

はじめに
以前の検証では、Azure Data Factory(ADF)を使って手動でデータをコピーする手順を紹介しました。データ基盤の全体像については、関連記事『Azure で構築するデータ分析基盤|Data Factory と Power BI の連携手順』で解説しています。
本記事ではそれを発展させ、「Blob Storage に CSV を置くだけ」で自動的にパイプラインが起動し、SQL Database へ取り込む仕組み(ストレージイベントトリガー) を構築します。
- 「ファイルを置くだけ」で動く自動化パイプラインの構築
- ADF ストレージイベントトリガー(Blob Created)の設定手順
- ファイル名を動的に受け渡すパラメータ設定の方法
- Event Grid 登録やマネージド ID 認証など、つまずきやすい前提と安全な構成
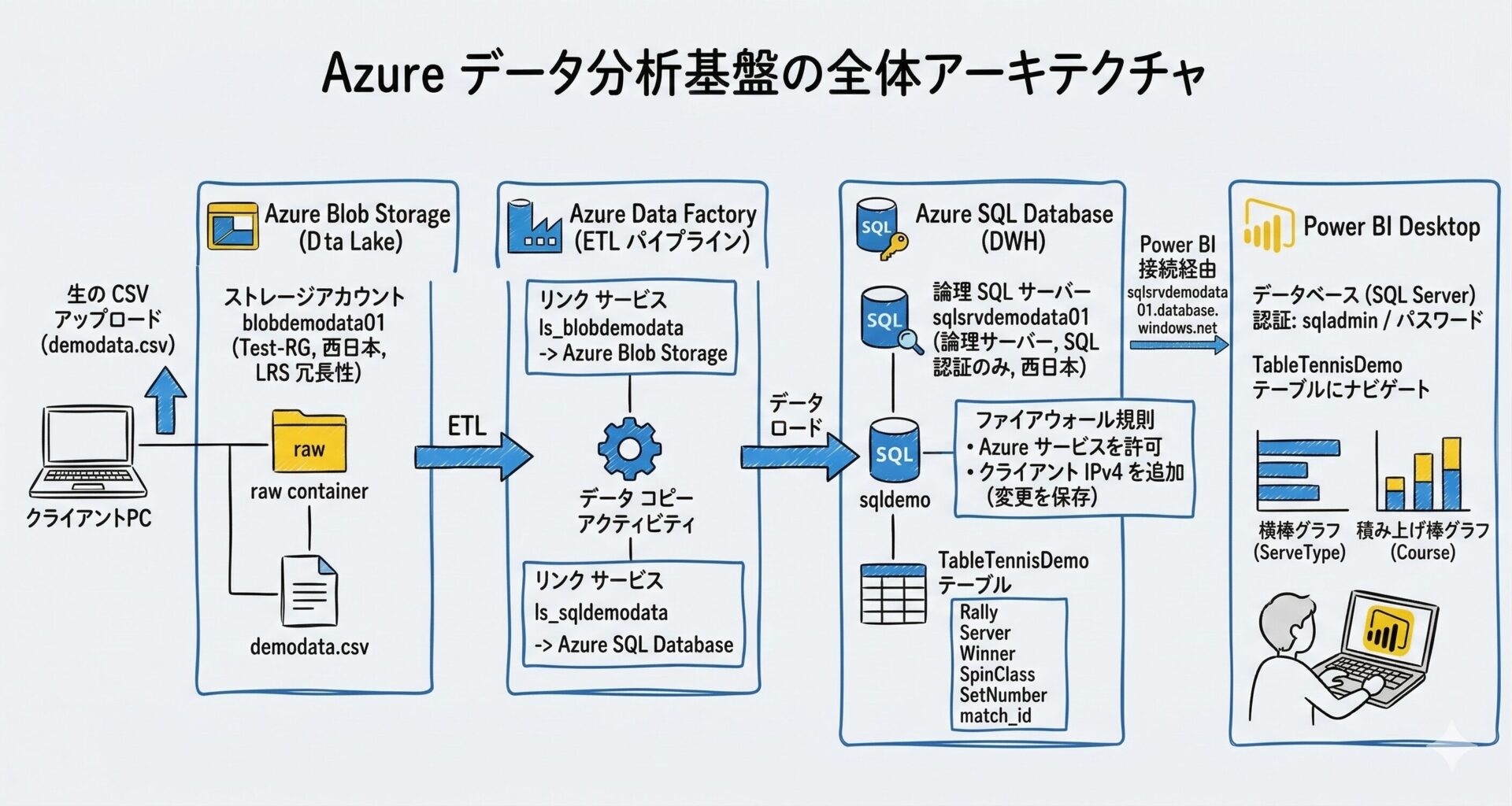
全体アーキテクチャ
構成は前回と同じく、以下の流れです。
- CSV アップロード: ユーザーが Blob Storage の
raw/inbox/にファイルを配置 - イベント検知: ADF のストレージイベントトリガーがファイルの作成を検知
- パイプライン実行: ADF がデータをコピーし、SQL Database(サーバーレス)へ追記
- 可視化: Power BI(DirectQuery)で最新データを表示
前提条件(先に確認)
ストレージイベントトリガーは Azure Event Grid を利用する仕組みのため、構築前にいくつかの前提を満たしておく必要があります。ここでつまずくとトリガーの発行(パブリッシュ)時にエラーになるため、最初に確認しておくことをおすすめします。
① Event Grid リソースプロバイダーの登録
最も見落とされやすい前提です。サブスクリプションが Event Grid リソースプロバイダーに登録されている必要があります。
参考: Create event-based triggers – Azure Data Factory(Microsoft Learn)
“Make sure that your subscription is registered with the Event Grid resource provider.”
(サブスクリプションが Event Grid リソースプロバイダーに登録されていることを確認してください。)
https://learn.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger
未登録のままトリガーを発行すると、イベントサブスクリプションの作成に失敗したというメッセージが表示されます。登録状況は次の手順で確認できます。
- Azure ポータルで対象の サブスクリプションを開きます
- 左メニューの「リソース プロバイダー」を選択します
Microsoft.EventGridを検索し、状態が「登録済み(Registered)」であることを確認します- 「未登録(NotRegistered)」の場合は、選択して「登録」を選びます
Azure CLI を使う場合は、次のコマンドでも登録できます。
az provider register --namespace Microsoft.EventGrid② トリガー作成・発行に必要な権限
トリガーを作成・変更するアカウントには、Event Grid に対する適切な権限が必要です。具体的には Microsoft.EventGrid/eventSubscriptions/ の操作が可能である必要があり、これは EventGrid EventSubscription Contributor 組み込みロールに含まれます。なお、Data Factory のサービスプリンシパル自体には、ストレージや Event Grid への特別な権限は不要です。
③ 対応するストレージ種別
ストレージイベントトリガーが対象とするのは、ADLS Gen2 または General Purpose v2(GPv2)の BlockBlob ストレージです。本記事は HNS を有効化した ADLS Gen2 を使用しているため、この要件を満たします。
④ プライベートエンドポイント利用時の注意
ストレージをプライベートエンドポイントの背後に置く構成では、追加のネットワーク設定が必要です。Blob ストレージがパブリックネットワークアクセスを遮断している場合は、Blob から Event Grid への通信を許可するネットワーク規則を構成する必要があります。閉域構成の詳細は、関連記事『Azure Private Endpoint の設定手順|Blob Storage への閉域接続と DNS 設定』も参考になります。
ストレージ(ADLS Gen2)の準備
データレイクとなるストレージを作成し、テストデータを配置します。
Azure ポータルから「ストレージアカウント」を新規作成します。今回はデータレイクとして利用するため、階層型名前空間(HNS)の有効化が必要です。画面のタブに沿って、以下のように設定します。
- リソースグループ:
rg-lake-demo - アカウント名:
stlakedemo01 - リージョン: 任意のリージョン(後続のリソースと統一することを推奨)
- パフォーマンス: Standard
- 冗長性: ローカル冗長ストレージ(LRS)
- 詳細設定: 「階層型名前空間を有効にする」にチェック
入力後、「作成」を選択してデプロイを完了します。
CSV を格納するフォルダ構成を準備します。
- ストレージアカウントの管理画面で、左メニュー「データ ストレージ」>「コンテナー」を選択します
- 「+ コンテナー」から、名前を
rawとして作成します rawコンテナを開き、「+ ディレクトリの追加」からinboxサブフォルダを作成します
これで次のフォルダ構成が完成します。
raw/
└── inbox/運用では、ユーザーがこの inbox フォルダに CSV をアップロードすると、それを起点に後続の自動処理が動きます。
SQL Database(サーバーレス)の準備
データの格納先となるデータベースを用意します。検証・運用コストを抑えるため、使用した分だけ課金される「サーバーレス」構成を選択します。
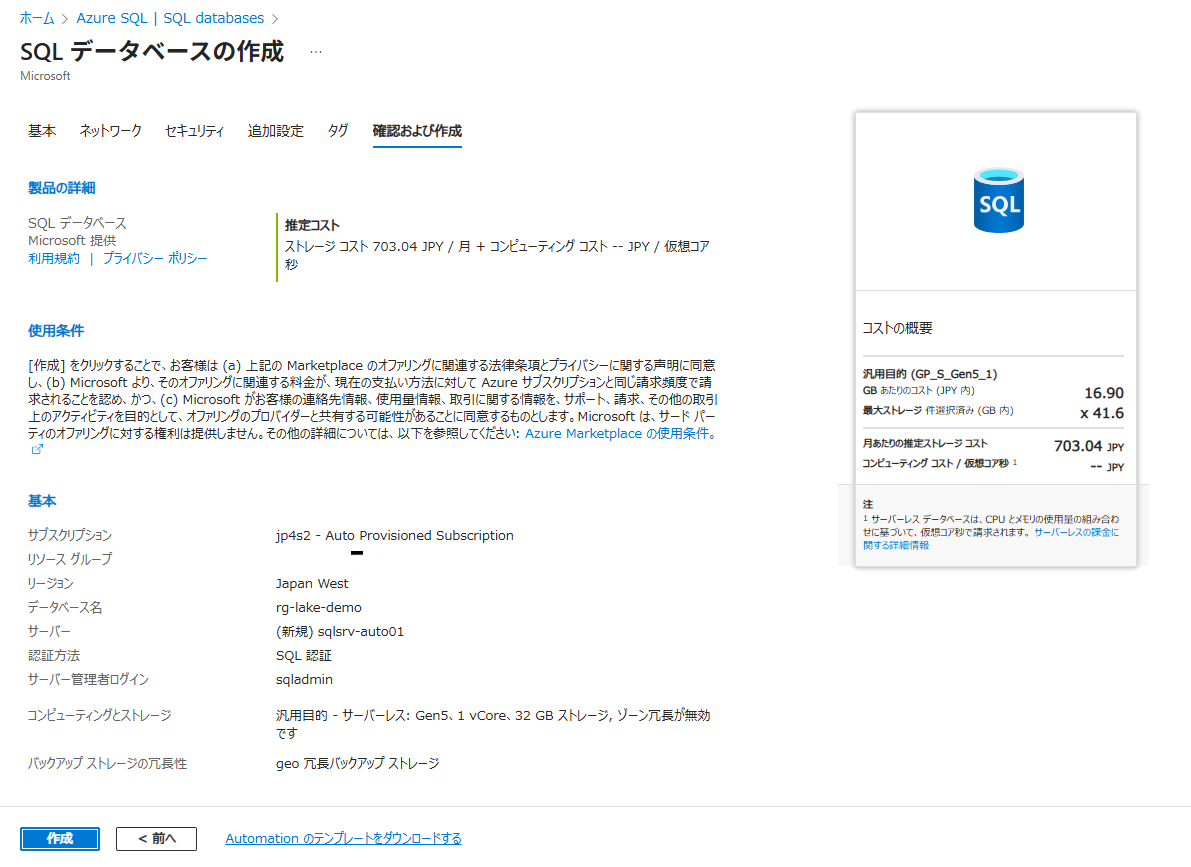
Azure ポータルから「SQL データベース」を新規作成します。論理サーバーを新規作成する際、後でクエリエディターを使うために SQL 認証(管理者アカウント)の設定を行っておきます。
- データベース名:
sqlauto - サーバー: 「新規作成」を選択し、以下を入力
- サーバー名:
sqlsrv-auto01 - 場所: ストレージと同一リージョンを推奨
- 認証方法: 「SQL 認証を使用する」を選択
- サーバー管理者ログイン:
sqladmin(任意) - パスワード: 任意の複雑なパスワード
- コンピューティングとストレージ: 「サーバーレス」を選択
- 自動一時停止: 有効(例: 1 時間)
入力後、「作成」を選択してデプロイを完了します。
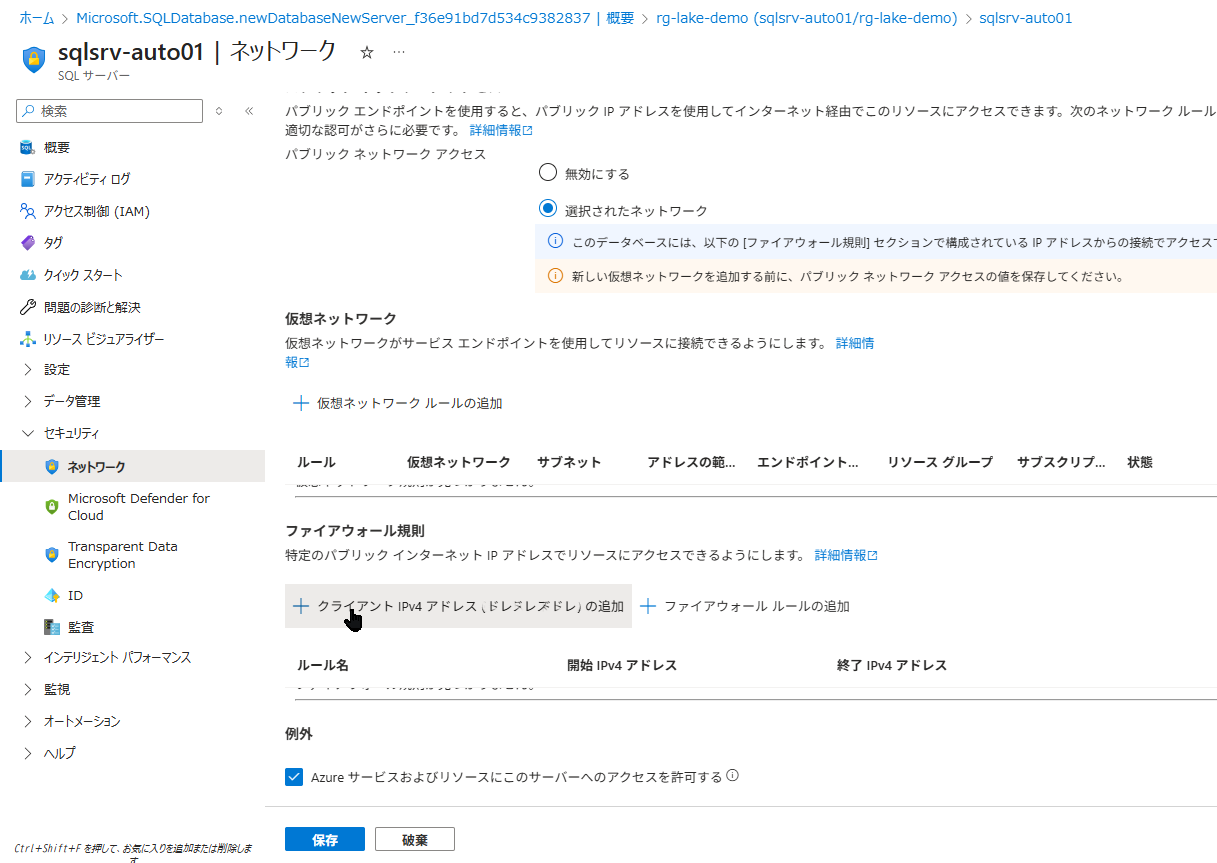
デプロイ後、ADF やご自身の PC から接続できるよう、ネットワークの許可設定を行います。
- SQL データベース(
sqlauto)の概要ページで、上部メニュー「サーバーのファイアウォールの設定」を選択します - 「Azure サービスおよびリソースにこのサーバーへのアクセスを許可する」をオンにします(ADF からの書き込みを許可する簡易な方法です)
- 「クライアントの IPv4 アドレスを追加する」を選択します(ご自身の PC からのクエリエディター操作のため)
- 左上の「保存」を選択します
補足: セキュリティを重視する場合
「Azure サービスを許可」は手軽ですが、Azure 全体からの接続を許容する設定です。運用環境では、後述の マネージド ID 認証+最小権限や、Private Endpoint との併用を検討することをおすすめします。
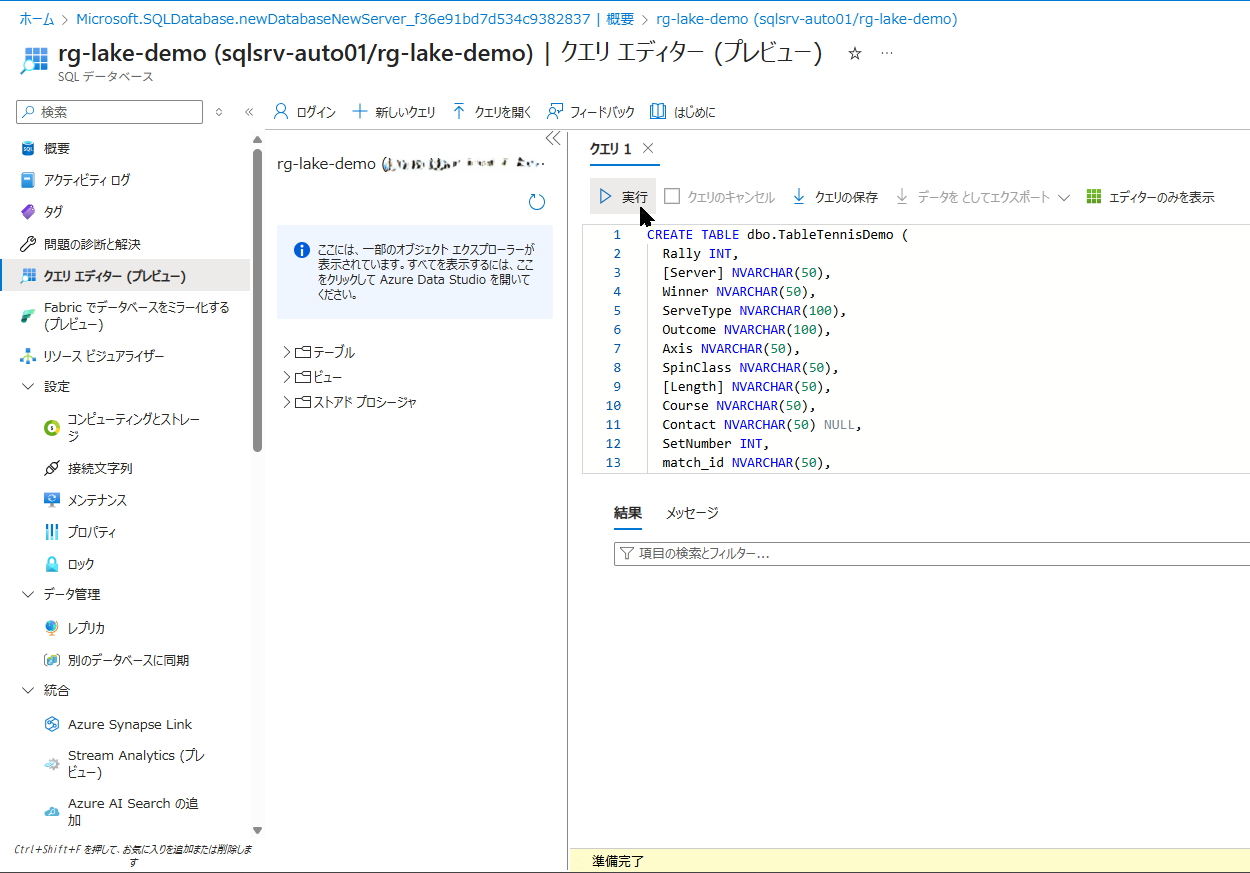
「クエリ エディター(プレビュー)」を開き、SQL 認証のユーザー名(sqladmin)とパスワードでログインします。以下の SQL を貼り付けて実行し、テーブルを作成します。
CREATE TABLE dbo.TableTennisDemo (
Rally INT,
[Server] NVARCHAR(50),
Winner NVARCHAR(50),
ServeType NVARCHAR(100),
Outcome NVARCHAR(100),
Axis NVARCHAR(50),
SpinClass NVARCHAR(50),
[Length] NVARCHAR(50),
Course NVARCHAR(50),
Contact NVARCHAR(50) NULL,
SetNumber INT,
match_id NVARCHAR(50),
created_at DATETIME2,
player NVARCHAR(50),
opponent NVARCHAR(50)
);
先ほどの SQL を消去し、以下の確認用クエリを実行します。結果ペインに cnt が 1 と表示されれば、受け入れ準備は完了です。
SELECT COUNT(*) AS cnt FROM sys.tables WHERE name = 'TableTennisDemo';Data Factory でパイプラインを構築する
ここからパイプラインを作成します。パラメータを使ってファイル名を動的に扱う点がポイントです。
Azure ポータルから「Data Factory」を作成し、概要画面の「スタジオの起動(Launch studio)」から ADF Studio を開きます。
- 名前:
adf-lakedemo - リージョン: 他リソースと同一リージョンを推奨
ADF からストレージとデータベースへアクセスするための接続情報(リンクサービス)を作成します。左メニューのカバン型アイコン「管理(Manage)」>「リンク サービス」>「+ 新規」から、以下の 2 つを作成します。
Azure Data Lake Storage Gen2 用
- 名前:
ls_adls - アカウント:
stlakedemo01
Azure SQL Database 用
- 名前:
ls_sqlauto - サーバー名:
sqlsrv-auto01/ データベース名:sqlauto - 認証: 手順で設定した SQL 認証情報を入力(より安全な構成は後述の「安全な接続構成」を参照)
読み込む CSV の定義を作成します。ファイル名を動的に受け取るためのパラメータ設定が重要です。
- 左メニューの鉛筆型アイコン「作成(Author)」を選択します
- 「ファクトリリソース」ペインの「+」>「データセット」を選択します
- 「Azure Data Lake Storage Gen2」>「CSV(区切りテキスト)」を選択します
- 名前を
ds_raw_csv、リンクサービスをls_adlsに設定し、ファイルパスは空欄のまま「OK」を選択します - 「パラメーター」タブの「+ 新規」から、
folder(String)とfile(String)を追加します - 「接続」タブのファイルパス入力欄で「動的なコンテンツの追加」を選択し、次のように設定します
- ディレクトリ欄:
@dataset().folder - ファイル名欄:
@dataset().file
Directory = などの文字は含めず、@ から始まる値のみを入力します。
書き込み先の定義を作成します。
- 同様に「+」>「データセット」から「Azure SQL Database」を選択します。
- 名前を
ds_sql_tennis、リンクサービスをls_sqlautoに設定します。 - テーブル名に
dbo.TableTennisDemoを選択して「OK」を選択します。
データコピージョブを組み立てます。
- 「+」>「パイプライン」>「パイプライン」を選択し、名前を
pl_inbox_to_sqlとします - キャンバスの空白を選択し、「パラメーター」タブから
p_folder(String)とp_file(String)を追加します - アクティビティ一覧の「移動と変換」から「データのコピー(Copy data)」をキャンバスへドラッグ&ドロップします
- 配置した「データのコピー」を選択し、設定ペインを入力します
- ソースタブ: ソースデータセットに
ds_raw_csvを選択。データセットプロパティに動的コンテンツで値を割り当てfolderの値:@pipeline().parameters.p_folderfileの値:@pipeline().parameters.p_file
- シンクタブ: シンクデータセットに
ds_sql_tennisを選択
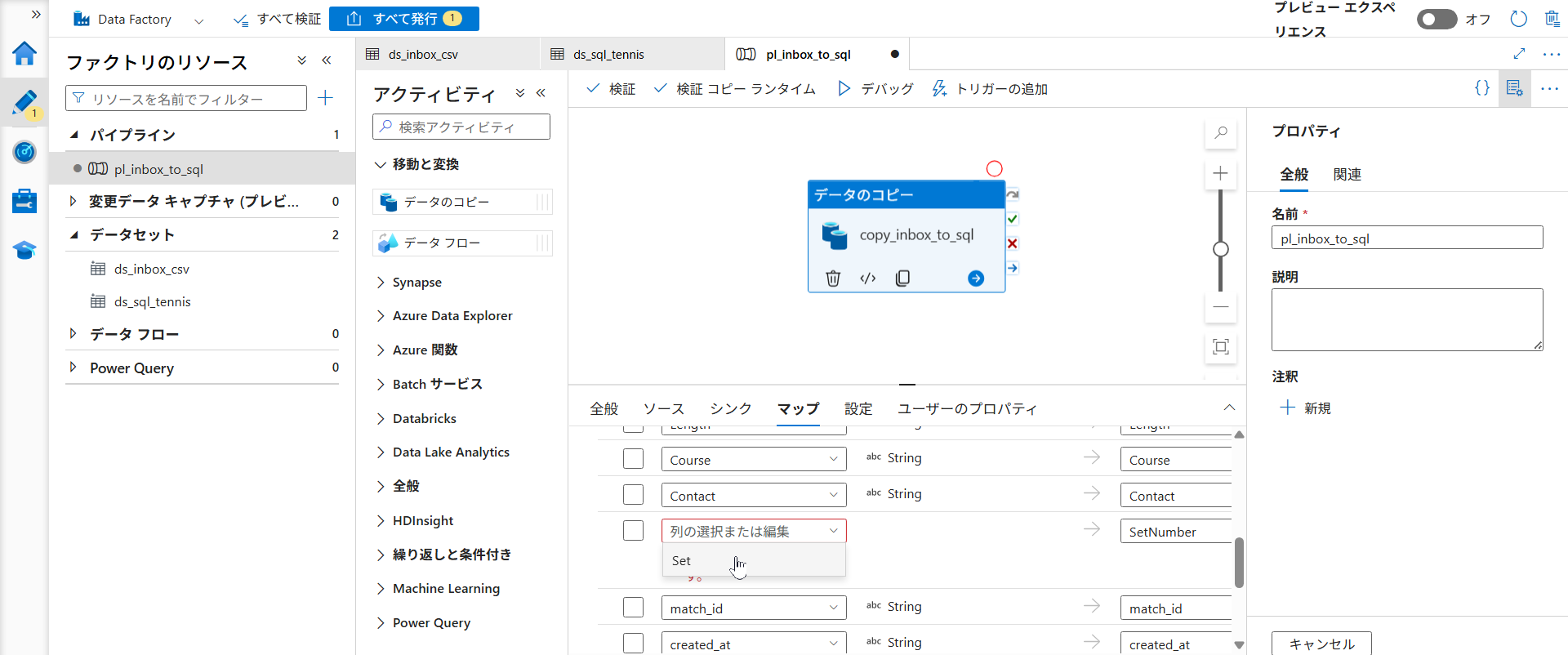
CSV の列とデータベースの列を紐付けます。
スキーマをインポートするため、あらかじめ raw/inbox/ に、テスト用 CSV(demodata.csv)をアップロードしておきます。
- 「データのコピー」を選択した状態で「マッピング」タブを開きます
- 「スキーマのインポート」を選択します。パラメータの仮の値を求められるので、以下を入力します
p_folder:raw/inbox(またはinbox※構成に合わせて)p_file:demodata.csv
- 読み込まれた列一覧で、CSV 側の「Set」列を、SQL 側の「SetNumber」に手動で紐付け直します
- 左上の「すべて発行(Publish all)」を選択して保存(デプロイ)します。
安全な接続構成(マネージド ID で SQL へ接続)
上記では SQL 認証での接続を紹介しましたが、運用環境では、資格情報を持たない マネージド ID 認証が推奨されます。
参考: Configure managed identity(Microsoft Learn)
“Authentication with managed identities for Azure resources is the recommended authentication method for programmatic access to SQL.”
(マネージド ID による認証は、SQL へのプログラムによるアクセスで推奨される認証方法です。)
https://learn.microsoft.com/en-us/training/modules/explore-security-practices-azure-sql-database/3-configure-managed-identity
ADF には作成時にシステム割り当てマネージド ID が付与されます。この ID に対して、SQL 側でユーザーを作成し、最小限のロールを割り当てる流れです。
論理サーバー(sqlsrv-auto01)の「Microsoft Entra ID」設定で、Entra 管理者(自分のアカウントなど)を設定します。マネージド ID ユーザーの作成には Entra 認証でのログインが必要になるためです。
クエリエディターや SSMS から Microsoft Entra 認証でログインし、対象データベース(sqlauto)で以下を実行します。[adf-lakedemo] は ADF の名前(=マネージド ID 名)に置き換えます。
CREATE USER [adf-lakedemo] FROM EXTERNAL PROVIDER;
ALTER ROLE db_datareader ADD MEMBER [adf-lakedemo];
ALTER ROLE db_datawriter ADD MEMBER [adf-lakedemo];書き込みのみで足りる場合は、db_datawriter だけに絞ると、より最小権限に近づきます。
ADF Studio の SQL Database 用リンクサービス(ls_sqlauto)を開き、「認証の種類」で 「システム割り当てマネージド ID」 を選択します。サーバー名・データベース名を入力し、「接続のテスト」が成功することを確認します。資格情報をリンクサービスに保持しなくなる分、SQL 認証のみの構成よりも安全性が高まります。
イベントトリガーの設定
ファイルが配置されたことを検知して、パイプラインが自動で動くように設定します。
- ADF Studio の左メニュー「管理(カバン型アイコン)」>「トリガー」>「+ 新規」を選択します
- 以下の内容で設定します
- 名前:
trg_inbox_to_sql - 種類: ストレージイベント
- ストレージアカウント名:
stlakedemo01 - コンテナー名:
raw - BLOB パスの末尾:
.csv(CSV ファイルのみを対象)
- 「次へ」進み、実行するパイプラインに
pl_inbox_to_sqlを選択します - トリガーが検知したファイル情報をパイプラインに渡すため、パラメーター設定で以下を入力します
p_file:@triggerBody().fileNamep_folder:@triggerBody().folderPath
参考: Create event-based triggers – Azure Data Factory(Microsoft Learn)
“The storage event trigger captures the folder path and file name of the blob into the properties @triggerBody().folderPath and @triggerBody().fileName.”
(ストレージイベントトリガーは、Blob のフォルダーパスとファイル名を@triggerBody().folderPathと@triggerBody().fileNameに取得します。)
https://learn.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger
folderPath は先頭にコンテナー名(raw/)が含まれるため、パスがずれる場合があります。その場合は @replace(triggerBody().folderPath, 'raw/', '') のように replace 関数で調整します。
Tip: Synapse の場合は式が異なる
同じ仕組みを Azure Synapse Analytics で作る場合は、@trigger().outputs.body.fileNameと@trigger().outputs.body.folderPathを使用します。
- 設定を完了し、左上の「すべて発行」を選択して保存します。
- トリガーの状態が「開始済み(有効)」になっていることを確認します。
トリガー種別の選定
ADF には複数のトリガー種別があります。用途に応じて選ぶとよいでしょう。
| トリガー種別 | 向いている用途 |
|---|---|
| ストレージイベント | ファイルの配置・削除を検知して即時起動(本記事の方式) |
| スケジュール | 定刻バッチ(毎日 0 時など、決まった時刻の実行) |
| タンブリングウィンドウ | 時間枠ごとの連続処理や、実行間の依存関係を管理したい場合 |
| カスタムイベント | Event Grid のカスタムイベントを起点にしたい場合 |
「ファイルが届いたら即座に取り込みたい」という今回の要件には、ストレージイベントトリガーが適しています。
Power BI との連携
SQL Database に蓄積されたデータを、Power BI で可視化します。
データが追加されたらすぐにグラフへ反映されるよう、リアルタイム性を重視した「DirectQuery」モードを使用します。
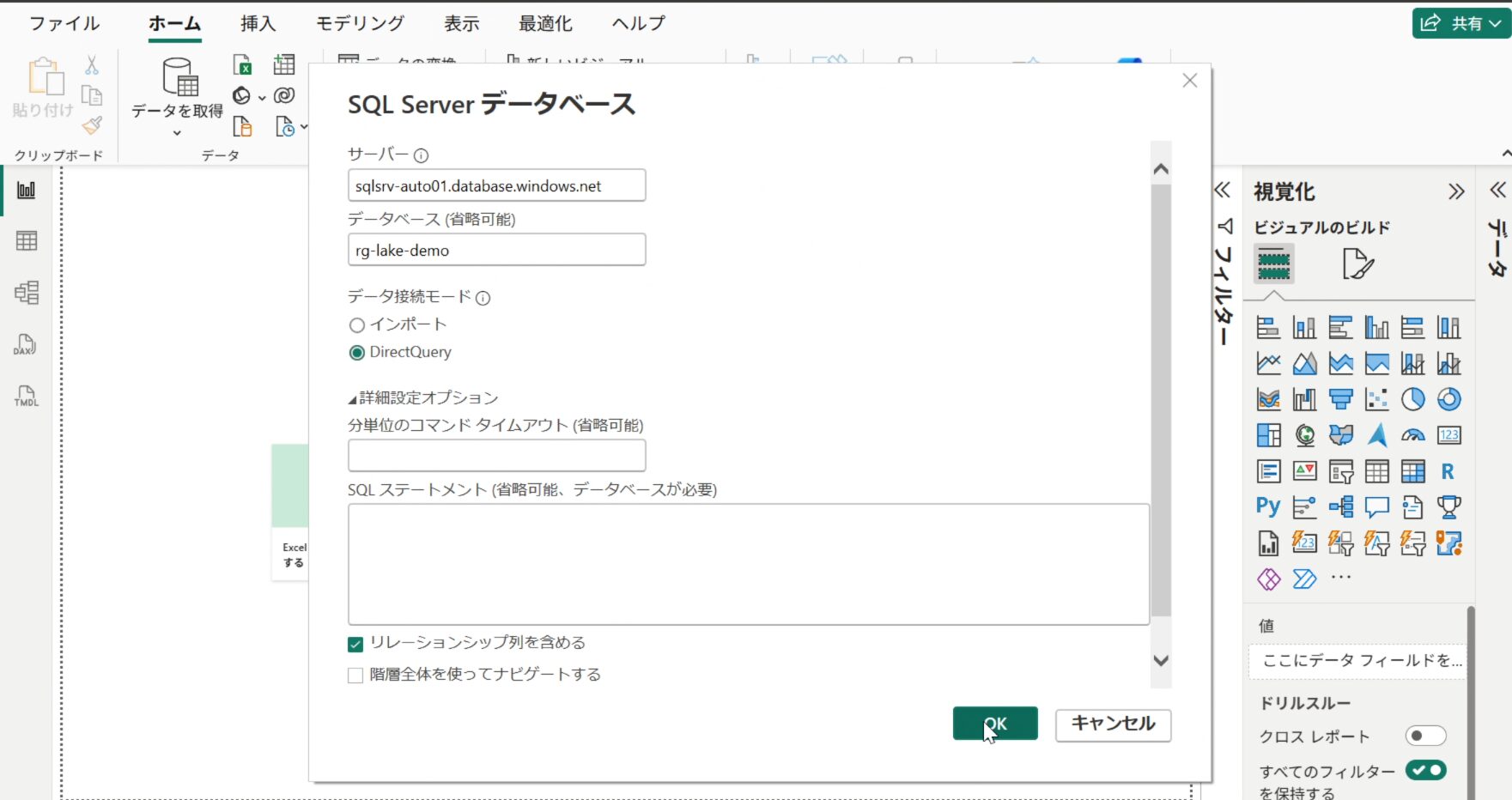
- Power BI Desktop を起動し、「データの取得」>「Azure」>「Azure SQL データベース」を選択します
- 以下を入力して接続します
- サーバー:
sqlsrv-auto01.database.windows.net - データベース:
sqlauto - データ接続モード: DirectQuery
- 認証画面で「データベース」タブを選択し、SQL 認証情報(
sqladmin/ パスワード)でログインします。
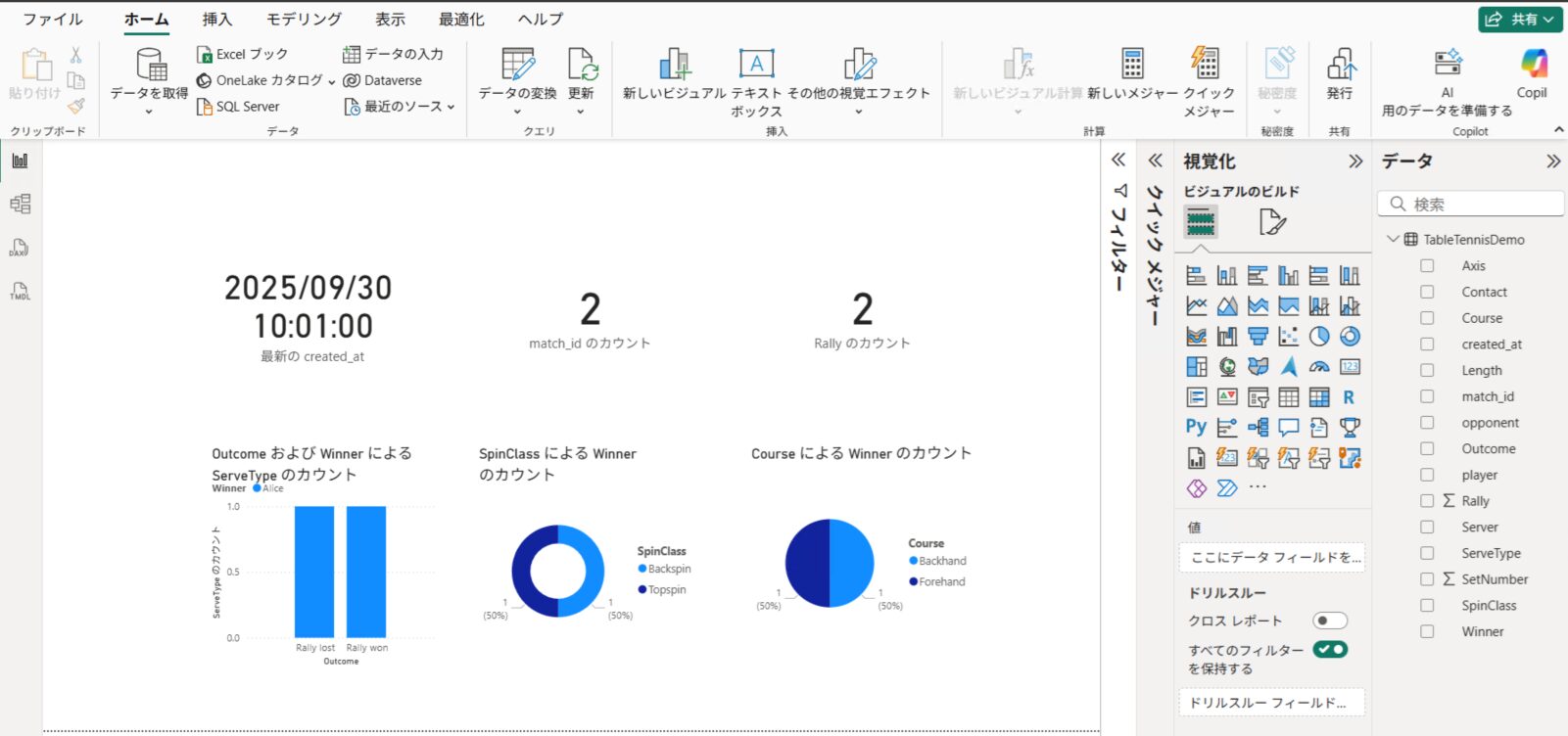
ナビゲーターで dbo.TableTennisDemo テーブルを選択して読み込み、右側のフィールド一覧から項目をキャンバスにドラッグして、グラフや表を作成します。
なお、Power BI 側で Copilot を使った対話型の分析を行う方法は、関連記事『Power BI Copilot でできること|AI 分析とレポート作成の手順』で解説しています。
更新方式の使い分け(DirectQuery / Import)
可視化側の更新方式は、リアルタイム性とコスト・パフォーマンスのバランスで選びます。
| 方式 | 特徴 | 向いているケース |
|---|---|---|
| DirectQuery | クエリのたびに SQL へ問い合わせ、最新データを反映 | 取り込み直後の鮮度を重視する場合 |
| Import | データを Power BI 側に取り込み、スケジュール更新 | 応答速度やレポート負荷を重視する場合 |
DirectQuery は鮮度に優れる一方、ソース(サーバーレス SQL)への問い合わせが増えます。サーバーレス構成では、アクセス頻度が自動一時停止やコストに影響する場合がある点に留意します。
動作確認とクリーンアップ
新しい CSV を配置して自動反映を確認する
実際に新しいファイルを配置し、Power BI まで自動反映されるかをテストします。
Azure ポータルなどから、raw/inbox/ に新しいファイル(例: demodata_new.csv)をアップロードします。
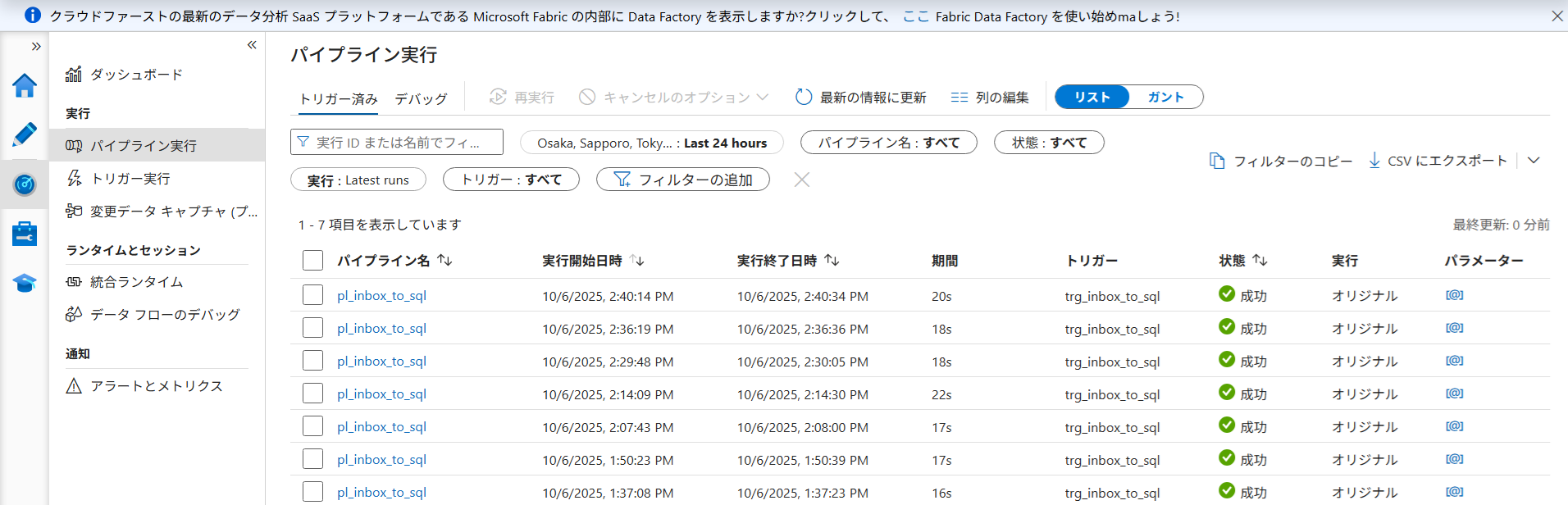
ADF Studio の「監視(メーター型アイコン)」を開き、パイプラインが自動起動してステータスが「Succeeded(成功)」になっていることを確認します。
Power BI Desktop 上部の「更新」を選択し、追加したデータの分だけグラフが変化することを確認します。
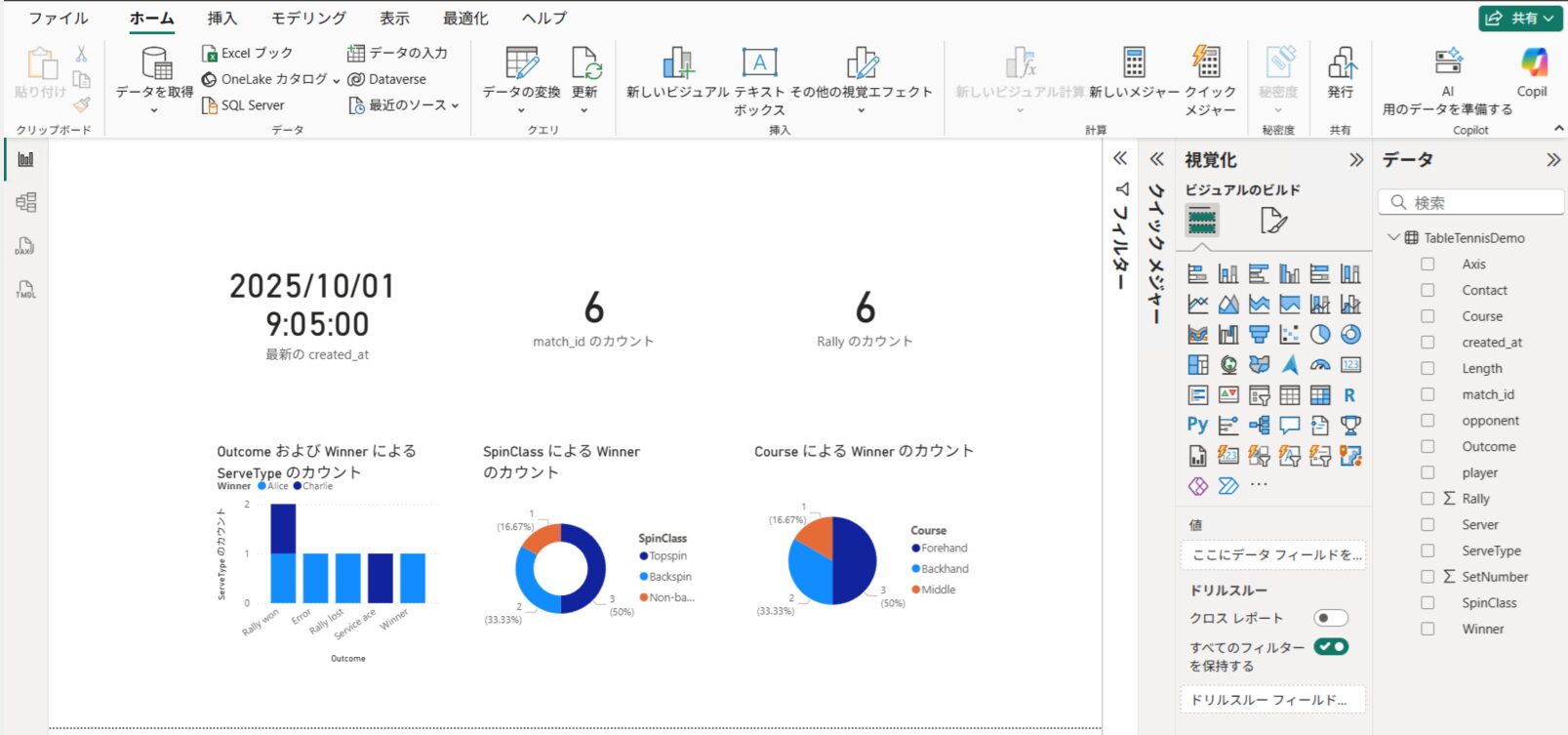
新しく投入する CSV の列名は、元のサンプルデータと同じである必要があります。マッピングで「Set」列を「SetNumber」に変換する設定にしているため、CSV 側の列名は「Set」のままで問題ありません。CSV 側を「SetNumber」に書き換えると、ADF が「Set という列が存在しない」と判断してエラーになります。
データ削除(クリーンアップ)
検証を繰り返してデータが重複した場合、以下の方法でリセットできます。
方法 1: 手動で削除
クエリ エディターから SQL を実行します。テーブルを空にする場合は次のとおりです。
TRUNCATE TABLE dbo.TableTennisDemo;特定の日付以前のみ削除する場合は次のとおりです。
DELETE FROM dbo.TableTennisDemo
WHERE created_at < '2025-09-30';方法 2: ADF で自動削除
取り込み前に既存データを消す構成です。「Copy data」アクティビティの前段に Script Activity を追加し、TRUNCATE TABLE dbo.TableTennisDemo; を設定すると、常にクリーンな状態で検証でき、テスト環境で役立ちます。
まとめ
今回の仕組みにより、「指定フォルダに CSV を配置するだけ」でデータが自動的に SQL へ格納され、Power BI で最新状況を可視化する一連のパイプラインを構築できました。
- イベント検知: Blob へのファイル配置をストレージイベントトリガーで検知できる
- 前提: トリガーには Event Grid リソースプロバイダーの登録が必要
- 動的受け渡し: パラメータと動的コンテンツで、ファイル名を柔軟に受け渡せる
- 安全な接続: マネージド ID 認証を使うと、資格情報を持たずに SQL へ接続できる
- マッピング: 列名が異なっても、マッピング設定で変換して取り込める
- 可視化: DirectQuery により、SQL の最新データを Power BI へ反映できる
以上、最後までお読みいただきありがとうございました。

