの土台になっています。軸・色・フォント・配置といった要素を細かく制御でき、論文やレポート向けの静止画を作り込むのに適しています。低レベルで自由度が高い反面、凝ったグラフではコードが長くなりがちです。API データを Matplotlib でグラフ化する例は、関連記事『AniList API でデータを取得してグラフ化する手順』で扱っています。
Seaborn: 統計可視化を手軽に美しく
Seaborn は Matplotlib をベースにした高レベルなライブラリで、統計的な可視化に特化しています。美しいデフォルトデザインを備え、ヒートマップやバイオリン図といった複雑なグラフも少ない記述で作成できます。pandas の DataFrame との相性が良く、列名を指定するだけで描画できるため、データの分布や相関を素早く掴む探索的データ分析(EDA)に向いています。相関のヒートマップを Seaborn で描く例は、関連記事『Python で相関分析を行う手順』で詳しく解説しています。
Plotly: 対話的で共有しやすいグラフ
Plotly は JavaScript(Plotly.js)をベースにしており、ブラウザ上でズームやマウスオーバーでの値表示といった操作ができる、対話的なグラフを作成できます。見栄えがモダンで、Web での共有やダッシュボードの構築に向いています。対話的なガントチャートを Plotly で作る例は、関連記事『Plotly でガントチャートを作成する手順』で扱っています。
選定の目安
用途に応じた選び方を整理すると、次のようになります。
| 目的 | 向いているライブラリ |
|---|---|
| 細部までこだわった静止画・レポート | Matplotlib |
| 統計データの傾向を手軽に・美しく可視化(EDA) | Seaborn |
| Web で共有する対話的なグラフ・ダッシュボード | Plotly |
なお、Seaborn は内部で Matplotlib を使っているため、Seaborn で描いたグラフを Matplotlib で微調整する、といった組み合わせも可能です。まずは Seaborn や Plotly の高レベルな関数で簡単に描けないかを試し、細かい調整が必要なら Matplotlib を使う、という流れが効率的です。
日本語フォントの対応
Matplotlib や Seaborn は、初期設定のままでは日本語が豆腐(□)のように文字化けします。これは、既定のフォントが日本語に対応していないためです。対応方法はいくつかありますが、手軽なのは matplotlib-fontja を使う方法です。
matplotlib-fontja の利用
matplotlib-fontja は、インストールしてインポートするだけで Matplotlib を日本語表示に対応させるライブラリです。IPAex ゴシックフォントを利用します。
pip install matplotlib-fontjaimport matplotlib.pyplot as plt
import matplotlib_fontja # import するだけで日本語表示に対応
plt.plot([1, 2, 3, 4])
plt.xlabel("簡単なグラフ")
plt.show()パッケージ名はハイフン区切りの matplotlib-fontja、インポート名はアンダースコアの matplotlib_fontja である点に注意してください。
japanize-matplotlib との関係
従来は japanize-matplotlib が広く使われてきましたが、Python 3.12 で distutils が標準ライブラリから削除された影響で、環境によってインポート時にエラーが発生する問題がありました。matplotlib-fontja は、この問題に対応したフォークとして公開され、活発に保守されています。現行の環境では、matplotlib-fontja を使うのが安定した選択肢です。競合する解説記事には、いまだ japanize-matplotlib を前提としたものも見られるため、新しく書くコードでは matplotlib-fontja を選ぶとよいでしょう。
Seaborn と併用するときの注意
Seaborn を使う場合は、注意点があります。sns.set_theme() などでテーマを設定すると、フォント設定が Seaborn の既定で上書きされ、せっかくの日本語表示が無効になることがあります。この場合は、テーマにフォントを指定するか、上書き後に日本語化を再適用します。
import seaborn as sns
import matplotlib_fontja
# 方法 1: テーマにフォントを指定する
sns.set_theme(font="IPAexGothic")
# 方法 2: テーマ設定後に日本語化を再適用する
sns.set_theme()
matplotlib_fontja.japanize()この挙動は、各可視化スポークでも共通して効いてくるため、本 blog ではフォント方針を matplotlib-fontja に統一しています。
参考: matplotlib-fontja(PyPI)
“seabornの場合は、sns.set_theme(font=\”IPAexGothic\”)としてIPAexGothicを使用するよう設定することもできます。”
https://pypi.org/project/matplotlib-fontja/
まとめ
本記事では、Python でデータ分析を進めるための流れと、可視化ライブラリ選定の基準を整理しました。読み込み → 前処理 → 集計・統計 → 可視化という 4 工程を軸に、各工程の要点と、目的に応じたライブラリの選び方を解説しました。
- データ分析は読み込み・前処理・集計統計・可視化の 4 工程
- 読み込みでは文字コードと欠損・型の確認が起点
- 欠損補完は ffill/bfill を直接使う書き方が現行の推奨
- 関係性は相関で掴み、解釈の注意は相関分析記事へ
- 可視化は静的か対話的かでライブラリを選び分ける
- 静的は Matplotlib/Seaborn、対話的な共有は Plotly
- 日本語表示は保守が続く matplotlib-fontja を使う
各工程の具体的な実装は、相関分析・ガントチャート・AniList API の記事で詳しく解説しています。データの取得や定期実行については、関連記事『Python で業務を自動化する方法』を参照してください。本記事を地図として、目的に合った記事から分析を進めてください。
以上、最後までお読みいただきありがとうございました。

