

はじめに
サーバー単体の障害は、そのままサービス停止につながります。ハードウェアや OS の障害を完全には避けられない以上、稼働系がダウンした際に自動で待機系へ切り替え、サービスを継続させる仕組みが必要になります。それが HA(High Availability: 高可用性)クラスタです。
本記事では、Linux 環境でのクラスタ構築の定番である Pacemaker と Corosync を組み合わせ、RHEL 9 / AlmaLinux 9 で Web サーバーを冗長化する手順を解説します。
- Pacemaker と Corosync の役割分担、Heartbeat から移行した背景
- RHEL 9 / AlmaLinux 9 での
pcsコマンドによる構築手順 - VIP(仮想 IP)・Apache・共有ファイルシステムを連動させるリソースグループの作り方
- フェイルオーバーの動作確認方法と、pcs 0.11 で変わった
resource moveの挙動
現行の RHEL 9 / AlmaLinux 9 では、Pacemaker + Corosync が標準構成です。pcs コマンドを使うことで、設定ファイルを直接編集せずに構築・運用できます。なお本番環境では、スプリットブレインによるデータ破損を防ぐため STONITH(フェンシング)を設定しておくことが推奨されます。
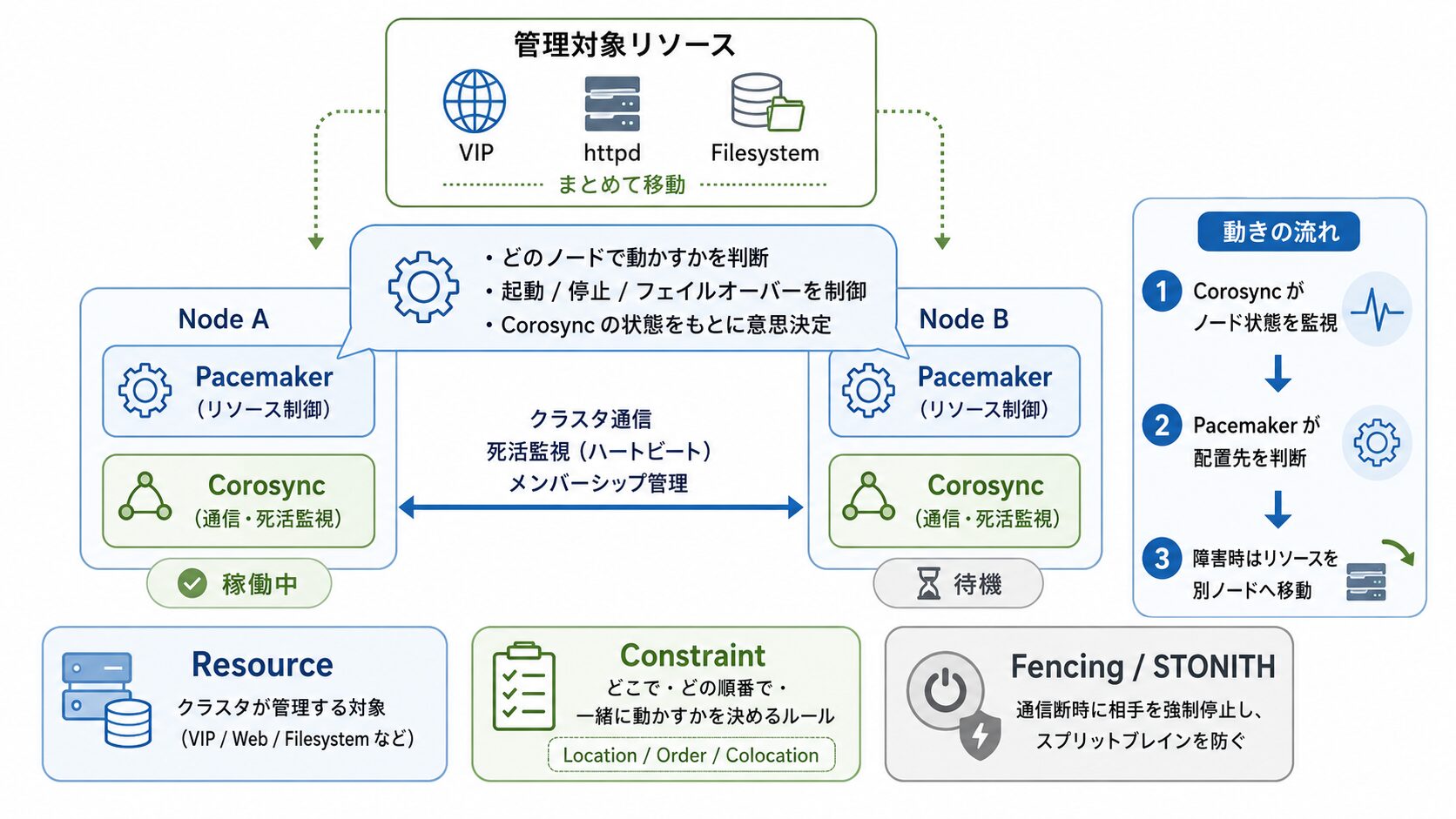
HA クラスタと Pacemaker + Corosync の基礎
HA クラスタは、複数のサーバーを連携させ、1 つのシステムとして見せる技術です。一般的には稼働系(Active)と待機系(Standby)の 2 台で構成し、稼働系に障害が発生すると Pacemaker が検知して、IP アドレスや Web サーバーなどのサービスを待機系へ引き継ぎます(フェイルオーバー)。
このとき、ノードが生きているかを確認する通信機能と、ダウンを検知したらサービスを引き継ぐ制御機能が連携して初めて成り立ちます。
なぜ Heartbeat ではなく Corosync なのか
かつての Linux クラスタでは Heartbeat が使われていましたが、RHEL 7 / CentOS 7 以降は Pacemaker + Corosync の組み合わせが標準構成です。
- Heartbeat(旧世代)
-
開発が停止しており、新しい OS ではパッケージが提供されないことが多いです。
- Corosync(新世代)
-
ノード間の通信(メッセージング)と死活監視を担当します。信頼性が高く、大規模なクラスタにも対応します。
役割分担としては、Corosync がノード間通信と死活監視を担い、Pacemaker がリソースの制御を担当します。現行の Pacemaker は、Corosync 上で動作することを前提に設計されています。
バージョンの前提(2026 年時点)
本記事は RHEL 9 / AlmaLinux 9 を対象としています。2025 年 5 月に RHEL 10 と AlmaLinux 10 がリリースされていますが、v10 系でも pcs / Pacemaker + Corosync が引き続き標準構成のため、本手順の考え方はそのまま応用できます。AlmaLinux 9 は通常サポートが 2027 年 5 月、セキュリティサポートが 2032 年 5 月までのため、9 系で構築・運用する価値は当面維持されます。
押さえておきたい 3 つの概念: Resource、Constraint、Fencing
Pacemaker を扱ううえで前提となる 3 つの概念があります。
- Resource(リソース)
-
クラスタが管理する対象。VIP(仮想 IP)、
httpd(Web サーバープロセス)、Filesystem(ディスクマウント)など。これらをまとめて、障害時にセットで移動させます。 - Constraint(制約)
-
リソースを「どこで・どの順番で・どう動かすか」のルール。場所制約(Location)、順序制約(Order: VIP が付いてから Apache を起動する等)、コロケーション制約(Colocation: VIP と Apache を同じノードで起動する等)があります。
- Fencing / STONITH
-
通信が途絶えた際、相手が本当にダウンしているのか判断できないことがあります(スプリットブレイン)。このとき相手ノードの電源を強制的に切断(STONITH: Shoot The Other Node In The Head)し、両ノードが同時に共有ディスクへ書き込む事故を防ぎます。
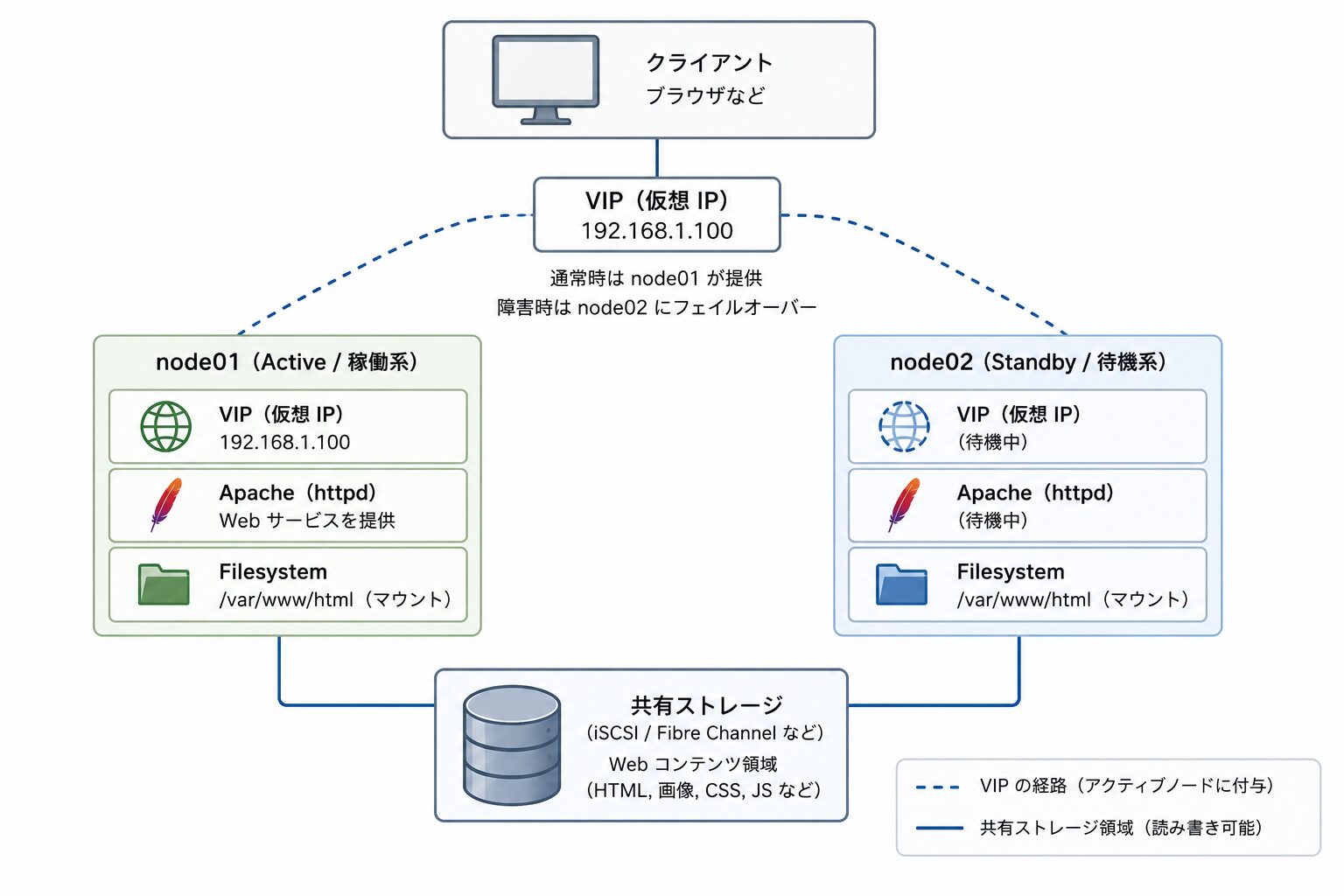
システム構成と前提条件
本記事では、以下の構成で Web サーバーの HA クラスタを構築します。シンプルですが、実用的な Active/Standby 構成の基本形です。
- 構成
-
- Web サーバー 2 台(Active/Standby)+ 共有ストレージ
- ノード
-
node01(Active): 通常時にサービスを提供する稼働系node02(Standby):node01がダウンした際に代わりを務める待機系
- 共有ストレージ
-
- 両ノードから読み書き可能なディスク領域(iSCSI や Fibre Channel など)
- Web コンテンツ(HTML など)を保存します。
- 提供するサービス(リソース)
-
- VIP(仮想 IP): クライアントがアクセスする IP アドレス(例:
192.168.1.100) - Apache(
httpd): Web サーバーソフト - Filesystem: 共有ストレージを
/var/www/htmlなどにマウント
- VIP(仮想 IP): クライアントがアクセスする IP アドレス(例:
前提設定: ホスト名解決・firewalld・時刻同期
Pacemaker をインストールする前に、OS 側で以下を整えておきます。これらが不完全だとクラスタが正常に動作しません。
ホスト名解決: ノード同士が互いのホスト名で通信できるようにします。DNS でも構いませんが、障害時の確実性を高めるため /etc/hosts への静的記述を推奨します。
# 全ノードの /etc/hosts に追記
192.168.1.101 node01
192.168.1.102 node02firewalld の設定: Corosync のノード間通信と Pacemaker の管理通信を許可します。RHEL 系では high-availability サービスを許可するのが簡単です。
# 全ノードで実行
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --reload時刻同期(Chrony): ノード間で時刻がずれると、ログ解析が困難になるだけでなく、クラスタが誤動作して予期しないフェイルオーバーを起こす原因になります。chrony などで NTP サーバーと確実に同期させることを推奨します。
SELinux: 検証環境ではトラブルを避けるため一時的に Permissive にする方法もあります。本番環境では適切にポリシーを設定して運用することを推奨します。
参考: Red Hat Enterprise Linux 9 — Configuring and managing high availability clusters
“Install the Red Hat High Availability Add-On software packages”
(Red Hat High Availability Add-On のソフトウェアパッケージをインストールする)
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/9/html/configuring_and_managing_high_availability_clusters/index
Pacemaker / Corosync のインストールとクラスタ作成
RHEL 9 / AlmaLinux 9 では、pcs コマンドを使うことで設定ファイルの直接編集を避け、対話的にセットアップできます。
インストールとサービスの起動
両ノード(node01、node02)で必要なパッケージをインストールし、サービスを起動します。
# 【両方のノードで実行】
# HA クラスタ関連のパッケージをインストール
dnf install -y pcs pacemaker corosync fence-agents-all
# pcsd を起動・自動起動設定
systemctl enable --now pcsdクラスタ認証とセットアップ
ここからは片方のノード(node01)からの操作で、両方の設定を一括で行えます。
まず、クラスタ管理用ユーザー hacluster(インストール時に自動作成)のパスワードを設定します。
# 【両方のノードで実行】
passwd hacluster次に、node01 から両ノードの認証を行います。
# 【node01 で実行】
# 両ノードを認証(先ほど設定した hacluster のパスワードを入力)
pcs host auth node01 node02 -u hacluster認証が成功したら、クラスタを作成・起動します。
# 【node01 で実行】
# クラスタ定義の作成(クラスタ名: mycluster)
pcs cluster setup mycluster node01 node02
# クラスタサービスの起動と自動起動設定(--all で全ノード一括)
pcs cluster start --all
pcs cluster enable --all2 ノード構成では、pcs cluster setup により corosync の two_node モードが有効化されます。これは 2 台ではクォーラム(過半数)を満たせないための設定で、本構成では前提として把握しておきます。
クラスタの状態確認
# ステータス確認
pcs statusCluster Summary の Online: に node01 と node02 の両方が表示されていれば、クラスタの土台は完成です。
参考: pcs(8) man page
“pcs cluster setup newcluster node1 node2”
(クラスタ作成コマンドの基本形)
https://www.mankier.com/8/pcs
リソースの登録とグループ化
土台ができたら、Pacemaker に管理対象を登録します。ここからの設定コマンドは node01(片方のノード)だけで実行すれば、自動的に全ノードへ同期されます。
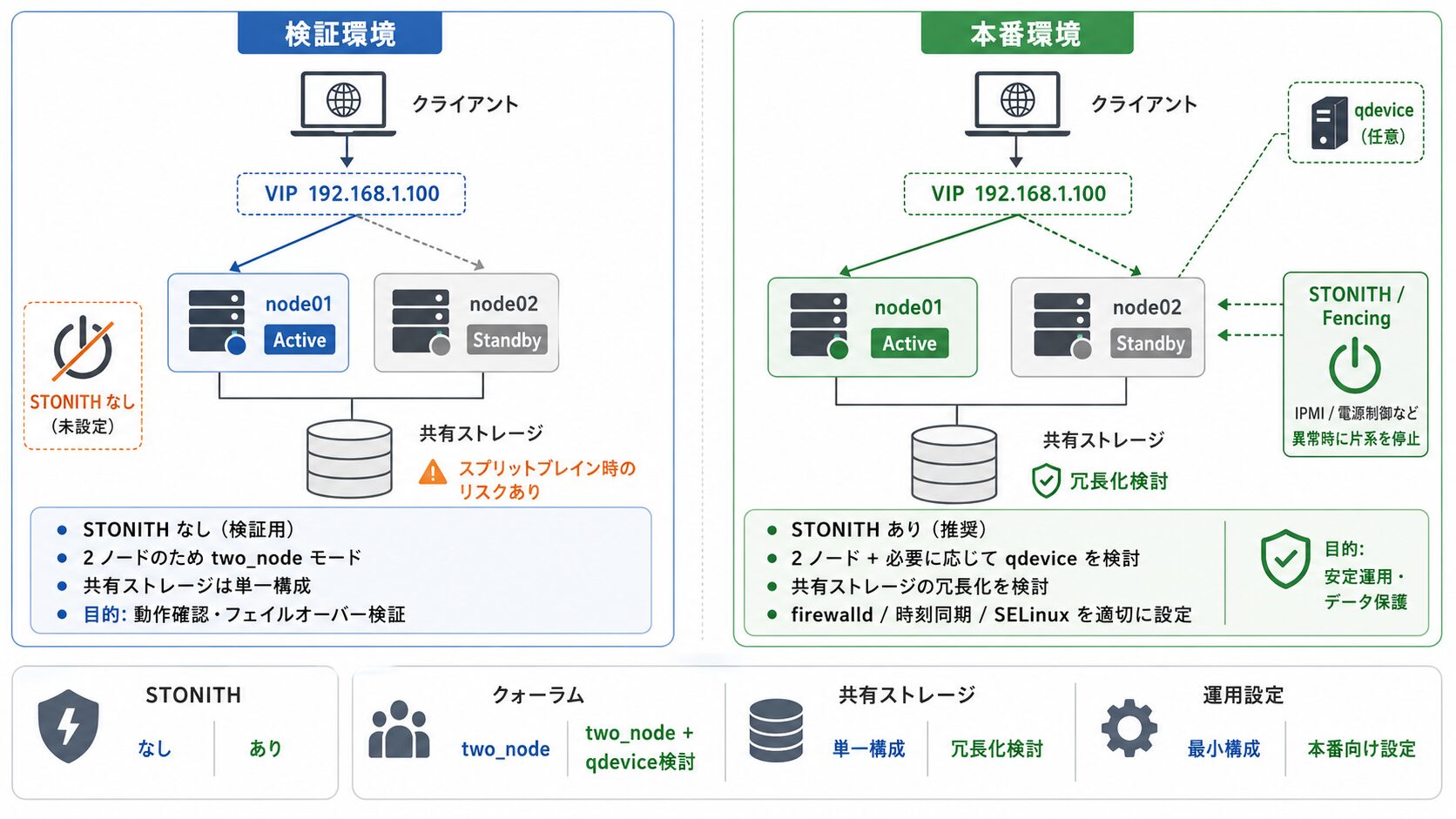
STONITH(フェンシング)の設定方針
最初に、安全装置である STONITH の方針を決めます。
STONITH(Shoot The Other Node In The Head)は、応答しなくなったノードの電源を強制的に切断する機能です。これがないと、故障したと見なされたノードが実際には動いていた場合、両ノードが同時に共有ディスクへ書き込み、データ破損(スプリットブレイン)につながります。本番環境では、IPMI や物理電源スイッチと連携した STONITH 設定を行うことを推奨します。
本記事は物理的な電源管理装置がない検証環境を想定するため、ここでは例外的に STONITH を無効化します(本番では推奨しません)。
# STONITH を無効化(検証環境のみ)
pcs property set stonith-enabled=false各リソースの作成
Web サーバーを動かすための 3 つのリソースを登録します。各コマンドの op monitor interval は、死活監視の間隔を指定するオプションです。
Filesystem(共有ディスクのマウント): Web コンテンツが保存された共有ディスクをマウントします(/dev/sdb は環境に合わせて変更)。
# リソース名「HttpdFS」を作成
pcs resource create HttpdFS ocf:heartbeat:Filesystem \
device="/dev/sdb" \
directory="/var/www/html" \
fstype="xfs" \
op monitor interval=10sVIP(仮想 IP アドレス): クライアントがアクセスする浮動 IP アドレスです(192.168.1.100 は環境に合わせて変更)
# リソース名「VirtualIP」を作成
pcs resource create VirtualIP ocf:heartbeat:IPaddr2 \
ip=192.168.1.100 \
cidr_netmask=24 \
op monitor interval=10sApache(Web サーバープロセス): Web サーバーソフト本体です(事前に dnf install httpd が必要)。
# リソース名「WebServer」を作成(systemd 経由で制御)
pcs resource create WebServer systemd:httpd \
op monitor interval=10sここで使う systemd:httpd は、httpd プロセスの生存を監視します。HTTP の応答レベルまで監視したい場合は、ocf:heartbeat:apache を使い、statusurl="http://127.0.0.1/server-status" を指定する方法もあります。プロセスは生きているが応答が返らない状態まで検知したい場合は、後者が向いています。 用途に応じて使い分けるとよいでしょう。
参考: Red Hat Enterprise Linux 9 — Configuring a Red Hat High Availability cluster with Apache
“Configure an Apache HTTP server resource”
(Apache HTTP サーバーのリソースを構成する)
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/9/html/configuring_and_managing_high_availability_clusters/assembly_configuring-active-passive-http-server-in-a-cluster-configuring-and-managing-high-availability-clusters
リソースグループで連動させる
このままでは 3 つのリソースが個別に起動するため、たとえばディスクのマウント前に Apache が起動してエラーになる可能性があります。これらを同じノードで決まった順番に起動させるため、リソースグループを作成します。
# グループ名「WebGroup」を作成し、3 つのリソースを追加
# 追加順 = 起動順
pcs resource group add WebGroup HttpdFS VirtualIP WebServerグループに追加した順序(Filesystem → VIP → WebServer)で起動し、停止時はその逆順(WebServer → VIP → Filesystem)で停止します。この順序制御を Pacemaker が自動で行います。
設定の確認
pcs statusResource Group: WebGroup の下に 3 つのリソースが並び、すべて Started node01(または node02)になっていれば成功です。
動作検証: フェイルオーバーの確認
作成したクラスタが期待どおり動くか、実際に障害を起こして確認します。
正常時の状態(pcs status の見方)
まず正常時の状態を確認します。
[root@node01 ~]# pcs status
...
Online: [ node01 node02 ]
Full list of resources:
Resource Group: WebGroup
HttpdFS (ocf::heartbeat:Filesystem): Started node01
VirtualIP (ocf::heartbeat:IPaddr2): Started node01
WebServer (systemd:httpd): Started node01確認ポイントは次の 2 点です。
Online: [ node01 node02 ]と表示され、両ノードが正常に通信できているか。- すべてのリソースが同じノード(ここでは
node01)で起動しているか。
手動スイッチオーバー(pcs resource move)
まずはコマンドで、リソースを別ノードへ移動させます。メンテナンス時に使う手順です。
# WebGroup を node02 へ移動
pcs resource move WebGroup node02再度 pcs status を確認し、すべてが Started node02 になっていれば成功です。
【重要】pcs 0.11 での移動制約の扱い(旧版からの変更点)
ここは旧バージョンと挙動が変わっており、注意が必要です。pcs 0.10 系までは、pcs resource move が場所制約を残すため、手動で解除しないと元のノードへ戻れなくなる、という説明が一般的でした。
しかし、RHEL 9 / AlmaLinux 9 が採用する pcs 0.11 系では、pcs resource move が作成する場所制約は、リソースの移動完了後に自動で削除されます。 旧版を前提とした「移動後に必ず制約を解除する」という手順は、現行バージョンには当てはまりません。
参考: Red Hat Enterprise Linux 9 — Performing cluster maintenance
“is automatically removed once the resource has been moved”
(リソースの移動が完了すると自動的に削除される)
https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/9/html/configuring_and_managing_high_availability_clusters/assembly_cluster-maintenance-configuring-and-managing-high-availability-clusters
挙動を整理すると次のとおりです。
- 制約を残したくない通常の移動:
pcs resource move(移動後に制約は自動削除) - 制約を意図的に残したい場合:
pcs resource move-with-constraintを使用 - 何らかの理由で制約が残った場合に手動で消す: 以下のコマンドで削除
# move や ban で作られた一時制約を削除
pcs resource clear WebGroupなお、移動先から好みのノードへ戻したい場合は pcs resource relocate run も利用できます。
疑似障害テスト(プロセス停止・ノード停止)
ケース 1: Web サーバープロセスを停止した場合
稼働中のノードで httpd プロセスを強制終了します。
# プロセス ID を確認して終了
kill -9 `pgrep httpd`想定される動作は次の流れです。
- Pacemaker が監視(Monitor)でプロセスの消失を検知する。
- 同じノードでの再起動(Restart)を試みる。
- 再起動できない場合、別ノードへフェイルオーバーする。
pcs status を繰り返し実行して監視すると、一時的に FAILED と表示された後に自動復旧する様子を確認できます。
ケース 2: ノードごと停止した場合
稼働系ノード(node01)を停止します。
# node01 で実行(クラスタサービスを停止)
pcs cluster stop node01
# または OS ごと再起動
reboot残った node02 がすべてのリソース(VIP・Disk・Web)を引き継ぎ、Started node02 になります。クライアントの Web ブラウザから VIP にアクセスし続け、数秒〜数十秒の断絶の後に再びページが表示されれば成功です。
なお切替の所要時間は、監視間隔(本例では 10 秒)に Pacemaker の判定・起動処理を加えた数十秒程度が目安です。要件に応じて op monitor interval を調整します。
故障検知時の挙動(on-fail)や、同一ノードでの再試行回数を決める migration-threshold、復旧時の fail-count のクリア方法については、関連記事『Pacemaker の on-fail 設定とフェイルオーバーの仕組み|RHEL 9 対応』で詳しく解説しています。
本番運用での注意点と制約
検証環境と本番環境では、考慮すべき点が異なります。導入を検討する際の判断材料として整理します。
- STONITH(フェンシング)
-
本記事の検証では無効化しましたが、本番ではスプリットブレイン時のデータ破損を防ぐため、IPMI や物理電源スイッチと連携した STONITH 設定を推奨します。STONITH なしの 2 ノード構成は、共有ストレージへの二重書き込みリスクを抱えます。
- クォーラム(2 ノード構成の制約)
-
2 台ではクォーラムを満たせないため
two_nodeモードで運用します。片系障害時の挙動を理解したうえで、必要に応じてクォーラムデバイス(qdevice)の追加も検討します。 - 共有ストレージが単一障害点になり得る点
-
Active/Standby の Web HA はサーバーを冗長化しますが、共有ストレージ自体が単一障害点になり得ます。ストレージ側の冗長化もあわせて検討します。
- 設定漏れによる起動失敗
-
firewalld での
high-availability許可漏れ、時刻同期の未設定、SELinux ポリシーは、起動失敗や予期しないフェイルオーバーの典型的な原因です。
まとめ
本記事では、RHEL 9 / AlmaLinux 9 で Pacemaker + Corosync を使い、Web サーバーの HA クラスタを構築する手順を解説しました。要点を整理すると、現行 OS では pcs コマンドで設定ファイルを直接編集せずに構築でき、resource move の制約も自動削除されます。本番では STONITH の設定が判断の分かれ目になります。
- 現行の RHEL 9 / AlmaLinux 9 では Pacemaker + Corosync が標準構成
pcsコマンドで設定ファイルを直接編集せず構築できる- VIP・共有ディスク・Apache はリソースグループで連動させる
- pcs 0.11 系では
resource moveの場所制約が自動削除される - 本番環境では STONITH(フェンシング)の設定が推奨される
- 2 ノード構成は
two_nodeモードでの運用が前提となる - 動作確認はプロセス停止とノード停止の両方で行う
以上、最後までお読みいただきありがとうございました。

