

はじめに
Backlog は便利なプロジェクト管理ツールですが、毎日の進捗確認や未消化課題のリストアップなど、画面を操作して情報を集める作業を「面倒だな」と感じたことはありませんか?
Web ブラウザで行う操作の大部分は、Backlog API を使うことでプログラムから自動実行できます。 本記事では、Python を使って Backlog のデータを自在に操る第一歩として、課題情報の取得からレポート(CSV)作成までを自動化する手順を解説します。
- Backlog API を使うための事前準備(API キー、プロジェクト ID の確認方法)
- Python を使って Backlog から課題データを取得する基本コード
- 【実践】 「未完了」かつ「優先度:高」の課題だけを抽出し、CSV ファイルに出力する方法
事前準備:API キーとプロジェクト ID の確認
Python から Backlog を操作するためには、認証情報の「API キー」と、操作対象を指定する「プロジェクト ID」の2つが必要です。
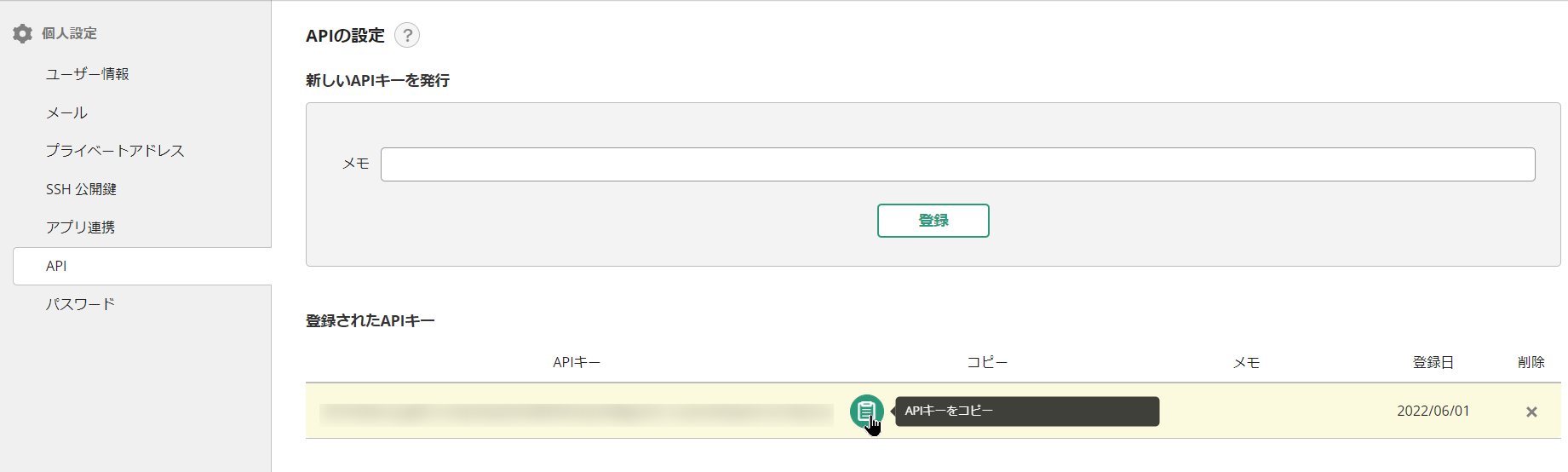
API キーの取得
API キーは、個人のアカウントに紐付くパスワードのようなものです。
- Backlog にログインし、画面右上のアイコンから [個人設定] を開きます。
- 左メニューの [API] をクリックします。
- メモ欄(例:
python_scriptなど)を入力し、[登録] ボタンをクリックします。
発行された長い文字列が API キーです。後ほどコードに貼り付けるため、コピーしておきましょう。
ショートカットURL: 以下の URL の
xxxxをあなたのスペース ID(ドメイン)に書き換えることで、直接設定画面にアクセスできます。https://xxxx.backlog.com/EditApiSettings.action
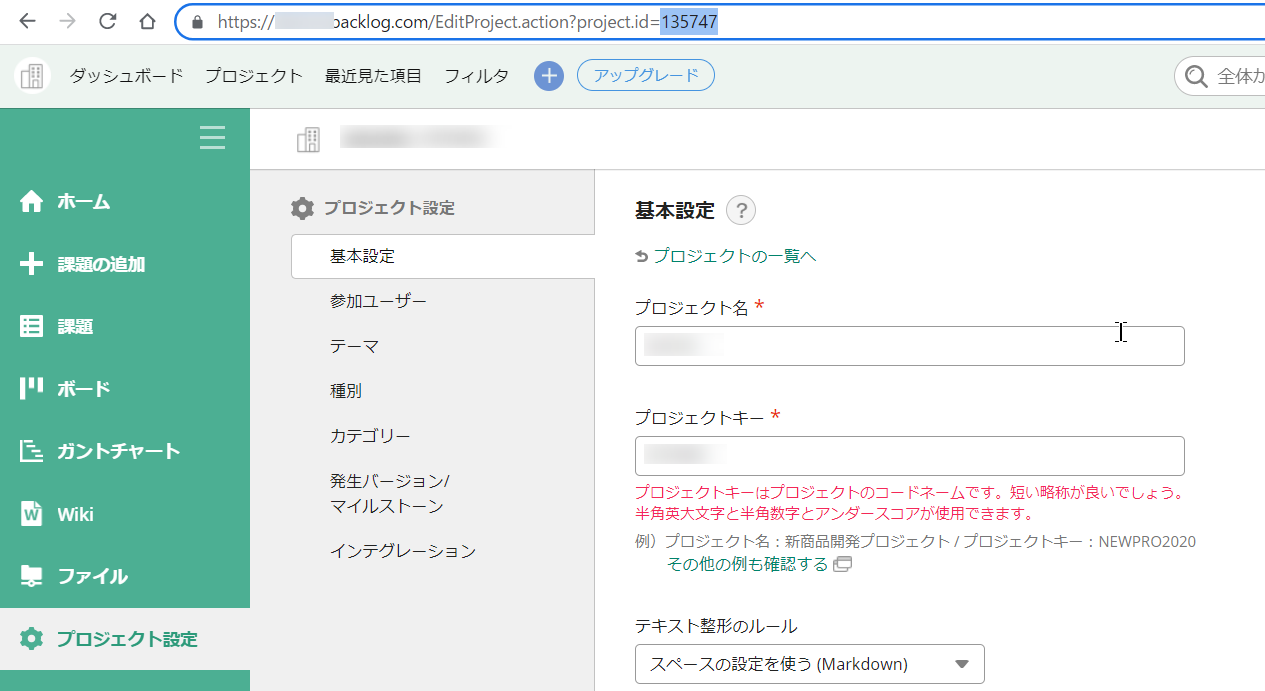
Project ID の確認
次に、操作対象となるプロジェクトの ID を確認します。
- 対象のプロジェクトを開き、左メニューの [プロジェクト設定] をクリックします。
- その画面を開いた状態で、ブラウザの アドレスバー(URL) を確認してください。
- URL の末尾にある
project.id=XXXXXXの数字部分が Project ID です。

API によっては「プロジェクトキー(例: PROJ)」でも動作しますが、今回は確実な「Project ID(数字)」を使用します。
課題一覧データを取得する(基本編)
ここからは実際のプログラミング作業に入ります。 API との通信には、Python の標準的なライブラリである requests を使用します。
Python環境とRequestsライブラリの準備
まだインストールしていない場合は、以下のコマンドでライブラリを追加してください。
pip install requests全件取得のサンプルコード
まずは、指定したプロジェクトの課題一覧をシンプルに取得し、画面に表示するスクリプトです。 以下のコードをコピーし、YOUR_API_KEY と YOUR_SPACE_ID(ドメイン部分)、PROJECT_ID を書き換えて実行してみてください。
import requests
import pprint
def main():
# 環境に合わせて書き換えてください
API_KEY = 'YOUR_API_KEY' # 取得したAPIキー
SPACE_ID = 'xxxxx' # スペースID (https://xxxxx.backlog.com の xxxxx部分)
PROJECT_ID = 12345 # 確認したプロジェクトID(数値)
# APIのエンドポイントとパラメータ設定
url = f'https://{SPACE_ID}.backlog.com/api/v2/issues'
payload = {
'apiKey': API_KEY,
'projectId[]': [PROJECT_ID], # 配列で指定する必要がある点に注意
}
try:
# APIリクエストを実行
response = requests.get(url, params=payload)
response.raise_for_status() # エラーがあれば例外を発生させる
# 結果をJSONとして取得し、表示
issues = response.json()
pprint.pprint(issues)
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")
if __name__ == '__main__':
main()実行結果(イメージ)
成功すると、以下のような JSON 形式(辞書型リスト)のデータが大量に出力されます。 これが Backlog が持っている「課題」の生データです。
[{'actualHours': None,
'assignee': {'id': 123456, 'name': '山田 太郎', ...},
'attachments': [],
'created': '2023-10-27T08:00:00Z',
'createdUser': {'id': 123456, ...},
'description': '課題の詳細内容です...',
'dueDate': '2023-11-30T00:00:00Z',
'estimatedHours': None,
'id': 1073892456,
'issueKey': 'PROJ-123',
'issueType': {'color': '#7ea800', 'id': 567890, 'name': 'タスク', ...},
'milestone': [],
'priority': {'id': 3, 'name': '中'},
'projectId': 12345,
'status': {'id': 1, 'name': '未対応'},
'summary': '定例会議の資料作成',
...(以下省略)...
}]このままでは情報量が多すぎて人間には読みづらいですね。 次のステップでは、ここから「本当に必要な情報」だけを抜き出して、見やすい CSV ファイルに変換します。
条件を絞り込んで CSV 出力する(応用編)
全件取得ができたら、次は「必要なデータだけ」を抽出してみましょう。 実務では「期限切れの課題」や「優先度が高いのに放置されている課題」をリストアップしたいケースがほとんどだからです。
「未完了」かつ「高優先度」の課題を抽出するロジック
Backlog API は、リクエスト時にパラメータ(条件)を渡すことで、サーバー側でデータを絞り込んで返してくれます。 今回は以下の条件を指定します。
- ステータス: 「完了(ID:4)」以外 → つまり未対応(1)、処理中(2)、処理済み(3)を指定
- 優先度: 「高(ID:2)」
実務で使える CSV 出力コード
以下のコードは、条件に合致する課題を取得し、Excel でそのまま開ける CSV ファイル(BOM 付き UTF-8)として保存します。
import csv
import requests
def main():
# -------------------------------------------------
# 設定エリア(ここを環境に合わせて書き換えてください)
# -------------------------------------------------
API_KEY = 'YOUR_API_KEY'
SPACE_ID = 'xxxxx' # スペースID
PROJECT_ID = 12345 # プロジェクトID
OUTPUT_FILE = 'high_priority_issues.csv'
# -------------------------------------------------
url = f'https://{SPACE_ID}.backlog.com/api/v2/issues'
# フィルタ条件の設定
payload = {
'apiKey': API_KEY,
'projectId[]': [PROJECT_ID],
'statusId[]': [1, 2, 3], # 1:未対応, 2:処理中, 3:処理済み (4:完了 は除外)
'priorityId[]': [2], # 2:高
'sort': 'dueDate', # 期限日でソート
'order': 'asc', # 昇順(期限が近い順)
'count': 100 # 一度に取得する件数(最大100)
}
try:
response = requests.get(url, params=payload)
response.raise_for_status()
issues = response.json()
if not issues:
print("条件に一致する課題はありませんでした。")
return
# CSV出力処理
# encoding='utf_8_sig' は Excel での文字化けを防ぐおまじないです
with open(OUTPUT_FILE, 'w', encoding='utf_8_sig', newline='') as f:
# ヘッダー(列名)の定義
fieldnames = ['課題キー', '件名', '担当者', 'ステータス', '期限日', '詳細URL']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
# データの書き込み
for issue in issues:
# 担当者が未設定の場合のエラー回避
assignee_name = issue['assignee']['name'] if issue['assignee'] else '(未設定)'
writer.writerow({
'課題キー': issue['issueKey'],
'件名': issue['summary'],
'担当者': assignee_name,
'ステータス': issue['status']['name'],
'期限日': issue['dueDate'] if issue['dueDate'] else '(指定なし)',
'詳細URL': f"https://{SPACE_ID}.backlog.com/view/{issue['issueKey']}"
})
print(f"完了! '{OUTPUT_FILE}' に {len(issues)} 件の課題を出力しました。")
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")
if __name__ == '__main__':
main()コードのポイント:
payloadで条件指定-
statusId[]やpriorityId[]をリスト形式で渡すことで、複数の条件を組み合わせて検索できます。 utf_8_sig-
Windows の Excel は標準の UTF-8 を開くと文字化けすることがありますが、
utf_8_sig(BOM付き)を指定することでこれを回避しています。これで Shift-JIS 変換の手間は不要です。
まとめ
本記事では、Python を使って Backlog API を操作し、特定の条件の課題を抽出して CSV 化する方法を解説しました。
- API キーとプロジェクト ID があれば、誰でも簡単にデータにアクセスできる。
- Requests ライブラリ を使えば、わずか数行で Backlog のデータを取得できる。
- パラメータ を活用することで、「未完了」「高優先度」などのフィルタリングも自動化できる。
以上、最後までお読みいただきありがとうございました。

