はじめに
「データ分析」と聞くと、売上予測やマーケティングなど、ビジネスの現場で使われるものだと思っていませんか? 実は、データ分析は私たちの個人的な悩みや、重要な意思決定においても、強力なツールになります。
例えば、長く付き合う病気を患った場合、「この治療方法は本当に自分に合っているのだろうか?」「どの数値が悪化すると体調が崩れるのか?」といった不安を感じることがあるかもしれません。そんな時、自分のデータを分析することで、感覚だけでなく客観的な数値に基づいた判断ができるようになります。
本記事では、そんな実用的な「相関分析」について、Python を使った実践的な手法を解説します。
- 相関分析と相関係数の基礎知識
- Python(Pandas/Seaborn)を使った算出と可視化のコード
- 実践:血液検査データから「治療の効果」を読み解いてみる
相関分析とは?
相関分析とは、2つのデータの間にある「関係性の強さ(連動性)」を計算し、数値化する分析手法のことです。 「片方の数値が変化したとき、もう片方の数値はどう動くのか?」を統計的に明らかにします。
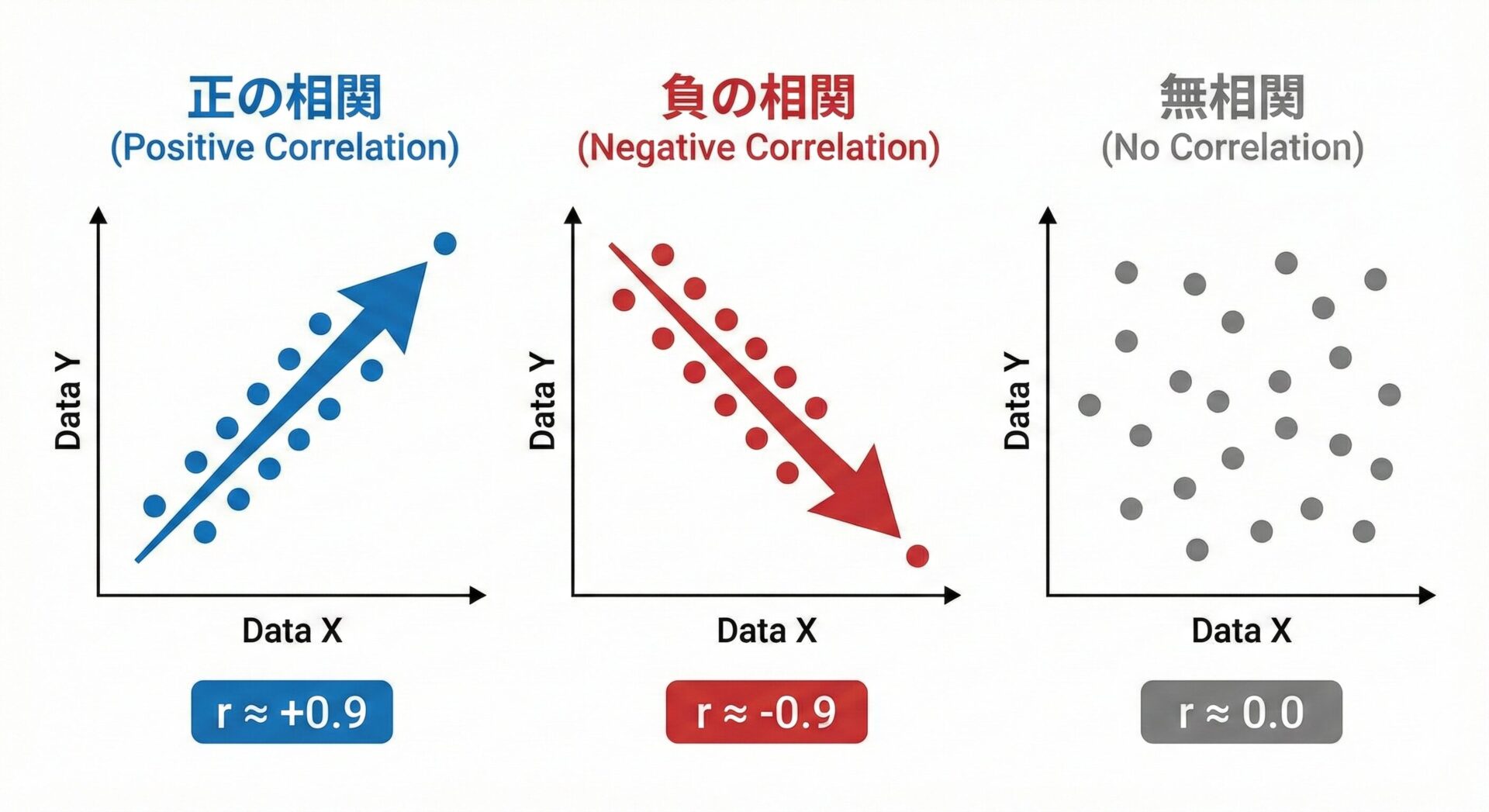
この関係性の強さを表す数値を 「相関係数(Correlation Coefficient)」 と呼び、通常は r という記号で表されます。 この数値は必ず -1 から 1 の範囲に収まり、以下のように読み取ります。
相関係数の見方
1.0(完全な正の相関)-
- 片方の数値が増えれば、もう片方も必ず増える関係(正比例)
- (例:身長と体重、気温とビールの売上など)
-1.0(完全な負の相関)-
- 片方の数値が増えれば、もう片方は必ず減る関係(反比例)
- (例:暖房の設定温度と電気代、運動量と体脂肪率など)
0(無相関)-
- 片方の数値が変化しても、もう片方には影響しない(バラバラな)関係。
- (例:身長とサイコロの出目など)
【注意】相関関係 ≠ 因果関係(擬似相関)
データ分析をする上で、一つだけ絶対に注意すべき点があります。 それは、「相関関係があるからといって、必ずしも因果関係があるとは限らない」ということです。
例えば、「アイスクリームの売上」と「水難事故の件数」には強い正の相関があります(アイスが売れる日は事故も増える)しかし、「アイスを食べたから事故が起きた(因果関係)」わけではありませんよね? これは、両方の裏に「気温が高い(夏である)」という別の要因が隠れているためです。

このように、見かけ上の関係性が出てしまうことを 「擬似相関(ぎじそうかん)」 と呼びます。 分析結果を見る際は、「本当に A が B の原因なのか?」を冷静に考える視点を持つことが大切です。
Python で相関分析を行う準備
それでは、実際に Python を使って分析を始めていきましょう。 まずは必要なライブラリのインストールと、今回分析に使用するデータの準備を行います。
今回は、データ分析における「三種の神器」とも言える以下のライブラリを使用します。 また、グラフ内で日本語(「治療薬 A」など)を表示するために、japanize-matplotlib も併せてインストールします。
- Pandas: データの読み込みや加工(Excel のような操作)を行う。
- Matplotlib: グラフを描画する基本ライブラリ
- Seaborn: Matplotlib をベースに、より美しく高度な統計グラフ(ヒートマップなど)を簡単に描くためのライブラリ
- japanize-matplotlib: グラフの日本語文字化けを防ぐライブラリ
インストールコマンド: ターミナル(コマンドプロンプト)で以下を実行してください。
pip install pandas matplotlib seaborn japanize-matplotlib今回は例として、ある期間の血液検査の結果をまとめた sample.csv を使用します。 (※ Excel で作成し、「CSV (コンマ区切り)」形式で保存したものを想定しています)
▼ sample.csv の中身
日付,WBC,HGB,PLT,T-P,ALB,CRP,治療
2020/10/13,7.4,11.8,348,7,4,2.81,アザニン
2020/10/19,5,11.3,418,6.9,3.7,3.5,レミケード
2021/12/3,6.7,12.3,239,7.5,4.3,0.17,レミケード&漢方
...(以下続く)▼ 各項目の意味
このデータには、一般的な血液検査の項目が含まれています。特に今回の分析で注目するのは CRP と ALB です。
| 項目名 | 正式名称 | 意味・役割 |
| WBC | 白血球数 | 体の防御反応。細菌感染や炎症で増加します。 |
| HGB | ヘモグロビン | 貧血の指標。低いと貧血状態です。 |
| PLT | 血小板数 | 止血作用。炎症が強いと増加する傾向があります。 |
| T-P | 総蛋白 | 血液中のタンパク質の総量 |
| ALB | アルブミン | 【重要】栄養状態の指標。炎症が長く続くと数値が下がります(栄養失調) |
| CRP | C反応性蛋白 | 【重要】炎症反応の指標。体内で炎症が起きていると数値が上がります。 |
| 治療 | (カテゴリ) | その時期に使用していた治療薬等の名称(アザニン, レミケード, 漢方など) |
このデータを使って、「CRP(炎症)が高いとき、他の数値はどう動くのか?」「どの治療薬のときに数値が良いのか?」を分析していきます。
相関係数の算出とヒートマップ作成
それでは、以下の手順でプログラムを作成します。 このコードは、読み込んだデータから自動的に数値項目を抽出し、それぞれの相関関係を計算してヒートマップとして表示します。
まずは pandas ライブラリを使って CSV ファイルを読み込みます。 今回のデータには日本語が含まれているため、文字化けを防ぐための設定(encoding)を追加しています。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語表示用
# データの読み込み
# index_col="日付": 1列目の「日付」をデータのインデックス(行ラベル)として扱います
# encoding="utf-8_sig": 日本語を含むCSVを読み込む際の文字化け対策です
df = pd.read_csv("sample.csv", index_col="日付", encoding="utf-8_sig")pd.read_csv("ファイル名"): CSV ファイルを読み込んで、データフレーム(表形式のデータ)に変換します。encoding="utf-8_sig": 日本語(特に Windows 環境で作成された CSV)を読み込む際、ここを指定しないとエラーが出たり文字化けしたりすることがあります。index_col="日付": これを指定しないと、「日付」もただの数値や文字として分析対象になってしまいます。日付を行のラベル(インデックス)に指定することで、純粋な検査数値だけを分析対象にできます。
読み込んだデータフレームに対して、相関係数を計算します。
# 相関係数の算出
# numeric_only=True: 文字列(治療薬名など)を除外し、数値列だけで計算します
df_corr = df.corr(numeric_only=True)df.corr(): データフレーム内の各列の組み合わせについて、相関係数(-1 ~ 1)を一括で計算します。numeric_only=True: 今回のデータには「治療薬」という文字列の列が含まれています。これを含めると計算エラーになる場合があるため、数値の列だけを計算対象にするよう指定します。
計算された数値(df_corr)を、seaborn を使って色分けされた図にします。
# グラフのサイズ設定
plt.figure(figsize=(10, 8))
# ヒートマップの作成
# annot=True: マスの中に数値を表示
# fmt='.2f': 数値を小数点第2位まで表示
# cmap='coolwarm': 色使い(青=負、赤=正)を指定
sns.heatmap(df_corr, annot=True, fmt='.2f', cmap='coolwarm', square=True)
# 表示
plt.show()sns.heatmap(): 数値の大小を色の濃淡で表すグラフを作成します。cmap='coolwarm': 相関分析では、「正の相関(赤)」 と 「負の相関(青)」 が直感的にわかるこの配色設定(coolwarm)がおすすめです。元のコードにあったBluesだと、負の相関が見えづらくなるため変更しています。
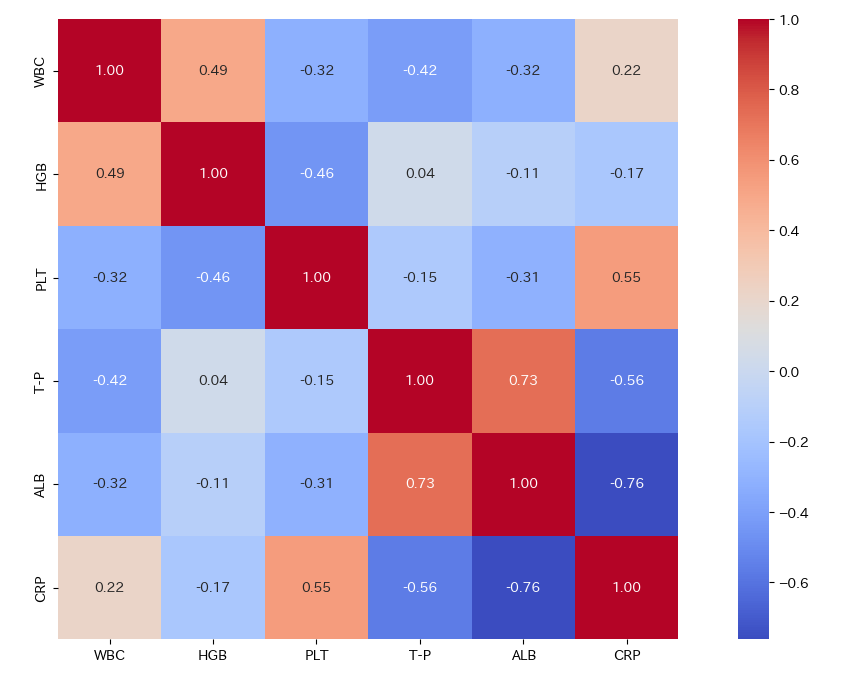
上記のコードを実行すると、以下のようなヒートマップが表示されます。
このヒートマップにより、どの項目同士が強く関係しているかが一目瞭然になります。 特に、赤いマス(正の相関) と 青いマス(負の相関) に注目してください。色が濃いほど、その関係性が強いことを意味します。
散布図行列(Pairplot)での詳細分析
数値(相関係数)を確認したら、次は必ず「グラフの形(散布図)」を目で見て確認しましょう。 Seaborn の pairplot を使うと、データの全ての組み合わせの散布図を一度に描画できます。
さらに、引数 hue(ヒュー)を指定することで、「治療」列の内容ごとに色分け して表示することが可能です。これが分析において非常に強力な武器になります。
# 散布図行列の作成
# hue="治療": CSVの「治療」列の種類(アザニン, レミケード, 漢方...)ごとに点を色分けする
# height=2.5: 1つのグラフのサイズ調整
sns.pairplot(df, hue="治療", height=2.5)
# 表示
plt.show()hue="治療": ここには CSV の列名を正確に指定 します。これにより、ただの黒い点の集まりだったグラフが、「アザニン(青)」「レミケード(橙)」「レミケード&漢方(緑)」 のように色分けされます。- これにより、「どの治療を行っている時に、数値が良くなっているか(クラスタができているか)」を一目で把握できます。
実行結果と分析のポイント
上記のコードを実行すると、以下のような散布図行列が表示されます。
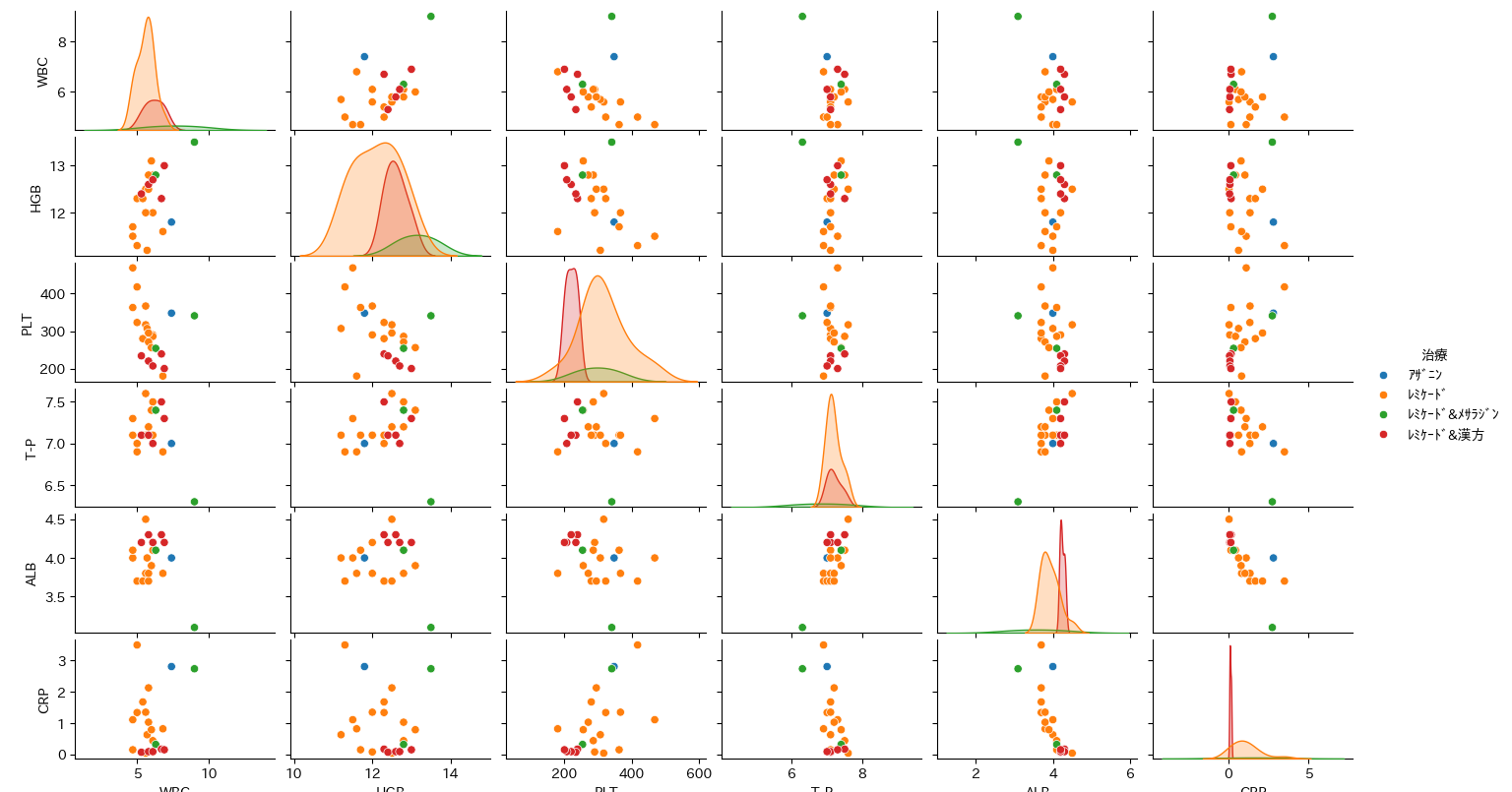
このグラフを見ると、以下のことが読み取れるようになります。
- 対角線(ヒストグラム)
-
- データの分布(山なり)が見えます。「レミケード&漢方」のグループの山が、CRP(炎症)の低い位置にあれば、その治療が炎症を抑えている可能性が高いとわかります。

CRP(炎症反応)の分布を見ると、オレンジ色(レミケード単体)は山がなだらかで数値にバラつきがあるのに対し、赤色(併用)は「0」付近に鋭いピークを作っています。これは、炎症が常に低いレベルでコントロールできていることを意味します。
- 散布図(点の集まり)
-
- 「レミケード & 漢方」 の点(クラスタ)が、「CRP が低く、ALB が高い」 という理想的なエリア(グラフの端っこ)に固まっているかを確認します。
- 数値上の相関だけでなく、「その治療法が明確に良い結果を出している」 という視覚的な証拠になります。
下から2行目・一番右のグラフを見てください。 赤色の点は、グラフの「左上(炎症が低く、栄養状態が良い)」という理想的なエリアに密集しています。 一方で、他の治療期間は点が散らばっており、調子の波が激しかったことがデータとして視覚化されました。
数値(相関係数)で「全体的な傾向」をつかみ、グラフ(散布図)で「治療法ごとの違い」を見つける。この2段階の分析こそが、データから真実を見つけ出す鍵となります。
【分析結果】データから見えた治療の道筋
今回、Python で作成した「ヒートマップ」と「散布図行列」から、治療方針を決定づけるための重要なヒントが得られました。 具体的な分析結果として、以下の2点が読み取れます。
ヒートマップを見ると、「CRP(炎症反応)」と「ALB(栄養状態)」の間に -0.95 という非常に強い負の相関 があることが確認できました。
- データが語ること
-
「炎症(CRP)が高まると、それに連動して栄養状態(ALB)が悪化する」という身体のメカニズムが、数値として明確に可視化されました。
- 気づき
-
逆に言えば、「炎症さえコントロールできれば、栄養状態も改善する可能性が高い」という仮説が立ちます。
次に、pairplot(散布図行列)で「治療薬」ごとのデータの分布を確認したところ、明確な違いが見つかりました。
- その他の治療期間(オレンジ・青・緑)
-
データが上下左右に散らばっており、数値が安定していないことがわかります。特にオレンジ色(レミケード単体)のヒストグラムを見ると、山が低く裾野が広がっており、調子の波が大きかったことが視覚的に確認できます。
- レミケード & 漢方の期間(赤色)
-
データが「CRP が低く、ALB が高い」という理想的な領域(左上)に密集しています。ヒストグラムも鋭い山を描いており、「ほぼ全ての日で炎症がゼロ付近に抑え込まれている」という圧倒的な安定感が浮き彫りになりました。
この結果から、「レミケードと漢方を併用している期間は、客観的に見ても病状が最も良く、かつ安定している」という事実が証明されました。
医師との対話に「データ」を持ち込む
通常、体調の変化は「なんとなく調子が良い・悪い」という主観的な感覚で語られがちです。しかし、このようにデータを可視化することで、医師とも客観的な事実に基づいた対話が可能になります。
「漢方併用の期間(赤色)は数値の相関関係が良好で安定しているため、この方針を継続したい」
そう相談するための根拠として、このデータ分析は非常に強力な材料となります。迷いが生じやすい長期的な治療において、データは進むべき道を照らすコンパスのような役割を果たしてくれます。
まとめ
本記事では、Python を使った相関分析の基礎から、実際の医療データを可視化して治療の効果を検証する手順までを紹介しました。
- Python での可視化は簡単
-
df.corr()やsns.pairplot()といった数行のコードを書くだけで、Excelの表だけでは見えない「データの傾向」を一瞬で可視化できます。 - 客観的な判断材料になる
-
健康管理やライフスタイルの見直しなど、個人の悩みに対してもデータ分析は有効です。感覚だけでなく「数値」を見ることで、より納得感のある意思決定ができるようになります。
以上、最後までお読みいただきありがとうございました。