

はじめに
近年、クラウド環境における大容量データ管理において、オブジェクトストレージの優れたスケーラビリティと、ファイルシステムの直感的な操作性の両立が課題となっていました。これまで、Amazon S3 に保存されたデータを従来のアプリケーションからファイルとして扱うためには、データの複製や定期的な同期バッチ、あるいはサードパーティ製ツールの導入が求められるケースが一般的でした。
今回新たに発表された Amazon S3 Files は、S3 バケットを直接ファイルシステムとしてマウントできるネイティブな機能です。データの複製や移動を伴わずに、既存のファイルベースのツールやアプリケーションから S3 データへ直接アクセスすることが可能になります。
参考: AWS(Announcing Amazon S3 Files, making S3 buckets accessible as file systems)
“S3 Files is a shared file system that connects any AWS compute directly with your data in Amazon S3. It provides fast, direct access to all of your S3 data as files with full file system semantics and low-latency performance, without your data ever leaving S3.”
(S3 Filesは、任意のAWSコンピューティングをAmazon S3内のデータに直接接続する共有ファイルシステムです。データがS3から離れることなく、すべてのS3データにファイルとして高速かつ直接アクセスでき、完全なファイルシステムセマンティクスと低レイテンシーのパフォーマンスを提供します。)
https://aws.amazon.com/jp/s3/features/files/
本記事では、この Amazon S3 Files の概要や利点を整理するとともに、類似サービスとの比較、具体的な設定手順、運用上の留意点について詳しく解説します。
- Amazon S3 Files の基本概要と主なメリット
- Amazon FSx やオープンソース(S3FS 等)との機能・コスト比較
- EC2 インスタンスおよびオンプレミス環境からのマウント設定手順
- 導入前に把握しておくべきパフォーマンス特性と運用上の留意点
お時間がない方向けに、 2 分の音声で要点をサクッと解説しています。
※解説はブログ記事をもとに AI で生成しています。
Amazon S3 Files の概要と主なメリット
Amazon S3 Files は、Amazon S3 に保存されたオブジェクトデータを、共有ファイルシステムとして直接マウントして利用できる機能です。内部的には Amazon EFS の技術が組み込まれており、頻繁にアクセスされるデータ(アクティブなワーキングセット)を自動的に高性能ストレージへロードするアーキテクチャが採用されています。
これにより、事前のデータ同期やコピー処理を挟むことなく、既存のファイルベースのアプリケーションから低レイテンシで S3 のデータ群へアクセスすることが可能になります。
参考: AWS(Announcing Amazon S3 Files, making S3 buckets accessible as file systems)
“S3 Files is built using Amazon EFS, which intelligently loads your active working set onto high-performance storage. This delivers low latencies for frequently accessed data while keeping costs proportional to what you’re actively using.”
(S3 Files は Amazon EFS を使用して構築されており、アクティブなワーキングセットを高性能ストレージにインテリジェントにロードします。これにより、頻繁にアクセスされるデータに対して低レイテンシーを提供しながら、アクティブに使用しているものに比例したコストを維持します。)
https://aws.amazon.com/jp/s3/features/files/
本機能を利用する主なメリットとして、以下の 3 点が挙げられます。
- データサイロの解消とアーキテクチャの簡素化
-
S3 を信頼できる単一の情報源(Single Source of Truth)として維持したまま、最大 25,000 のコンピューティングリソースから同時にファイルアクセスが可能です。データ移動のための ETL パイプラインや同期バッチが不要になるため、システム構成の複雑化や運用負荷の軽減につながります。
- 高パフォーマンスの維持
-
バケットあたり 1,000 万以上の IOPS、および毎秒複数テラバイトの読み取りスループットにスケールします。機械学習のトレーニングパイプラインや、AI エージェントが中間結果をやり取りする共有ワークスペースなど、高い I/O 性能が要求されるワークロードへの適用が推奨されます。
- 運用コストの最適化
-
設定した期間(1 〜 365 日の間で指定、デフォルトは 30 日)アクセスされなかったデータは、自動的に高性能なキャッシュストレージから期限切れとなる仕組みを持っています。必要なデータのみに高性能ストレージのコストが発生するため、別々のファイルシステム間でデータを循環させる従来の手法と比較して、最大 90% 程度のコスト削減が見込めます。
既存サービス(FSx シリーズ・S3FS)との機能・コスト比較
Amazon S3 のデータをファイルとして扱う場合、これまでは Amazon FSx for Lustre を利用してデータを同期するか、オープンソースの S3FS(FUSE)を用いてマウントする手法が一般的でした。しかし、それぞれパフォーマンスや運用コスト、管理の手間において一長一短がありました。
Amazon S3 Files は、これら既存手法の課題を解決する新しい選択肢として位置づけられます。特に、別々のファイルシステムを用意してデータを移動させる従来手法と比較した場合、大幅なコスト最適化が期待できます。
参考: AWS(Announcing Amazon S3 Files, making S3 buckets accessible as file systems)
“up to 90% lower costs compared to cycling data between S3 and separate file systems”
(S3と個別のファイルシステム間でデータを循環させる場合と比較して、最大90%のコスト削減)
https://aws.amazon.com/jp/s3/features/files/
各サービスの特徴と、それぞれの導入が推奨されるユースケースを以下の表に整理しました。
| 比較項目 | Amazon S3 Files | Amazon FSx for Lustre | S3FS(オープンソース) |
| アーキテクチャ | ネイティブアクセス(EFS 技術ベース) | 独立した高性能ファイルシステム | OS 上の FUSE マウント |
| データ同期 | 不要(直接アクセス) | 必要(S3 とのインポート / エクスポート) | 不要(直接アクセス) |
| パフォーマンス | 高(最大数 TB/s のスループット) | 超高(HPC などの極限のワークロード向け) | 低(レイテンシが高くボトルネックになりやすい) |
| コスト構造 | アクティブデータのみ課金(従量課金) | プロビジョニングされた容量とスループットによる課金 | 無料(※EC2 インスタンスの稼働費用のみ) |
| 最適なユースケース | AI 開発の共有ワークスペース、データ準備、一般的な分析パイプライン | 膨大なノードでの超並列計算、ミリ秒未満の極端な I/O 性能が要求される HPC | 低頻度のアクセス、一時的なログ出力、コストを極限まで抑えたい小規模環境 |
選択のポイント
機械学習のトレーニングやデータサイエンティストのコラボレーション環境など、パフォーマンスと運用負荷のバランスが求められる一般的なファイルベースのワークロードにおいては、データ同期の複雑さを排除できる Amazon S3 Files の採用を推奨します。
一方で、既存の FSx シリーズが完全に不要になるわけではありません。数百から数千の並列ノードで極限のスループットを追求する HPC 領域では FSx for Lustre が、Windows 環境のネイティブな連携(Active Directory 統合など)が必須な場合は FSx for Windows File Server が引き続き有力な選択肢となります。
Amazon S3 Files のマウント・設定手順(EC2・オンプレミス)
Amazon S3 Files は内部的に Amazon EFS の技術を採用しているため、標準的な Linux ベースのコンピューティングリソースから、従来のネットワークファイルシステムと同様のコマンド体系でアクセスすることが可能です。専用のカスタムツールや複雑な認証フローを新しく覚える必要はありません。
参考: AWS(Announcing Amazon S3 Files, making S3 buckets accessible as file systems)
“S3 Files works like a traditional high-performance file system that can be accessed by any Linux-based compute resource, but its view of files and folders reflects what’s in your S3 bucket.”
(S3 Files は、Linux ベースの任意のコンピューティングリソースからアクセスできる従来の高性能ファイルシステムのように機能しますが、ファイルとフォルダーのビューは S3 バケット内のものを反映します。)
https://aws.amazon.com/jp/s3/features/files/
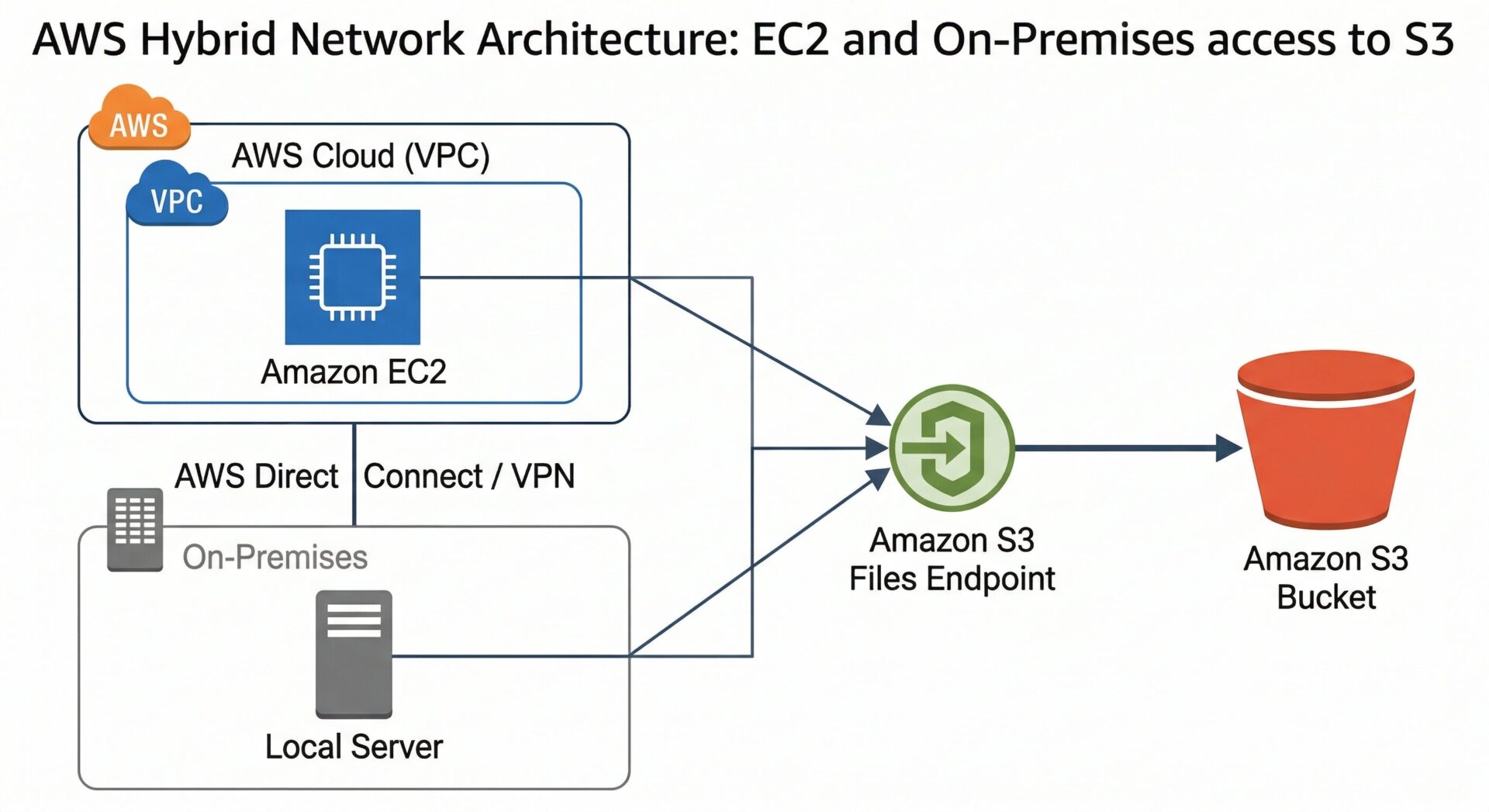
実際の運用環境で想定される、代表的な 2 つの接続パターンにおけるマウント手順と設定の要点を解説します。
同一 VPC 内で稼働する EC2 インスタンス(Linux)からアクセスする場合、標準的な NFS クライアントユーティリティを利用することが推奨されます。
OS のパッケージマネージャーを使用し、NFS マウントに必要なツール(nfs-utils または amazon-efs-utils など)をインストールします。
インスタンス内の任意の場所(例: /mnt/s3files)に、マウント先となる空のディレクトリを作成します。
AWS マネジメントコンソールで発行された S3 Files のエンドポイント(DNS 名)を指定し、mount コマンドを実行します。この際、EC2 にアタッチされたセキュリティグループにて、NFS ポート(TCP 2049)のインバウンド通信が許可されていることを事前に確認することが望ましいです。
社内のローカルサーバーや研究室のワークステーションなど、AWS 外部のオンプレミス環境から S3 Files にアクセスする場合、セキュリティの観点から AWS Direct Connect または AWS Site-to-Site VPN を経由した閉域網接続の利用が推奨されます。
オンプレミス環境と AWS VPC を VPN または Direct Connect で接続し、双方向のルーティングを適切に構成します。
S3 Files のエンドポイントは、VPC 内のプライベート IP アドレスとして解決される必要があります。そのため、Amazon Route 53 Resolver のインバウンドエンドポイントなどを活用し、オンプレミス側の DNS サーバーから AWS 側の名前解決ができるようフォワード設定を行うことが推奨されます。
ネットワークと DNS の準備が整った後、EC2 と同じ mount コマンドをオンプレミスの Linux サーバーから実行します。これにより、ローカルのファイルサーバーを操作する感覚で、ペタバイト規模の S3 データへ安全にアクセスすることが可能になります。
パフォーマンス特性と実運用に向けた最適化のヒント
Amazon S3 Files は、バケットあたり 1,000 万以上の IOPS、毎秒複数テラバイトの集約読み取りスループット、そして最大 25,000 のコンピューティングリソースからの同時アクセスをサポートする非常に高いパフォーマンスを提供します。
この性能をコスト効率よく最大限に引き出すためには、S3 Files が内部でどのようにデータを扱っているか(キャッシングと遅延ロードの仕組み)を理解し、ワークロードに応じたチューニングを行うことが推奨されます。
参考: AWS(Announcing Amazon S3 Files, making S3 buckets accessible as file systems)
“When you read files, S3 Files lazily loads portions of file metadata and contents onto high-performance storage. Data that doesn’t meet your configured file size threshold is read directly from S3, with no file system storage involved.”
(ファイルを読み取ると、S3 Files はファイルメタデータとコンテンツの一部を高性能ストレージに遅延ロード(lazy load)します。設定したファイルサイズしきい値を満たさないデータは、ファイルシステムストレージを介さずに S3 から直接読み取られます。)
https://aws.amazon.com/jp/s3/features/files/
実運用に向けて、以下の 3 つの最適化ポイントを考慮することをおすすめします。
- ワーキングセットの有効期限(保持期間)の最適化
-
S3 Files の背後にある高性能ストレージ(EFS ベース)にロードされたデータは、一定期間アクセスがないと自動的に削除(期限切れ)になります。この期間は 1 日から 365 日(デフォルトは 30 日)の間で設定可能です。バッチ処理や機械学習の学習フェーズなど、短期間しかデータにアクセスしないワークロードの場合は、この日数を短く設定することで、不要なストレージコストの削減につながります。
- ファイルサイズのしきい値の設計
-
前述の引用にある通り、すべてのファイルが高性能ストレージにキャッシュされるわけではありません。設定したサイズしきい値以下の小さなファイルは S3 から直接読み取られます。大量の小規模ファイルを頻繁に読み書きする環境(IoT ログや一部の解析データなど)では、このしきい値の設定がレイテンシに直結するため、実際のデータ特性に合わせた事前の検証を推奨します。
- 書き込みの同期タイミングと整合性の考慮
-
S3 Files マウント経由でデータを書き込むと、データはまず耐久性の高い高性能ストレージに保存され、その後バックグラウンドで S3 バケットへ同期(Sync)されます。このため、書き込み直後に別システムから「S3 API 経由」で該当オブジェクトを直接参照すると、変更が反映されるまでにわずかなタイムラグが発生する可能性がある点に留意が必要です。
既存の S3 機能(ライフサイクル等)との連携における留意点
Amazon S3 Files の最大の特徴は、マスターデータが S3 バケットから別のストレージへと移動しない点にあります。そのため、Amazon S3 が提供する強固なセキュリティ(IAM ポリシーやアクセス制御リスト)、監査証跡、およびデータ保護機能(クロスリージョンレプリケーションなど)をそのまま継続して利用することが可能です。
参考: AWS(Announcing Amazon S3 Files, making S3 buckets accessible as file systems)
“Data that hasn’t been accessed within a configurable window (1 to 365 days, defaulting to 30) automatically expires from this storage, so you pay only for what you’re actively using while your authoritative data always remains in S3.”
(設定可能な期間(1 日〜 365 日、デフォルトは 30 日)アクセスされなかったデータは、自動的にこのストレージから期限切れになります。そのため、マスターデータは常に S3 に残ったまま、アクティブに使用しているものに対してのみ支払いが発生します。)
https://aws.amazon.com/jp/s3/features/files/
このように既存の仕組みを維持できる一方で、ファイルシステムとしての機能が追加されることで、従来の S3 運用ルールと組み合わせる際には以下の点に留意することが推奨されます。
- S3 ライフサイクルルールとの競合
-
S3 Files 側の「高性能ストレージ(キャッシュ)からの期限切れ」と、S3 バケット側の「S3 Glacier などのアーカイブ層への移行(ライフサイクルルール)」は、完全に独立した設定です。ファイルシステムとして頻繁にアクセスする予定のデータが、S3 側のルールによって誤って Glacier へ移行(読み取りに復元プロセスが必要な状態)してしまわないよう、両者の保持ポリシーを統合的に設計することが推奨されます。
- S3 バージョン管理機能との関係
-
S3 バケットのバージョン管理機能が有効な環境において、S3 Files のマウントポイント経由でファイルを上書き、または削除した場合、S3 側ではオブジェクトの新しいバージョンの作成や削除マーカーの付与が行われます。ファイルシステム上の気軽なファイル操作が、S3 側のストレージ容量(古いバージョンの蓄積)に影響を与える可能性がある点に注意が必要です。
- イベント通知との連携
-
S3 Files 経由での書き込みは、バケットへの同期が完了したタイミングで S3 の標準的な
PutObjectなどのイベントをトリガーします。既存の AWS Lambda などを用いたイベント駆動型のパイプラインと連携する際は、ファイルシステム側での一時的な保存ではなく、S3 側への同期タイミングが起点となることを前提としたアーキテクチャの構築をおすすめします。
まとめ
- Amazon S3 Files は、S3 のデータを直接ファイルシステムとしてマウントできる新機能である。
- データの同期や移動が不要になるため、システム構成の簡素化と最大 90% のコスト削減が期待できる。
- EC2 やオンプレミス環境から、標準的な Linux コマンドを使用して容易にマウント可能である。
- 運用時は、キャッシュの保持期間や S3 側のライフサイクルルールとの競合を考慮した設計が推奨される。
- 高い I/O 性能が求められる AI 開発や、分析パイプラインなどの共有ワークスペースに最適な選択肢となる。
以上、最後までお読みいただきありがとうございました。
