

はじめに
仮想化基盤の設計や運用に携わるエンジニアにとって、避けて通れないテーマの 1 つが「オーバーコミット」です。
物理サーバーが持つリソース量を超えて仮想マシンへリソースを割り当てることで、リソース利用効率の向上とインフラコストの削減につながる技術です。一方、過度な集約はパフォーマンス低下や障害につながる可能性があり、バランスの取り方が問われます。
2024 年以降は、Broadcom による VMware 買収を契機にライセンス体系が「コア単位課金」へ変わり、オーバーコミット設計の重要性は従来以上に高まっています。物理コアの増設がそのままライセンス費用に跳ね返る構造になったため、限られたリソースを効率的に集約する設計力が、インフラ予算の最適化に直結する状況です。
本記事では、最新のライセンス体系の影響も踏まえ、パフォーマンスとコストを両立させるオーバーコミット設計の考え方を、実務的な視点で整理します。
- オーバーコミットの仕組みとコスト削減のメリット
- Broadcom 買収後のコア単位課金がオーバーコミット設計に与える影響
- CPU と メモリ で異なる設計指針
- 推奨される vCPU/pCPU 比率と運用時のチェックポイント
- esxtop でのリアルタイム実測コマンド
- 現場で見られる NG 設計パターン
オーバーコミットの仕組みとコスト削減のメリット
「オーバーコミット」とは、物理ホストが実際に持っているリソース量を超えて、仮想マシンにリソースを割り当てる技術です。例えば、物理 CPU が 10 コアしかないサーバー上で、仮想マシン 4 台に「4 コアずつ(合計 16 コア)」割り当てるような状態を指します。物理的には足りていないはずですが、仮想化環境ではこれが成立します。
参考: メモリのオーバーコミット(Broadcom Tech Docs)
“ESXi hosts can be configured to enable up to 300 percent memory overcommitment without any performance degradation.”
(ESXi ホストはパフォーマンス劣化を伴わずに最大 300% のメモリオーバーコミットを設定可能)
https://docs.vmware.com/jp/VMware-vSphere/5.5/com.vmware.vsphere.resmgmt.doc/GUID-895D25BA-3929-495A-825B-D2A468741682.html
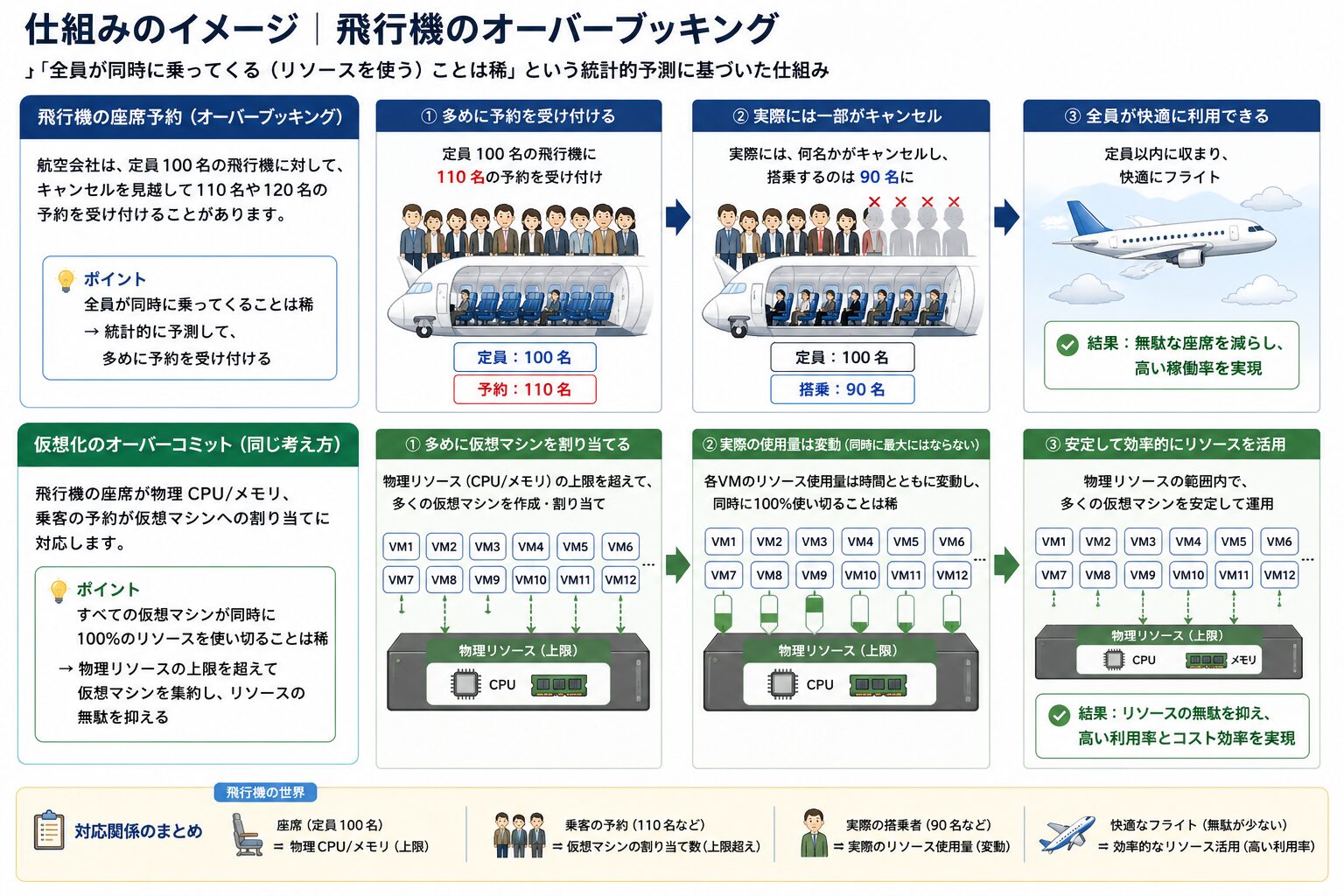
仕組みのイメージ|飛行機のオーバーブッキング
この仕組みは、飛行機の座席予約(オーバーブッキング)に例えられます。
航空会社は、定員 100 名の飛行機に対して、キャンセルを見越して 110 名や 120 名の予約を受け付けることがあります。これは「全員が同時に乗ってくる(リソースを使う)ことは稀」という統計的予測に基づいた仕組みです。
仮想化もこれと同じ考え方で、飛行機の座席が物理 CPU/メモリ、乗客の予約が仮想マシンへの割り当てに対応します。「すべての仮想マシンが同時に 100% のリソースを使い切ることは稀」という前提のもと、物理リソースの上限を超えて仮想マシンを集約することで、リソースの無駄を抑えます。
インフラコスト圧縮のメリット
多くのサーバー(特に Web サーバーや開発環境など)は、一日中 CPU をフル稼働させているわけではありません。稼働率が 10〜20% 程度のアイドルタイムが大半を占めるケースも珍しくありません。
オーバーコミットを活用すれば、この使われていない時間を他の仮想マシンに割り当てることができるため、少ない物理サーバーでより多くの仮想マシンを稼働させることが可能です。結果として、ハードウェア購入費、データセンターのラック費用、電気代といったインフラコストの圧縮につながります。
Broadcom 買収後のコア単位課金がオーバーコミット設計に与える影響
ここが、本記事で特に強調したいポイントです。2024 年以降、オーバーコミット設計は単なる技術の最適化ではなく、ライセンスコストの最適化と密接に関わる課題になりました。
ライセンス体系の主な変更点
2023 年 11 月に Broadcom による VMware 買収が完了し、2024 年 2 月以降、VMware 製品のライセンス体系は以下のように変更されています。
| 項目 | 旧体系(〜2024 年 2 月) | 新体系(2024 年 2 月〜) |
|---|---|---|
| 課金単位 | CPU ソケット単位 | CPU コア単位 |
| 提供形態 | 永続ライセンス+保守 | サブスクリプションのみ(1/3/5 年) |
| 最低購入数 | ソケットごとに購入 | 1 CPU あたり最低 16 コア → 2025 年 4 月以降は 72 コア |
| 製品ライン | 160 以上の製品 | VCF / VVF の 2 エディションに集約 |
特に影響が大きいのが、「コア単位課金」と「最低 72 コア購入」のルールです。
参考: VMware by Broadcom 製品ラインアップとライセンスモデルの変更(VMware Japan Blog)
「2024 年 2 月 4 日より、永久ライセンスの販売とサポート&サブスクリプション(SnS)の更新が終了し、サブスクリプションまたは有期ライセンスのみ提供されます。」
https://blogs.vmware.com/vmware-japan/2024/02/vmware-by-broadcom-business-transformation.html
設計に与える 3 つの影響
旧体系では、CPU はソケット数で課金されていたため、「コア数の多い高性能 CPU を選んで集約率を上げる」のがコスト最適解でした。1 ソケットに 32 コア載っていても 64 コア載っていても、ライセンス費用は同じだったためです。
しかし新体系では、コアを増やすほどライセンス費用が増える構造に変わりました。これは設計に 3 つの影響を与えます。
① 物理コアの増設がそのまま費用増につながる
従来は安全マージンとして物理コアを多めに積む選択肢が現実的でした。新体系では、その追加コアが直接ライセンス費用に反映されます。
② オーバーコミット率を引き上げる経済的動機が増大
ライセンス費用を抑えるには、物理コア数を可能な限り絞り込み、その分を仮想化で集約する設計が求められます。従来 3:1 で運用していた現場でも、4:1 や 5:1 への引き上げが現実的な選択肢になりつつあります。
③ サイジング誤差のコストが二重に発生
物理コアを過剰に積めばライセンス費用が無駄になり、不足すれば業務影響が発生します。サイジング誤差のペナルティが、ハードウェア費用とライセンス費用の両方で発生する構造に変わりました。
新体系下で推奨される設計アプローチ
以上を踏まえると、新体系下では以下のアプローチをおすすめします。
- 既存環境の実 CPU 使用率を計測し、割り当て vCPU ではなく実消費をベースに集約率を決める
- CPU Ready Time / co-stop の継続監視で、集約率の安全性をデータで担保する
- NUMA 境界を意識した VM 配置で、物理コア数を増やさずに性能を引き出す(後述)
- メモリは引き続き保守的に設計する(メモリは課金対象外のため、過度な節約は推奨しません)
オーバーコミット設計には、コストとパフォーマンスのバランスを取るメリハリある判断が、これまで以上に求められるようになっています。
CPU とメモリで異なる設計指針
オーバーコミットを設計する際、CPU とメモリを同じ感覚で扱うことは推奨できません。両者はハードウェアとしての性質が異なるため、CPU は積極的に、メモリは保守的にというスタンスで設計するのが定石です。
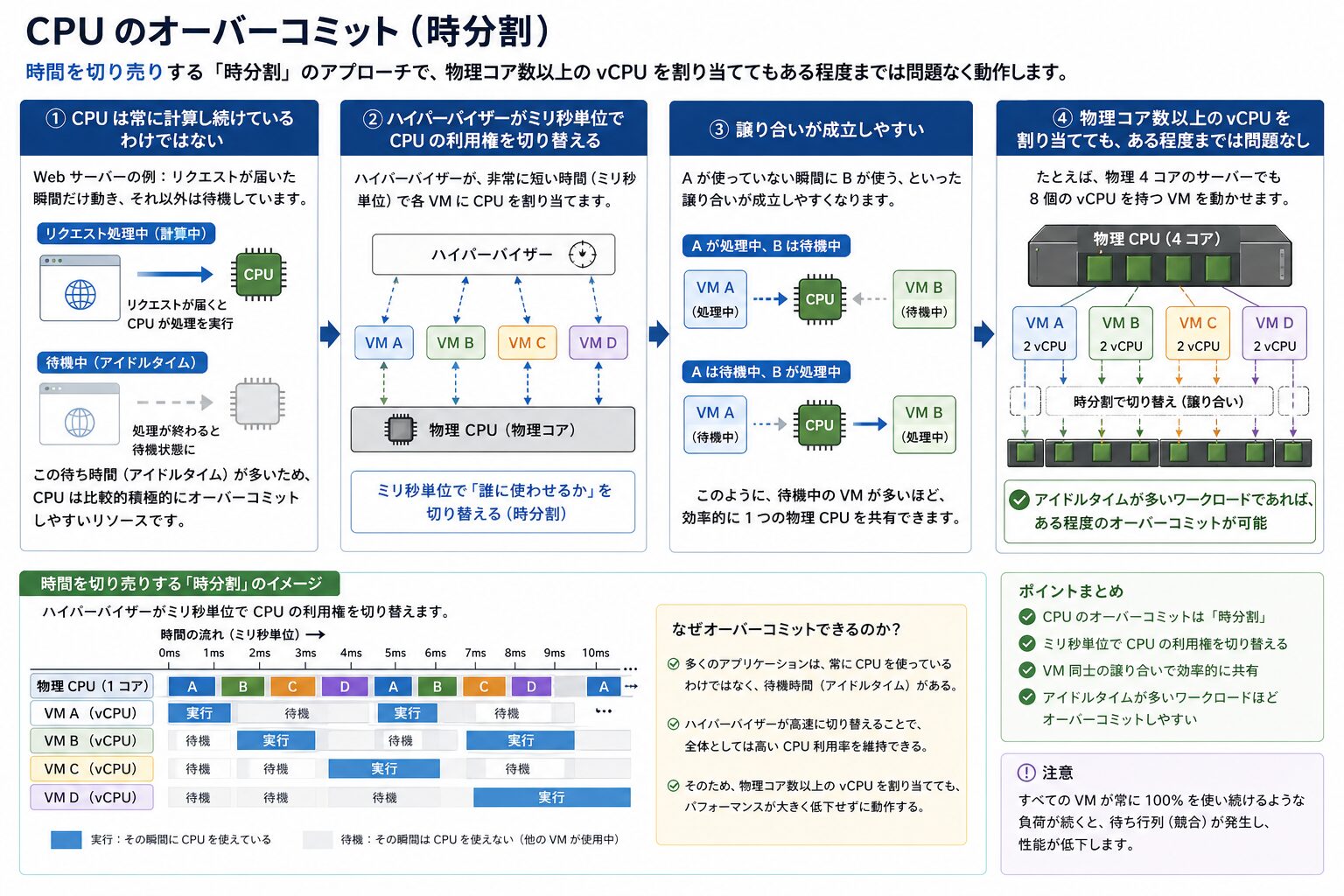
CPU のオーバーコミット(時分割)
CPU のオーバーコミットは、時間を切り売りする「時分割」のアプローチです。
CPU は常に計算し続けているわけではありません。Web サーバーであればリクエストが届いた瞬間だけ動き、それ以外は待機しています。この計算していない待ち時間(アイドルタイム)が多いため、CPU は比較的積極的にオーバーコミットしやすいリソースです。
ハイパーバイザーがミリ秒単位で CPU の利用権を各 VM に切り替えるため、A という VM が使っていない瞬間に B という VM が使う、といった譲り合いが成立しやすく、物理コア数以上の vCPU を割り当ててもある程度までは問題なく動作します。
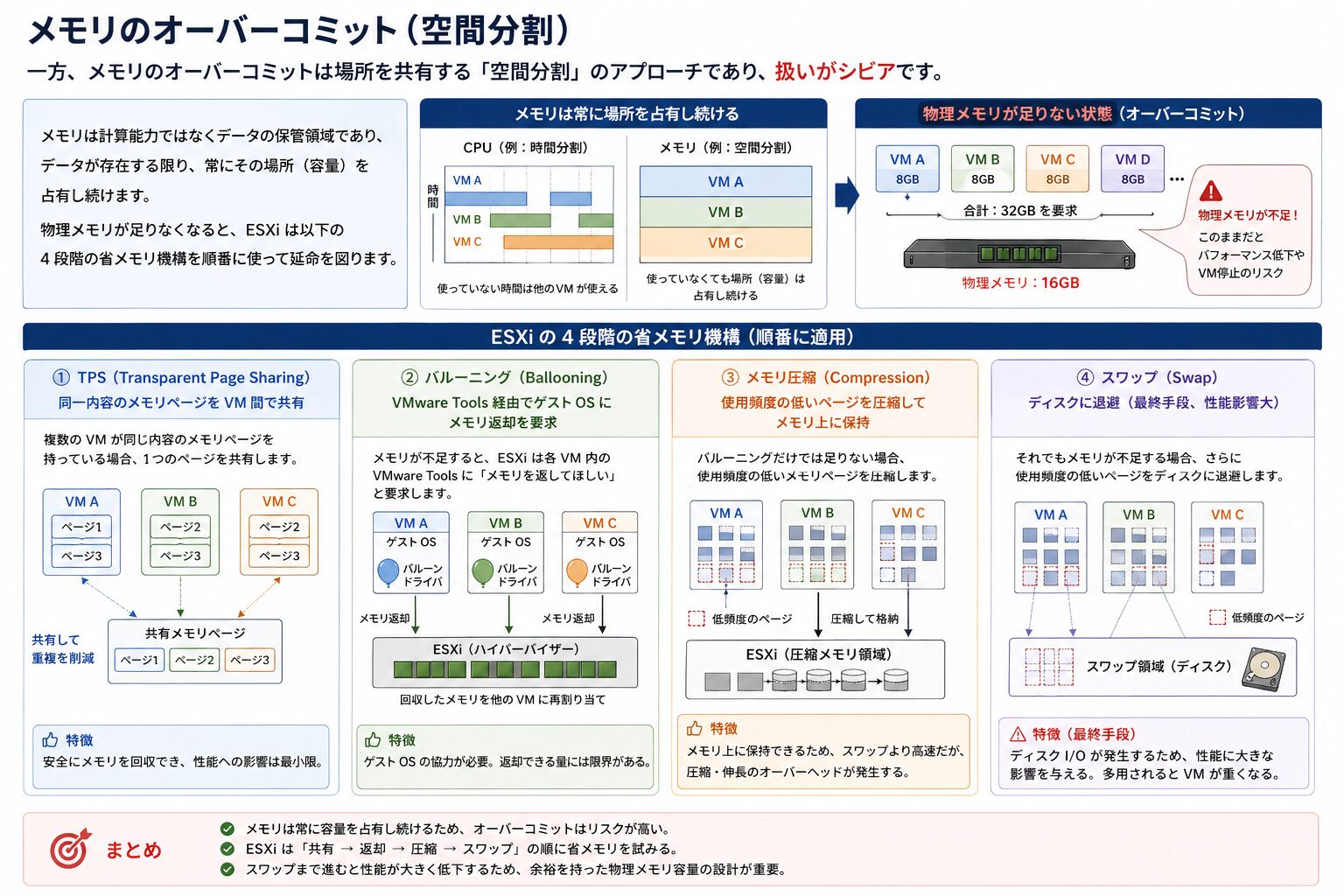
メモリのオーバーコミット(空間分割)
一方、メモリのオーバーコミットは場所を共有する「空間分割」のアプローチであり、扱いがシビアです。
メモリは計算能力ではなくデータの保管領域であり、データが存在する限り、常にその場所(容量)を占有し続けます。物理メモリが足りなくなると、ESXi は以下の 4 段階の省メモリ機構を順番に使って延命を図ります。
- TPS(Transparent Page Sharing): 同一内容のメモリページを VM 間で共有
- バルーニング(Ballooning): VMware Tools 経由でゲスト OS にメモリ返却を要求
- メモリ圧縮(Compression): 使用頻度の低いページを圧縮してメモリ上に保持
- スワップ(Swap): ディスクに退避(最終手段、性能影響大)
注意点として、vSphere 6.0 以降、TPS はセキュリティ上の理由(サイドチャネル攻撃対策)から VM 間共有がデフォルト無効化されています。「TPS があるからオーバーコミットしても大丈夫」という古い知識は通用しません。
最終的にスワップが発生すると、ディスク I/O はメモリの数百倍から数千倍遅いため、システムのパフォーマンスは大きく低下します。
参考: メモリのオーバーコミットによるパフォーマンス影響(Broadcom Knowledge Base)
“Memory overcommitment can lead to host swapping, which significantly degrades virtual machine performance.”
(メモリのオーバーコミットはホストスワップを引き起こし、仮想マシンのパフォーマンスを大きく低下させる)
https://knowledge.broadcom.com/external/article/313014
パフォーマンス低下が許されない本番環境(特に DB サーバーなど)では、メモリのオーバーコミットは原則避け、物理メモリ容量の範囲内で設計する(メモリ予約をする)ことをおすすめします。
推奨される vCPU/pCPU 比率と早見表
実際にどのくらいまで集約してよいかは、ワークロードによって異なります。代表的な推奨値と簡易計算例を紹介します。
CPU の目安(vCPU : pCPU)
| ワークロード | 推奨比率 | 重視点 | 補足 |
|---|---|---|---|
| ミッションクリティカル(DB / 基幹) | 1:1 〜 2:1 | パフォーマンス・安定性 | CPU 予約の併用も検討 |
| 一般サーバー(Web / AP / ファイル) | 3:1 〜 5:1 | コストと性能のバランス | 多くの企業の標準 |
| 開発・検証環境 | 5:1 〜 8:1 | コスト削減 | ピーク重複に注意 |
| VDI(仮想デスクトップ) | 5:1 〜 10:1 | 高集約 | 思考時間が長く集約しやすい |
なお、最新世代の Intel Xeon Scalable や AMD EPYC ではコア性能が向上しているため、上記目安より高めの比率(一般サーバーで 5:1 など)でも快適に動作するケースが増えています。詳細は関連記事「VMware vSphere バージョン別サポート対応 CPU 一覧」もあわせてご確認ください。
サイジング簡易計算例
物理 20 コア × 2 ソケット(合計 40 コア)の ESXi ホストを、一般業務の Web/AP サーバー用途で使う場合を考えます。
集約率 4:1 で設計した場合、
- 割り当て可能 vCPU 総数: 40 × 4 = 160 vCPU
- 1 VM が 4 vCPU なら、最大 40 VM を集約可能
- HA 用バッファ 25% を確保すると、運用 VM 数は 30 VM 程度が目安
実務では、上記から「VM ごとの想定 CPU 使用率」を掛け合わせて妥当性を判断します。例えば平均 CPU 使用率 20% の VM を 30 台運用する場合、ピーク時の同時稼働を考慮しても物理 40 コアで処理できる、という見立てが成り立ちます。
NUMA 境界の落とし穴|vCPU は 1 ソケットあたりのコア数を上限に
現場で見落とされやすいポイントが NUMA(Non-Uniform Memory Access)境界です。
最近のサーバー CPU は NUMA 構造を採用しており、各 CPU ソケットが自分専用のメモリ領域を持っています。1 つの VM に割り当てる vCPU 数が「1 ソケットあたりの物理コア数」を超えると、その VM は複数の NUMA ノードをまたぐ状態となり、ソケット間のメモリアクセス(リモートアクセス)が発生してメモリレイテンシが増加します。
具体例として、
- ホスト構成: 20 コア × 2 ソケット
- VM に 24 vCPU を割り当てた場合: 1 ソケット(20 コア)に収まらず、性能劣化が発生
- VM に 16 vCPU に抑えた場合: 1 ソケットに収まり、NUMA ローカル動作で高速
「VM が遅いから vCPU を増やす」という判断が逆効果になる典型的なパターンです。vCPU 数は、原則として 1 NUMA ノード内に収めることをおすすめします。
メモリの目安(vRAM : pRAM)
| 環境 | 推奨比率 | 補足 |
|---|---|---|
| 本番環境(特に DB) | 1:1(オーバーコミットなし) | スワップリスクをゼロに |
| 一般本番 | 1:1 〜 1:1.2 | バルーニング許容範囲 |
| 開発・検証 | 1:1.5 〜 1:2 | 監視前提 |
メモリは枯渇するとパフォーマンス劣化に直結するため、保守的な設計を基本とします。前述のとおり Broadcom 新体系ではメモリは課金対象外のため、メモリは十分に搭載してオーバーコミットを避ける方針が、現代的な選択肢です。
esxtop で確認するリアルタイム実測コマンド
推奨値を守っていても、実際のシステムが健全に動いているかは実測して確認する必要があります。VMware 環境で標準的に使われる実測ツールが esxtop です。SSH で ESXi ホストにログインして実行します。
CPU の状態を見る
# ESXi ホストに SSH でログイン後
esxtop
# 実行後、以下のキーを押す
# c : CPU 表示モード(デフォルト)
# f : 表示項目選択(必要に応じて %CSTP などを追加)
# V : VM 単位で表示| 指標 | 意味 | 注意水準(公式・一般指標) |
|---|---|---|
| %RDY | CPU を使いたいのに待たされた時間の割合 | vCPU あたり 10% を超えると要注意(公式: 10〜15% / vCPU) |
| %CSTP | co-stop(兄弟 vCPU 同期待ち)の割合 | vCPU あたり 5% を超えると vCPU 過剰割り当ての疑い |
| %USED | 実際に CPU を使った割合 | 100% 近辺が継続するなら過負荷 |
| %MLMTD | リソース制限による待ち時間 | 0 が理想 |
参考: esxtop データの解釈ガイドライン(Broadcom Tech Docs)
“%RDY should be less than 10%-15% per vCPU. %CSTP should be less than 5% per vCPU.”
(%RDY は vCPU あたり 10〜15% 未満、%CSTP は vCPU あたり 5% 未満が目安)
https://docs.vmware.com/en/VMware-Smart-Assurance/10.1.0/ip-manager-delopment-guide-101/GUID-8F62BA71-5C6B-41DE-9B9B-0BF24ADD743B.html
%RDY は、VM が「計算処理をしたいのに、物理 CPU が空いていないため待たされている時間」を示します。オーバーコミット環境で注視すべき指標の 1 つで、推奨値の範囲内でもこの値が高ければ、体感できるレベルで遅延が発生します。
%CSTP は co-stop の指標です。仮想化基盤には「割り当てた vCPU 分の物理コアが同時に空くまで処理を待たせる」という挙動(Co-scheduling)があり、多くの vCPU を割り当てると「全員揃うまでの待ち時間」が増えます。%CSTP が高い場合は、vCPU 数を減らす方向での見直しをおすすめします。
メモリの状態を見る
esxtop
# m : メモリ表示モードに切り替え| 指標 | 意味 | 注意水準 |
|---|---|---|
| MCTLSZ | バルーニングで回収されたメモリ量 | 0 以外なら既にメモリ圧迫 |
| SWCUR | スワップアウト中のメモリ量 | 0 以外は深刻な状態 |
| SWR/s | スワップイン速度 | 0 以外は VM パフォーマンス劣化中 |
| N%L | NUMA ローカルアクセス率 | 80% 未満なら NUMA 設計を見直し |
SWR/s が 1 でも観測されたら、その瞬間に VM は遅延しています。緊急対応のラインと考えてください。
オーバーコミット設計における 3 つのチェックポイント
推奨値の範囲内であっても、以下の 3 つのリスク要因を考慮しないとシステムは健全に動作しません。
① CPU Ready Time / co-stop の継続監視
前述の %RDY と %CSTP は、esxtop で一時的に確認するだけでなく、Aria Operations(旧 vRealize Operations)や Zabbix などの監視基盤で常時取得・アラート化することをおすすめします。
公式ドキュメントでは、%RDY は vCPU あたり 10〜15%、%CSTP は vCPU あたり 5% を超えるとパフォーマンス影響の可能性ありとされています。継続的にこの数値を超える場合は、オーバーコミット率を下げる(VM を別ホストに移動する)か、vCPU の割り当てを減らす対応を検討します。
② HA(高可用性)と障害時のリソース確保
平常時に全台動いているだけでは設計として不十分で、「物理ホストが 1 台故障したとき、残りのホストで全 VM を支えられるか」を計算に入れる必要があります。
リソースを限界まで集約していると、障害発生時に避難先のホストも満員で VM が再起動できない(HA が失敗する)リスクがあります。N+1 構成(1 台壊れても余力を残せる構成)を維持するため、クラスター全体のリソース使用率には 20〜30% 程度のバッファ を持たせておくことをおすすめします。
vSphere HA の設計パラメータ(アドミッションコントロール)の詳細は、関連記事「vSphere HA アドミッションコントロールの設定ポイント」もあわせてご確認ください。
③ ワークロードの特性(ピークタイムの重複)
オーバーコミットは「全員が同時に CPU を使わない」という前提で成り立っています。ピークタイムが大きく重なるシステム同士は、相性がよくありません。
例えば、全サーバーが毎朝 9:00 に一斉に始業時バッチ処理を行うような環境では、オーバーコミットの効果は発揮されにくくなります。バッチ処理の時間をずらすか、リソースを占有割り当て(予約)にするといった対応が考えられます。
現場で見られる NG 設計パターン 3 選
実際の現場で見かける典型的な NG パターンを 3 つ紹介します。
NG ①|余裕を見て vCPU を多めに割り当てる
「アプリ担当者から要望されたので、余裕を見て 8 vCPU 割り当てた」というケースです。実際には 2 vCPU で十分な場合、過剰割り当てによって co-stop が増え、かえって遅くなることがあります。ホスト全体の集約効率も悪化します。
最初は控えめに割り当て、%RDY と CPU 使用率を見ながら段階的に増やす運用をおすすめします。
NG ②|本番 DB をメモリオーバーコミット環境に同居
「コスト削減のため、開発 VM と本番 DB を同じクラスターに統合した」というケースです。開発 VM のメモリ使用がスパイクした瞬間、本番 DB がスワップしてサービス影響につながるトラブルは少なくありません。
本番 DB は専用クラスターか、最低でもリソースプールで分離し、メモリ予約(Reservation)を設定することをおすすめします。
NG ③|物理コア = vCPU 上限と捉えてしまう
「物理 20 コアだから、1 VM に最大 20 vCPU まで」と機械的に判断するケースです。前述の NUMA 境界を考慮していないと、たとえ物理コア数以下でも性能劣化につながります。
1 VM の vCPU 数は、1 NUMA ノード(1 ソケット)のコア数を上限として設計するのが安全です。
まとめ
オーバーコミットは、コスト効率とパフォーマンスのトレードオフを伴う技術です。便利な一方で、すべての環境に当てはまる万能解ではありません。Broadcom 買収後の新ライセンス体系では、物理コアの追加コストが大きくなり、集約率の最適化が経営インパクトに直結する状況です。あわせて、集約設計の安全性をデータで担保する運用力も、これまで以上に問われています。
実践のポイントは次のとおりです。
- まずは安全な比率からスタートする(CPU 3:1、メモリ 1:1 程度)
- esxtop や監視ツールで
%RDY/%CSTP/SWR/sを継続的に確認する - vCPU は 1 NUMA ノード内に収めるよう設計する
- メモリは課金対象外のため、十分に搭載しオーバーコミットは避ける
- N+1 構成のバッファ(20〜30%)を確保し、HA 失敗のリスクを抑える
- ピークタイムが重複するワークロードは別クラスターに分ける
- 段階的に最適化していく運用サイクルを回す
参考資料
- Performance Best Practices for VMware vSphere 8.0(VMware 公式)
- esxtop データの解釈ガイドライン(Broadcom Tech Docs)
- VMware by Broadcom: 製品ラインアップとライセンスモデルを大幅に簡素化(VMware Japan Blog)
以上、最後までお読みいただきありがとうございました。

