

はじめに
ストレージ管理者にとって、「ファイルサーバーが遅い」「レスポンスが悪い」という問い合わせへの初動は重要です。NetApp ONTAP の現状を素早く把握する手段の 1 つが sysstat コマンドです。実行すると、現在のアクセス量(IOPS)、CPU やディスクの負荷、書き込み処理(CP)の状態などを 1 秒単位で確認できます。
本記事では、出力項目が多く読み取りにくい sysstat の見方を、ボトルネック特定の観点から解説します。
- sysstat コマンドの ONTAP 9 での実行方法とオプション
- 出力結果(IOPS・CPU・Disk Util・Cache Hit)の読み方と目安
- パフォーマンス低下の要因となる CP(Consistency Point)の見方
結論として、ONTAP 9 の sysstat はノードシェルのコマンドで、node run を介して実行します。性能の全体像は CPU・Disk Util・Cache Hit・CP タイプの 4 点で把握でき、書き込みレイテンシに直結するのは CP タイプの B / b です。 ノード単位の傾向把握には sysstat が手軽ですが、ワークロード単位での原因特定には qos statistics などの併用が向きます。クラスター運用全体の位置づけは、関連記事『NetApp ONTAP 運用の要点|安定稼働と障害対応のポイント』も参考になります。
sysstat コマンドとは
sysstat は、ONTAP に標準実装されている基本的な性能統計ツールです。外部ツールを導入せず、SSH やコンソールからコマンドを実行するだけで、ストレージコントローラーの稼働状況をほぼリアルタイムに表示します。
ただし ONTAP 9(クラスター環境)では、sysstat はノードシェル(ノード内部のシェル)のコマンドです。clustershell から直接は実行できないため、後述のとおり node run を介して実行します。クラスター全体やワークロード単位での分析には、statistics show-periodic や qos statistics といった clustershell のコマンドが用意されています。
sysstat で確認できる主な項目
sysstat では、ストレージの処理に関わる次の 3 つの要素を 1 画面で確認できます。
- プロトコル別の統計
-
NFS、CIFS(SMB)、iSCSI、FCP などのプロトコルごとに、毎秒どれくらいのアクセス(IOPS)が発生しているか。
- スループット
-
ネットワーク(Net)やディスク(Disk)に対して、毎秒何キロバイト(kB/s)のデータ転送が発生しているか。
- ハードウェアリソース
-
CPU 使用率、ディスクの利用率(Disk Util)、NVRAM からディスクへの書き込み処理(CP)の状態
実行方法とオプション(-x、-m)
トラブルシューティングでは、より詳細な情報を得るためにオプションを組み合わせて実行するのが一般的です。前述のとおり、ONTAP 9 では node run を介してノードシェルの sysstat を呼び出します。
詳細モードでの実行(sysstat -x)
最もよく使われるのが -x オプションです。
# ONTAP 9(クラスター環境)での実行
node run -node <ノード名> -command sysstat -x 1- -x(Extended): 拡張表示モードです。デフォルト表示に加えて、CP(Consistency Point)やディスクの統計など、ボトルネック特定に必要な情報が表示されます。
- 1(Interval): 更新間隔(秒)です。1 を指定すると、1 秒ごとの変動を確認できます。
終了するには Ctrl + C を押します。デフォルト表示では情報が丸められるため、原因を深掘りするには -x を付けた実行が向いています。
マルチプロセッサーの確認(sysstat -m / -M)
CPU 負荷が高いと疑われる場合に使います。
# CPU ごとの負荷を確認
node run -node <ノード名> -command sysstat -m 1通常の sysstat は全コアの平均値を表示しますが、-m を付けると CPU ごとの値を確認でき、特定のコアだけが高負荷になっていないかを把握できます。さらに細かい処理ドメイン別の内訳を見たい場合は -M を使います。ネットワーク割り込みなど、特定の処理が 1 つのコアに集中してボトルネックになるケースの発見に役立ちます。
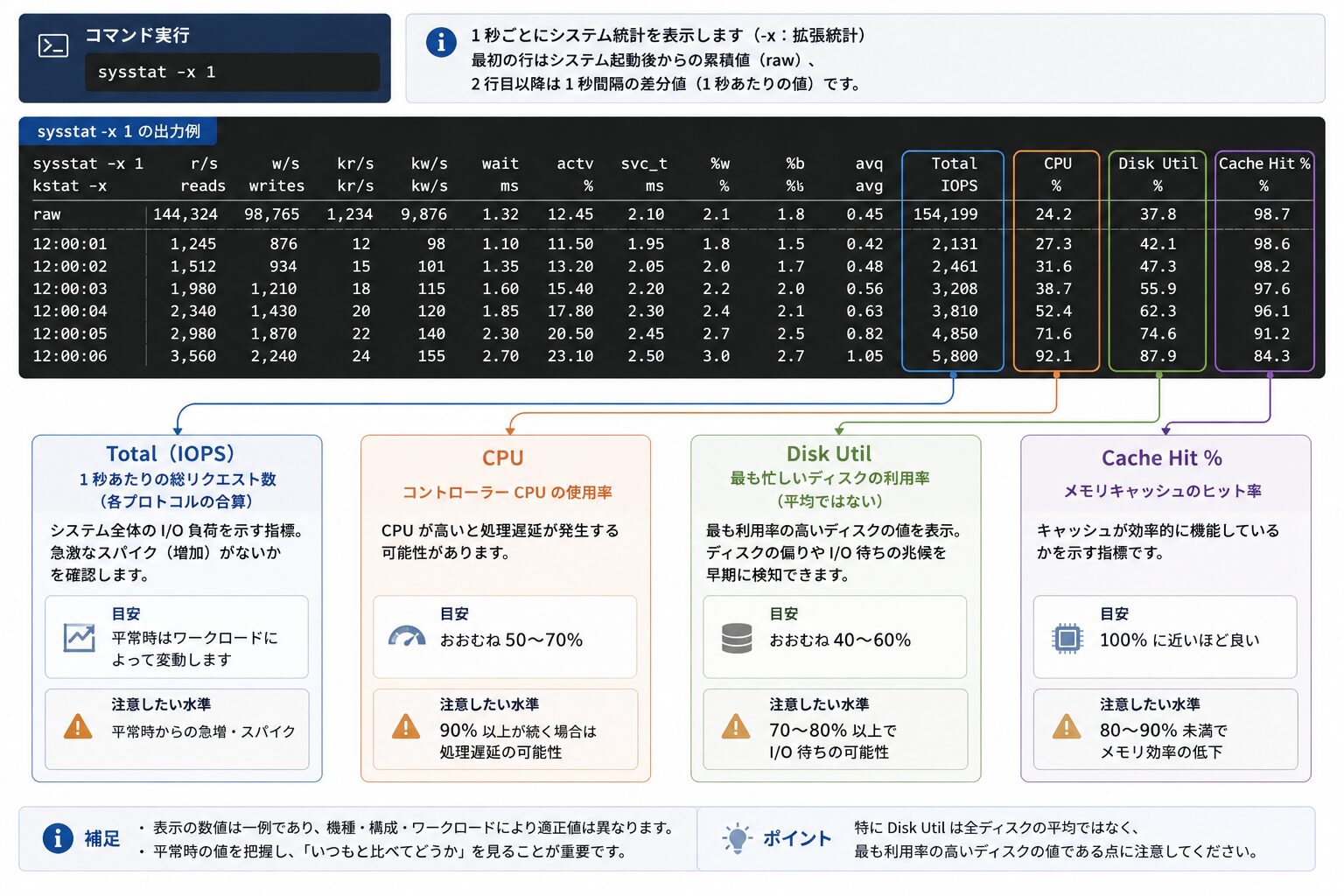
出力結果の見方(重要項目)
実行すると多くの数値が表示されますが、システムの状態を判断する目安となるのは次の 4 つの指標です。なお以下の目安は経験則的なもので、NetApp が定める固定の基準値ではありません。ワークロードや機種によって適正値は変わるため、平常時の値を把握した上での相対比較が前提になります。
| 項目 | 内容 | 平常時の目安 | 注意したい水準 |
|---|---|---|---|
| Total(IOPS) | 1 秒あたりの総リクエスト数(各プロトコルの合算) | システムによる | 急激なスパイクの有無を確認 |
| CPU | コントローラー CPU の使用率 | おおむね 50〜70% | 90% 以上が続く場合は処理遅延の可能性 |
| Disk Util | 最も忙しいディスクの利用率(平均ではない) | おおむね 40〜60% | 70〜80% 以上で I/O 待ちの可能性 |
| Cache Hit | メモリキャッシュのヒット率 | 100% に近いほど良い | 80〜90% 未満でメモリ効率の低下 |
特に Disk Util は、全ディスクの平均ではなく最も利用率の高いディスクの値を示すため、平均では見えないディスクの偏りの検知に有効です。
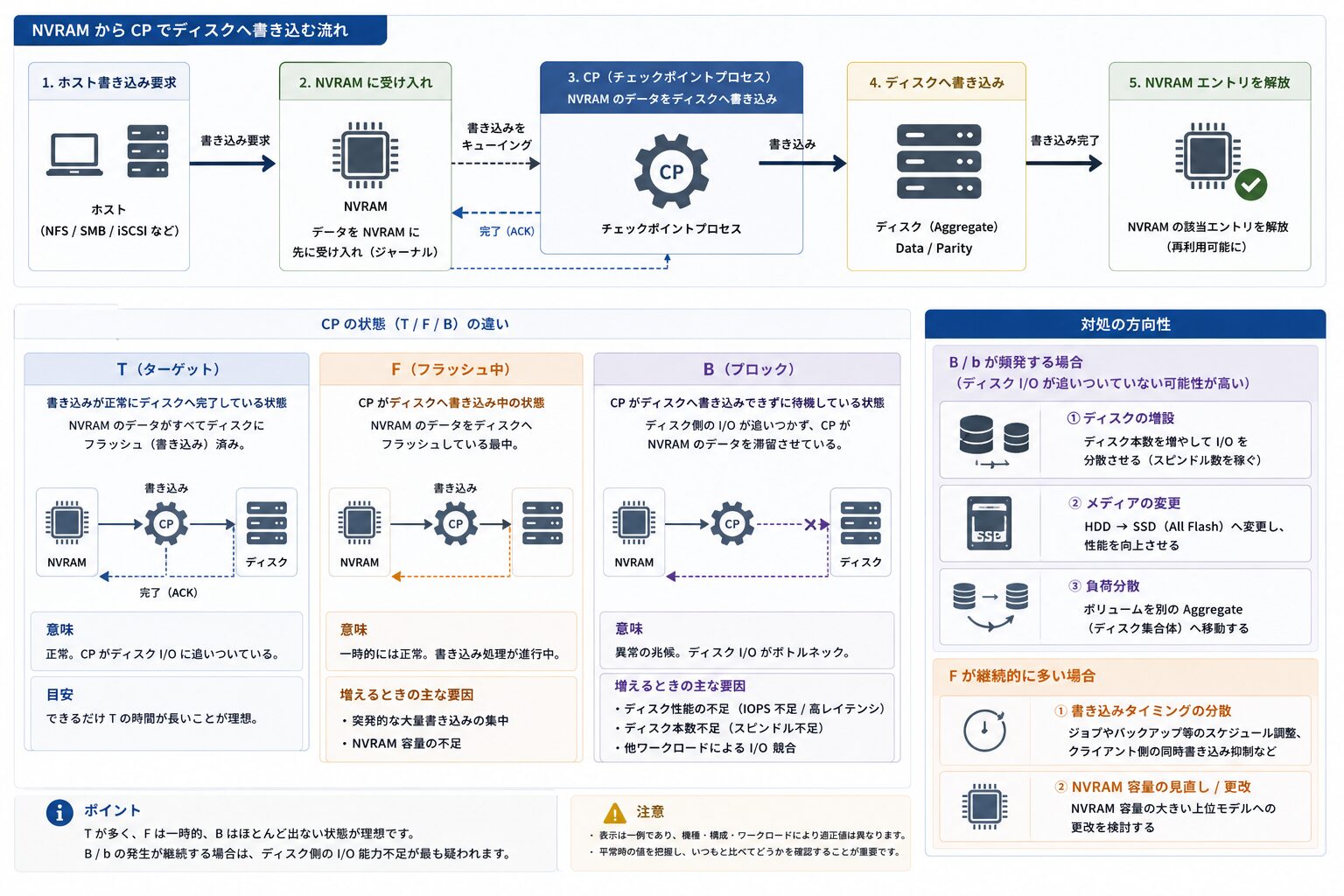
ボトルネックの要因となる CP(Consistency Point)の見方
sysstat -x の出力にある CP ty(CP タイプ)の列には、ディスクへの書き込み処理の状態が表示されます。ここを読み解くと、書き込み系のボトルネックの有無を判断できます。
CP とは
ONTAP は書き込み性能を高めるため、サーバーからの書き込みデータを一旦 NVRAM(不揮発性メモリ)に受け取り、その時点でクライアントへ書き込み完了を返します。その後、NVRAM に溜まったデータをまとめてディスク(HDD / SSD)へ書き込みます。この「NVRAM からディスクへデータをフラッシュする処理」が CP(Consistency Point)です。貯水ダムにたとえると、NVRAM が一時的に水を貯めるダム、CP が定期的な放流に相当します。なお ONTAP 9 では Per-Aggregate CP が導入され、CP 情報の表示が以前から変わっている点に留意してください。
CP タイプの見方
CP ty の列には、CP が発生した理由を示す文字が表示されます。主なものは次のとおりです。
- T(Timer)
-
他の契機がない場合に約 10 秒ごとに発生する、通常の CP です。
- F(NVLog Full)
-
NVRAM の片側が満杯になり、フラッシュされた状態です。書き込み量が多いときに発生しますが、もう片側で受け付けを継続するため、ただちに切迫した状態を示すものではありません。
- B(Back-to-back)
-
前の CP が完了する前に次の CP が必要になっている状態で、書き込みにシステムが追いついていないことを示します。
- b(deferred Back-to-back)
-
B がさらに悪化した状態です。
書き込みレイテンシに影響するのは B と b のタイプです。F が時々表示されること自体は珍しくなく、継続的に B / b が現れる場合に書き込み系のボトルネックを疑います。
参考: What are the different Consistency Point types and how are they measured(NetApp KB)
“Only CP’s of type B or b will affect write latency”
(書き込みレイテンシに影響するのは B または b タイプの CP のみ)
https://kb.netapp.com/on-prem/ontap/Perf/Perf-KBs/What_are_the_different_Consistency_Point_types_and_how_are_they_measured
対処の方向性
B / b が頻発する場合は、ディスク側の I/O が追いついていない可能性が高いため、次の対処を検討します。
- ディスクの増設
-
本数を増やして I/O を分散させる(スピンドル数を稼ぐ)。
- メディアの変更
-
HDD から SSD(All Flash)へ変更する。
- 負荷分散
-
ボリュームを別の Aggregate(ディスク集合体)へ移動する。
F が継続的に多い場合は、突発的な大量書き込みの集中や NVRAM 容量の不足が背景にあることがあり、書き込みタイミングの分散や、NVRAM 容量の大きい上位モデルへの更改を検討します。
よくあるボトルネックの兆候パターン
sysstat の数値は、単体ではなく組み合わせて見ることで原因が見えてきます。現場で多い 3 つのパターンを示します。
パターン A: CPU ボトルネック
- 兆候
-
CPU が 90〜100% で高止まり。Disk Util は低め。CP に B / b は出ていない(F が時折出る程度)。
- 状況
-
WAFL の処理が追いついていません。重複排除や圧縮などの高負荷処理、またはさばける IOPS の限界を超えている状態です。
- 対処
-
高負荷処理をオフピークへ移動する。上位モデルのコントローラーへの更改を検討する。
パターン B: ディスクボトルネック
- 兆候
-
Disk Util が 70〜80% 以上で断続的に継続。CP ty に B / b が頻発。Cache Hit が低下していることが多い。
- 状況
-
NVRAM からディスクへの書き込みが間に合わず、ディスクが回り続けている状態です。
- 対処
-
ディスクの増設で負荷を分散する。Flash Cache や SSD の導入で I/O 処理能力を底上げする。
パターン C: ヘッドルーム不足(特定プロトコルの遅延)
- 兆候
-
CPU・Disk Util はともに低い。FCP や iSCSI 接続のサーバーだけタイムアウトや遅延が発生。sysstat -m で特定コアだけが高負荷になっていることがある。
- 状況
-
平均値には余裕があっても、特定の処理キューが詰まっていたり、ネットワーク経路でパケットロスが発生している可能性があります。
- 対処
-
sysstat -m で特定コアの偏りを確認する。ネットワーク統計(ifstat など)でインターフェースのエラーを確認する。
sysstat と現行コマンドの使い分け
sysstat はノード単位の集計を手早く確認できますが、どのボリュームやホストが原因かまでは特定できません。原因の絞り込みやクラスター横断の把握には、clustershell の統計コマンドを併用します。
| コマンド | 実行場所 | 主な用途 |
|---|---|---|
| sysstat | node run(ノードシェル) | ノード単位の全体傾向の素早い把握 |
| statistics show-periodic | clustershell | ノードを指定したリアルタイムな統計 |
| qos statistics | clustershell | ボリューム・ワークロード単位の原因特定 |
| statit | node run(ノードシェル) | ディスクや WAFL の詳細な統計の深掘り |
(ONTAP 9 の性能監視に使えるコマンドは、NetApp KB「What commands are useful to monitor performance in ONTAP 9」も参考になります: https://kb.netapp.com/on-prem/ontap/Perf/Perf-KBs/What_commands_are_useful_to_monitor_the_performance_in_ONTAP_9 )
アップグレード作業後の性能確認の流れは、関連記事『NetApp ONTAP バージョンアップの手順|ANDU と手動コマンドの使い分け』も参考になります。
まとめ
本記事では、NetApp ONTAP の性能分析の基本である sysstat コマンドの見方を、ONTAP 9 での実行方法とボトルネック特定の観点から解説しました。全体の傾向は sysstat で素早くつかめますが、高負荷の原因となるボリュームやホストの特定には qos statistics や statit を併用します。要点を以下にまとめます。
- ONTAP 9 の sysstat はノードシェルのコマンドで node run 経由で実行
- 状態判断の目安は CPU・Disk Util・Cache Hit・CP タイプの 4 点
- Disk Util は最も忙しいディスクの利用率で平均ではない
- 書き込みレイテンシに直結する危険サインは CP タイプの B / b
- 兆候は CPU・ディスク・ヘッドルームの 3 パターンで切り分け
- ノード単位の傾向把握に向くが原因特定は qos statistics や statit を併用
- 閾値は固定基準ではなく平常時との相対比較が前提
以上、最後までお読みいただきありがとうございました。

