

はじめに
Pacemaker でクラスタを運用する際に設計が悩ましいのが、異常発生時にシステムをどう振る舞わせるかという点です。プロセスが落ちたときに即座に再起動させるのか、安全のために待機させるのか。この判断を自動化するのが on-fail パラメータです。
本記事は、前回構築した RHEL 9 / AlmaLinux 9 のクラスタ(詳細は関連記事『Pacemaker + Corosync で Web サーバーを冗長化する手順|RHEL 9 対応』を参照)を題材に、故障時の挙動と復旧手順を確認します。
on-failの設定値(restart/fence/block/ignore)の挙動の違いmigration-thresholdとfail-countの関係、フェイルオーバーが起きる条件- Apache リソースの故障を例にした、フェイルオーバーの流れの検証
- 故障履歴(
fail-count)の確認方法と、pcs/crmでの復旧コマンド
要点を先に整理します。on-fail の既定値は restart で、同一ノードでの再試行が migration-threshold を超えると別ノードへフェイルオーバーします。復旧時は fail-count をクリアする必要があり、自動で失効させたい場合は failure-timeout を設定します。移動制約の扱いは pcs と crm で異なり、pcs 0.11 系では自動削除、crm では手動解除が必要です。
Pacemaker の故障検知と on-fail の基礎
Pacemaker はリソースの状態を常に監視していますが、「故障」と一口に言ってもその検知タイミングは 3 種類あり、検知後の振る舞いを決めるのが on-fail 設定です。
故障検知の 3 つのタイミング(start / monitor / stop)
Pacemaker は、以下のオペレーションを実行した際の戻り値で正常・異常を判定します。
start(起動失敗)-
リソースを起動しようとしたが立ち上がらなかった場合。例: 設定ファイルの記述ミスで Apache が起動しない。
monitor(監視検知)-
定期的なヘルスチェックで異常を検知した場合。例: 稼働中のプロセスが落ちた、応答がタイムアウトした。運用中に最も発生しやすいパターンです。
stop(停止失敗)-
リソースを停止しようとしたが正常終了しなかった場合。例: プロセスが応答せず終了できない。
stop の失敗だけは扱いが異なります。STONITH が有効な場合、別ノードで安全に起動し直すため、クラスタはそのノードをフェンシングします。STONITH が無効な場合は別ノードでの起動に進めず、失効時間の後に停止を再試行します。
参考: Pacemaker — Failure Response(ClusterLabs)
“the cluster will fence the node”
(クラスタはそのノードをフェンシングする)
https://clusterlabs.org/projects/pacemaker/doc/2.1/Pacemaker_Explained/html/operations.html
on-fail の設定値(restart / fence / block / ignore)
故障検知時のアクションは on-fail で指定します。既定は restart で、要件に応じて使い分けます。
| 設定値 | 動作 | 主な用途 |
|---|---|---|
restart(既定) | リソースの再起動を試み、再試行上限を超えると別ノードへフェイルオーバーする | Web / AP サーバーなど一般的なリソース |
fence | ノードを STONITH で強制再起動し、切り離してから別ノードで引き継ぐ | DB や共有ディスクなど、データ破損を確実に避けたいリソース |
block | 状態変更を行わず、管理外(Unmanaged)として待機する | 原因調査を優先し、自動復旧させたくない場合 |
ignore | 故障を無視し、稼働中として扱う | 監視のみ行いたい限定的なケース |
on-fail はオペレーション単位で指定します。たとえば監視失敗時に fence させる場合は次のように設定します。
# monitor の故障時に fence させる例(DB など)
pcs resource update WebServer op monitor on-fail=fenceなお、ここで挙げた 4 値のほかに stop・standby・demote も指定できます。用途に応じて選択するとよいでしょう。
検証: Apache 故障時のフェイルオーバー動作
実際にリソースを故障させ、Pacemaker の反応を確認します。
検証環境の構成
node01 と node02 の 2 ノード構成で検証します。Web サーバー機能を維持するため、以下の 3 リソースをリソースグループ WebGroup にまとめて管理しています(構築手順は関連記事『Pacemaker + Corosync で Web サーバーを冗長化する手順|RHEL 9 対応』を参照)
- VirtualIP(仮想 IP):
192.168.1.100 - HttpdFS(ファイルシステム): 共有ディスクのマウント
- WebServer(Web サーバー):
systemd:httpd
初期状態ではすべて node01 で稼働しています。検証のため、再試行上限を 1 回に設定します。
# 同一ノードでの再試行を 1 回までに制限
pcs resource meta WebServer migration-threshold=1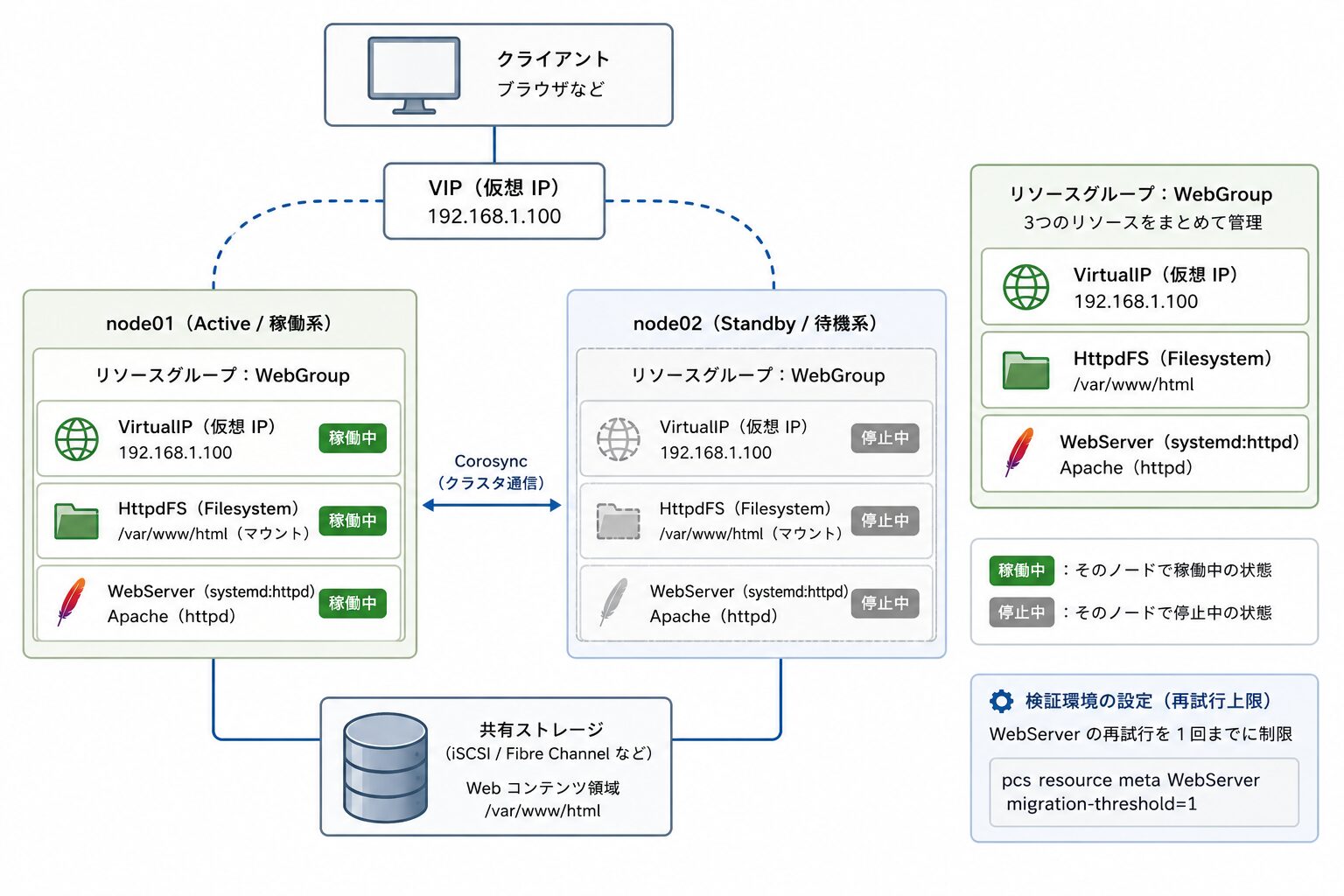
プロセス強制終了による障害発生
node01 上の Apache プロセスを強制終了します。
# node01 で実行(httpd を強制終了)
kill -9 $(pgrep httpd)Pacemaker は次のように動作しました。
- Apache の監視(
monitor)が失敗(not running)と判定する。 node01での復旧を打ち切り、リソースグループ全体を停止する。node02でリソースを起動する(フェイルオーバー完了)。
pcs status で確認すると、リソースが node02 に移動し、node01 に fail-count が記録されています。
Node List:
* Online: [ node01 node02 ]
Full List of Resources:
* Resource Group: WebGroup:
* HttpdFS (ocf::heartbeat:Filesystem): Started node02
* VirtualIP (ocf::heartbeat:IPaddr2): Started node02
* WebServer (systemd:httpd): Started node02
Migration Summary:
* Node: node01:
* WebServer: migration-threshold=1 fail-count=1なぜフェイルオーバーしたのか(migration-threshold)
on-fail=restart(再起動)を設定しているのに、なぜ同一ノードでの再起動ではなく別ノードへ移動したのか。理由は migration-threshold(移動閾値)にあります。
fail-count(失敗回数): 故障を検知するとカウントアップされます。migration-threshold: 同一ノードでの再試行を許す上限値です。
今回は migration-threshold=1 のため、1 回目の故障検知(fail-count=1)で上限に達したと判断され、node02 へフェイルオーバーしました。 既定(閾値なし)や大きな値であれば、まず node01 上での再起動が試みられます。切替の所要時間は、監視間隔に Pacemaker の判定・起動処理を加えた数十秒程度が目安です。
故障からの復旧: fail-count の確認とクリア
フェイルオーバーでサービスは node02 で稼働していますが、故障した node01 を再びリソースを受け入れられる状態へ戻す必要があります。
fail-count が残るとリソースは戻らない
Pacemaker は故障したノードに fail-count を記録します。このカウントが残っている限り、Pacemaker はそのノードへリソースを戻そうとしません。
# fail-count の確認
pcs resource failcount show WebServercleanup による復旧
故障原因(今回は強制終了したプロセス)を取り除いた後、cleanup を実行して故障履歴を消去します。
# WebServer の故障履歴を消去し、状態を再判定させる
pcs resource cleanup WebServerこれにより fail-count がリセットされ、node01 が再び正常なノードとして扱われます。
failure-timeout による自動失効
cleanup は手動操作のため、運用では fail-count の自動失効を併用すると管理が楽になります。既定では fail-count は管理者が手動でクリアするまで残りますが、failure-timeout メタ属性を設定すると自動的に失効させられます。
# fail-count を 300 秒で自動失効させる例
pcs resource meta WebServer failure-timeout=300sただし、原因を解消しないまま自動失効させると故障が再発するため、自動失効は監視・通知と組み合わせて運用することを推奨します。
手動移動(move)と移動制約の扱い
メンテナンスなどで意図的にリソースを移動させたい場合は move を使います。ここで注意が必要なのが、移動時に自動作成される場所制約です。
pcs と crm で異なる挙動
move を実行すると、現在のノードで起動しないようにする場所制約(スコア -INFINITY)が作成されます。SUSE のドキュメントでも、移動は現在ノードに対して -INFINITY スコアの場所制約を作成すると説明されています。
# WebGroup を node01 へ移動
pcs resource move WebGroup node01この制約の後始末がツールによって異なります。
pcs0.11 系(RHEL 9 / AlmaLinux 9)-
移動完了後に制約は自動削除されます。手動解除は通常不要です(詳細は関連記事『Pacemaker + Corosync で Web サーバーを冗長化する手順|RHEL 9 対応』を参照)
crm(crmsh)-
制約は残るため、手動で解除する必要があります。 残ったままだと、将来のフェイルオーバーがブロックされる可能性があります。
crm を使っている場合、または pcs で制約が残った場合は、次のコマンドで解除します。
# pcs の場合
pcs resource clear WebGroup
# crm(crmsh)の場合
crm resource unmove WebGroup解除しても、現在稼働しているリソースが自動で元へ戻ることはありません。移動の強制力を解き、Pacemaker の自律制御に戻すための操作です。
pcs / crm コマンド対応表
RHEL 系では pcs、SUSE 系では crm(crmsh)が標準です。主な運用コマンドの対応は次のとおりです。
| 操作 | pcs(RHEL 系) | crm(SUSE / crmsh) |
|---|---|---|
| 故障履歴のクリア | pcs resource cleanup WebServer | crm resource cleanup WebServer |
| fail-count の表示 | pcs resource failcount show WebServer | crm resource failcount WebServer show node01 |
| リソースの移動 | pcs resource move WebGroup node01 | crm resource move WebGroup node01 |
| 移動制約の解除 | pcs resource clear WebGroup(0.11 は通常自動) | crm resource unmove WebGroup(手動が必要) |
まとめ
本記事では、Pacemaker の on-fail 設定と、故障発生時の挙動・復旧手順を解説しました。on-fail は故障時の振る舞いを決め、migration-threshold を超えるとフェイルオーバーします。復旧では fail-count のクリアが要点になります。
on-failの既定はrestartで、Web / AP サーバーに適する- DB やディスクはデータ保護のため
fenceが向く migration-thresholdを超えると別ノードへフェイルオーバーするfail-countが残るとリソースは元のノードへ戻らない- 復旧後は
pcs resource cleanupで故障履歴を消去する - 自動失効させたい場合は
failure-timeoutを設定する - 移動制約は
pcs0.11 で自動削除、crmでは手動解除が必要
以上、最後までお読みいただきありがとうございました。

