
はじめに
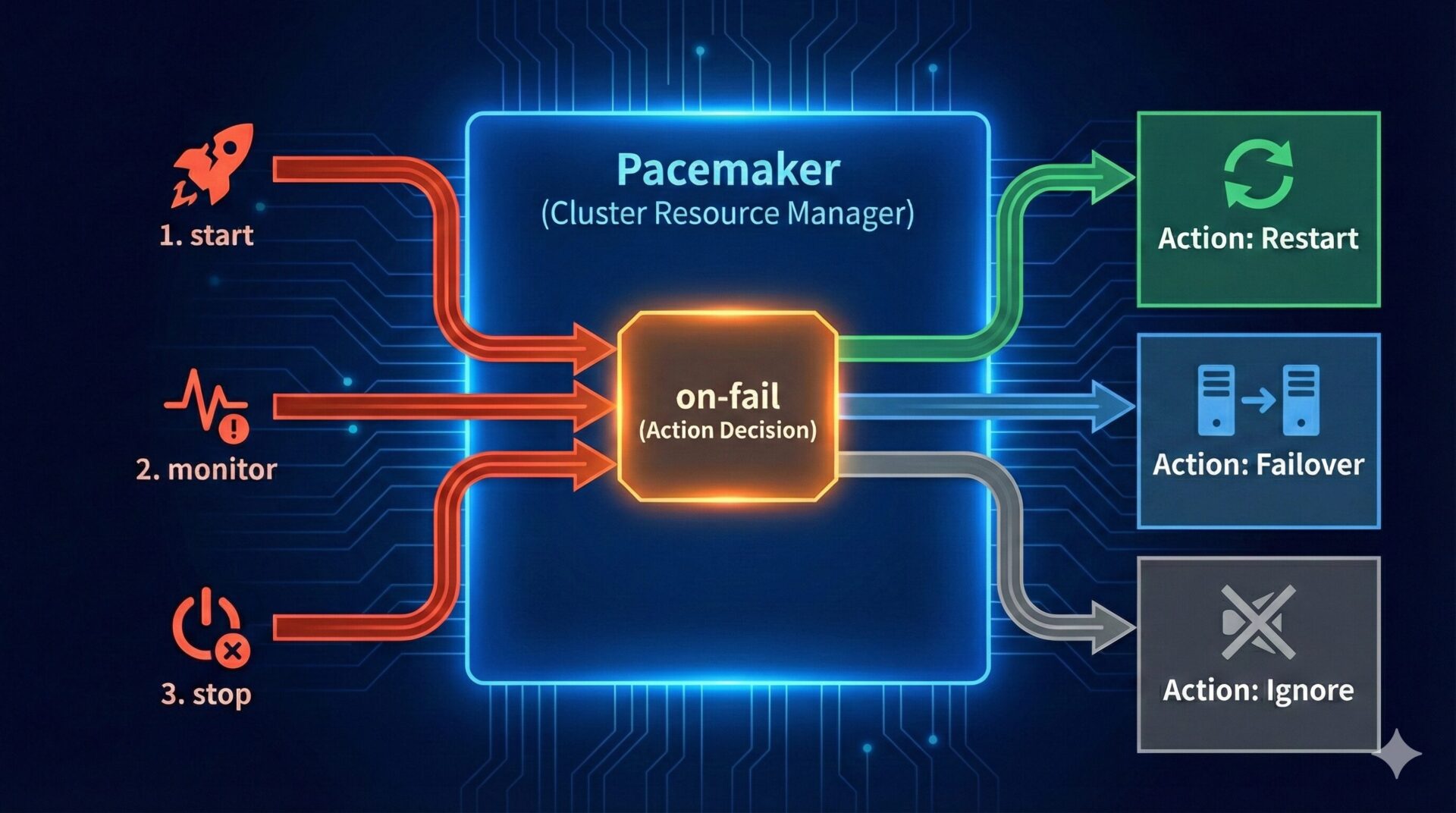
Pacemaker でクラスタシステムを構築する際、最も設計が悩ましいのが「異常発生時にシステムをどう振る舞わせるか」という点です。 プロセスが落ちたときに即座に再起動させるべきか、それとも安全のために待機させるべきか。この判断を自動化する重要なパラメータが on-fail です。
Pacemaker における「故障」とは、単にサービスがダウンすることだけを指すのではありません。具体的には以下の 3 つのタイミングで発生したエラーを区別して扱います。
- start(起動失敗)
-
リソースを起動しようとしたが失敗した
- monitor(監視検知)
-
定期チェックで異常(応答なし等)が見つかった
- stop(停止失敗)
-
リソースを停止しようとしたが正常終了しなかった
これらの故障が発生した際、Pacemaker がどのようなアクション(再起動、フェイルオーバー、無視など)を取るべきかを決定するのが on-fail 設定です。
on-failの設定値解説:restart(デフォルト)、fence、block、ignoreの挙動の違い- フェイルオーバーの仕組み: Apache リソースの故障を例に、実際にノードが切り替わる流れを検証
- 復旧手順: 故障履歴(
fail-count)の確認方法と、手動での復旧コマンド(cleanup)の使い方
Pacemaker の故障検知と on-fail 設定の基礎
Pacemaker は、リソース(Apache や DB など)の状態を常に監視していますが、一口に「故障」と言ってもその検知タイミングは 3 種類あります。また、故障を検知した後に「どう振る舞うか」を決めるのが on-fail 設定です。
故障検知の3つのタイミング(start / monitor / stop)
Pacemaker は、以下の 3 つのアクション(オペレーション)を実行した際の戻り値で、正常か異常かを判定しています。
- start(起動失敗)
-
- リソースを起動しようとしたが、正常に立ち上がらなかった場合
- 例: 設定ファイルの記述ミスで Apache が起動しない、など。
- monitor(監視検知)
-
- 定期的なヘルスチェックで異常を検知した場合
- 例: 稼働中だったプロセスが突然落ちた、応答がタイムアウトした、など。

運用中に最も発生しやすい故障パターンです。
- stop(停止失敗)
-
- リソースを停止しようとしたが、正常に終了しなかった場合
- 例: プロセスがゾンビ化して kill できない、など。この場合、データ整合性を守るために強制的なノード遮断(STONITH)が選択されることが多いです。
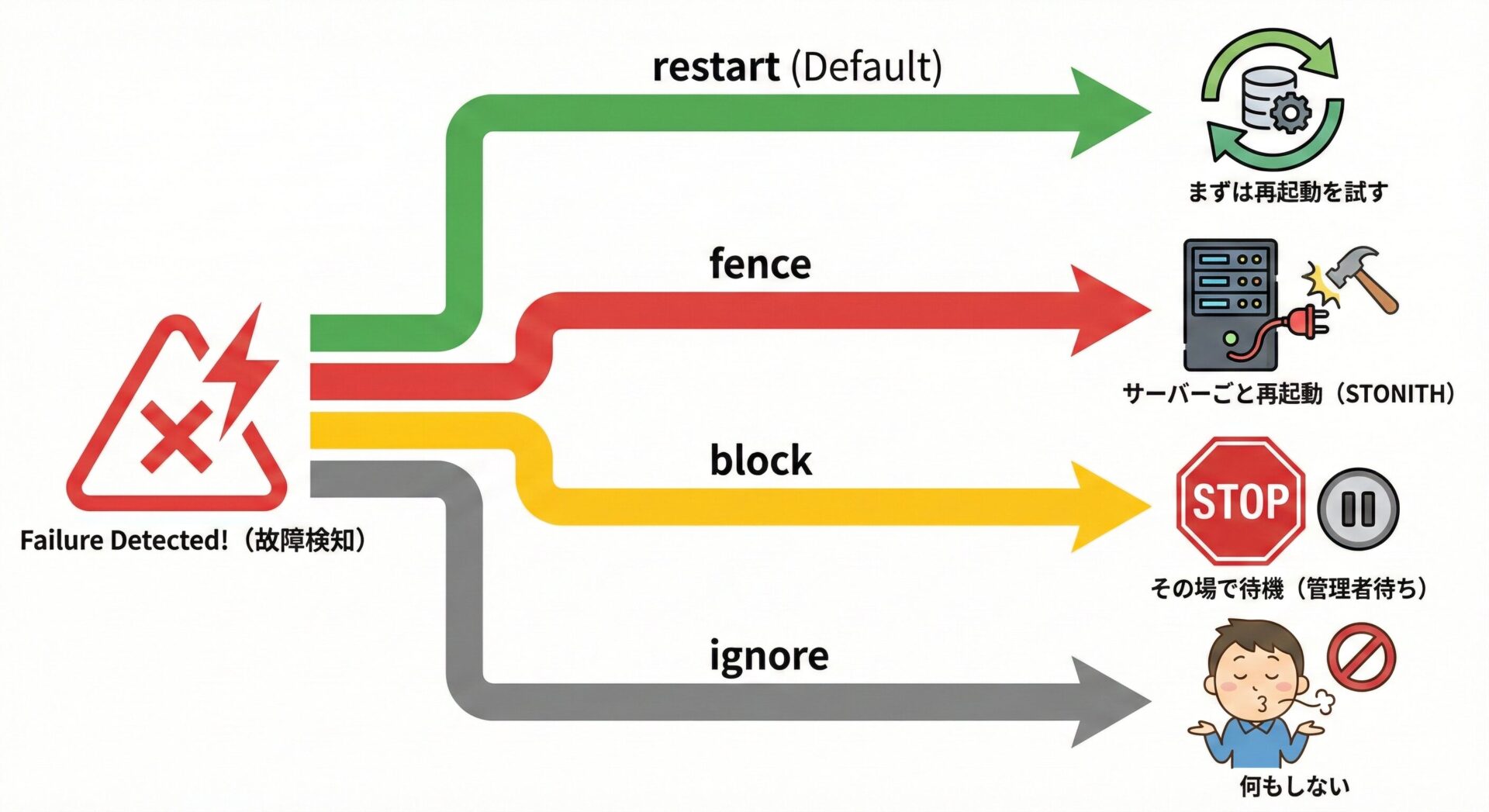
on-fail 設定値ガイド
故障を検知した際のアクションは on-fail パラメータで指定します。デフォルトは restart ですが、システムの要件に合わせて以下のように使い分けます。
| 設定値 | 動作内容 | 推奨ユースケース |
| restart (デフォルト) | リソースの再起動を試みます。 その場で復旧できない場合(回数制限を超えた場合)は、別のノードへフェイルオーバーします。 | Web サーバーや AP サーバーなど、一般的なリソース |
| fence | ノード自体を強制再起動(STONITH)します。 故障したサーバーを物理的に切り離してから、別ノードでサービスを引き継ぎます。 | DB や共有ディスクなど、データ破損(スプリットブレイン)を絶対に防ぎたいリソース |
| block | 何もしません(管理放棄) リソースの状態変更を行わず、管理外(Unmanaged)として待機します。管理者が手動で介入するまで動きません。 | 原因調査を優先したい場合や、自動復旧させたくない特殊な環境 |
| ignore | 見て見ぬふりをします。 故障を検知しても無視し、稼働し続けているものとして扱います。 | 監視だけ行いたい場合(非常に稀な設定) |
検証: Apache 故障時のフェイルオーバー動作
実際にリソースを故障させて、Pacemaker がどのように反応するかを確認してみましょう。
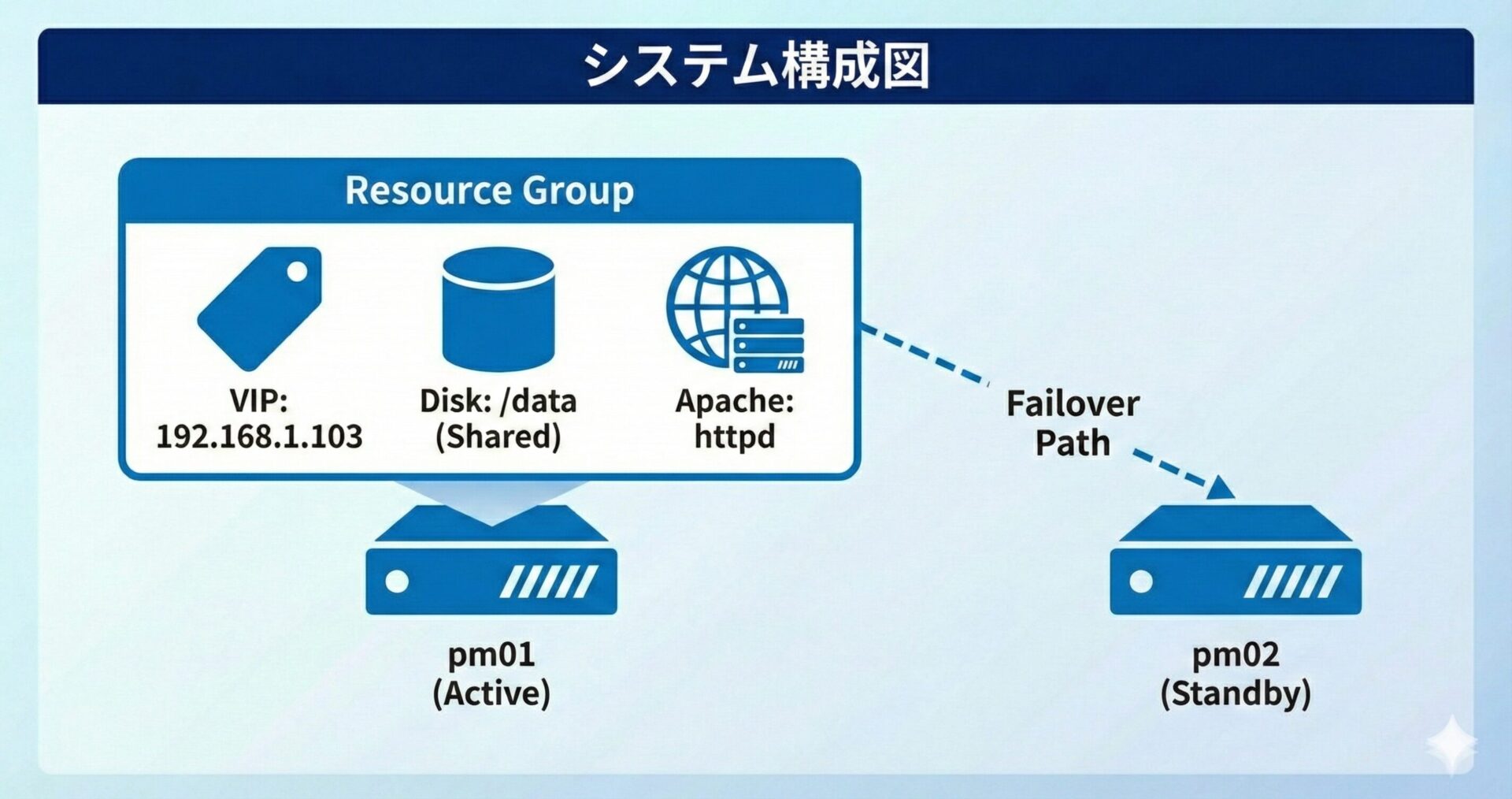
検証環境の構成
今回は pm01 と pm02 の2ノード構成で検証を行います。 Web サーバーとしての機能を維持するため、以下の3つのリソースをグルーピングして管理しています。
- VIP(仮想 IP): 192.168.1.103
- Disk(ファイルシステム): 共有ディスクのマウント
- Apache(Web サーバー): httpd プロセス
プロセス強制終了による障害発生と挙動の確認
初期状態では、すべてのリソースが pm01 で稼働しています。また、検証のために 「1回でも失敗したら諦めて移動する(migration-threshold=1)」 という設定を入れています。
この状態で、pm01 上の Apache プロセスを kill コマンドで強制停止させます。
# pm01で実行(プロセスIDを確認してkill)
ps -ef | grep apache
kill -9 7436すると、Pacemaker は即座に異常を検知し、以下のように動作しました。
- Apache の監視(monitor)が失敗(
not running) pm01での復旧を諦め、リソース全体を停止- pm02 でリソースを起動(フェイルオーバー完了)
実際の crm_mon のログ(抜粋)を見ると、リソースが pm02 に移動しているのがわかります。
Online: [ pm02 pm01 ]
Resource Group: Cluster
vip (ocf::heartbeat:IPaddr2): Started pm02
mnt_fs (ocf::heartbeat:Filesystem): Started pm02
apache (lsb:httpd): Started pm02
Migration summary:
* Node pm01:
apache: migration-threshold=1 fail-count=1 /* ← 失敗回数がカウントされている */なぜフェイルオーバーしたのか?(migration-threshold の解説)
ここで疑問に思うかもしれません。 「on-fail="restart"(再起動)に設定しているのに、なぜその場での再起動ではなく、隣のノードへ移動(フェイルオーバー)したのか?」 と。
その理由は、migration-threshold(移動閾値) の設定にあります。
- fail-count(失敗回数): 故障を検知するとカウントアップされます。
- migration-threshold: 「この回数までなら、同じノードでの再起動(粘り)を許す」という上限値です。
今回の検証では migration-threshold="1" に設定していました。 そのため、「1回目の故障検知(fail-count=1)」 の時点で 「上限(threshold=1)に達した」 と判断され、Pacemaker は「このノード(pm01)はもうダメだ」と見切りをつけて pm02 へ逃げ出したのです。

もしここがデフォルト(閾値なし)や大きな値であれば、まずは pm01 上で Apache の再起動だけが行われていたはずです。
復旧手順: fail-count の仕組みとクリア方法
フェイルオーバーが無事に完了し、サービスは pm02 で稼働していますが、運用担当者の仕事はここで終わりではありません。 故障した pm01 を復旧させ、再びリソースを受け入れられる状態に戻す必要があります。
「fail-count」が残っているとリソースは戻らない
Pacemaker は、一度故障したノードに対して 「失敗回数(fail-count)」 というレッテルを貼ります。 このカウントが残っている限り、Pacemaker は「あそこは危険だ」と判断し、リソースを戻そうとしません。
crm_mon コマンドで確認すると、pm01 に fail-count=1 が記録されているのがわかります。
Migration summary:
* Node pm01:
apache: migration-threshold=1 fail-count=1 /* ← これが残っている */正しい復旧コマンド(cleanup)の使い方
原因(今回の場合は強制終了したプロセス)を取り除いた後、Pacemaker に「もう大丈夫だよ」と伝えるために、クリーンアップ(cleanup) を実行します。
# pm01 上の apache リソースの履歴を消去する
crm resource cleanup apache pm01これにより、fail-count が 0 にリセットされ、pm01 は再び正常なノードとして認識されます。
リソースの手動移動(move)と注意点
メンテナンスなどで、意図的にリソースを別のノードへ移動させたい場合は move コマンドを使います。 ただし、このコマンドには初心者が見落としがちな罠があります。
リソース移動時に自動作成される「制約」の罠
以下のコマンドで、リソースグループ(Cluster)を pm01 へ戻してみます。
# pm01 へ強制移動
crm resource move Cluster pm01 forceこれでリソースは移動しますが、実は裏側で 「pm02 では起動してはいけない(スコープ -INFINITY)」 という場所制約(Location Constraint) が自動的に作成されてしまいます。
これは「一時的な移動」を実現するための Pacemaker の仕様ですが、この制約が残ったままだと、将来 pm01 が故障した際に、pm02 へのフェイルオーバーがブロックされてしまう可能性があります。
移動禁止フラグを解除する unmove の重要性
手動移動が完了したら、必ず unmove コマンドを実行して、自動作成された制約を解除してください。
# 移動制約(移動禁止フラグ)を解除する
crm resource unmove Clusterこれを実行しても、現在動いているリソースが勝手に戻ることはありません。「移動の強制力」を解き、再び Pacemaker の自律制御に戻すための重要な手順です。
まとめ
本記事では、Pacemaker の on-fail 設定と、障害発生時の挙動について解説しました。
- on-fail 設定の使い分け
-
- Web/AP サーバーなら
restart(再起動) - DB/ディスクならデータ保護のために
fence(STONITH)
- Web/AP サーバーなら
- フェイルオーバーの条件
-
migration-threshold(再試行回数)を超えると、隣のノードへ移動する。
- 復旧の鉄則
-
- 障害対応後は必ず
cleanupでfail-countを消すこと。 - 手動移動(
move)後は必ずunmoveで制約を解除すること。
- 障害対応後は必ず
以上、最後までお読みいただきありがとうございました。

