

はじめに
NetApp ONTAP のバージョンアップ(OS アップデート)は、かつて管理者がテイクオーバー(系切り替え)とギブバック(系切り戻し)をコマンドで一つずつ実行する、慎重さを要する作業でした。現在の ONTAP 9 では、これらの工程をシステムが自動制御する ANDU(Automated Non-Disruptive Upgrade)が標準となり、無停止での更新がより安全に行えるようになっています。一方で、ANDU が途中で停止した場合などには、いまも手動コマンドの理解が役立ちます。
- ANDU(自動無停止アップグレード)の仕組みと流れ
- ONTAP イメージの入手と検証の手順(cluster image)
- コマンドで実行する自動アップデートの進め方
- 手動コマンド(storage failover の takeover / giveback)と旧コマンド(cf・sysconfig)の現在
結論として、現在の ONTAP 9 では System Manager または CLI からの ANDU が推奨される更新方法で、検証からインストール、テイクオーバー、ギブバックまでを自動で完了できます。管理者が押さえるべきは、対象バージョンへのアップグレードパスの確認と、作業後の HA 構成の健全性チェックです。手動コマンドは、ANDU の一時停止時やトラブルシューティングでの介入手段として理解しておくと安心です。
ONTAP バージョンアップの概要
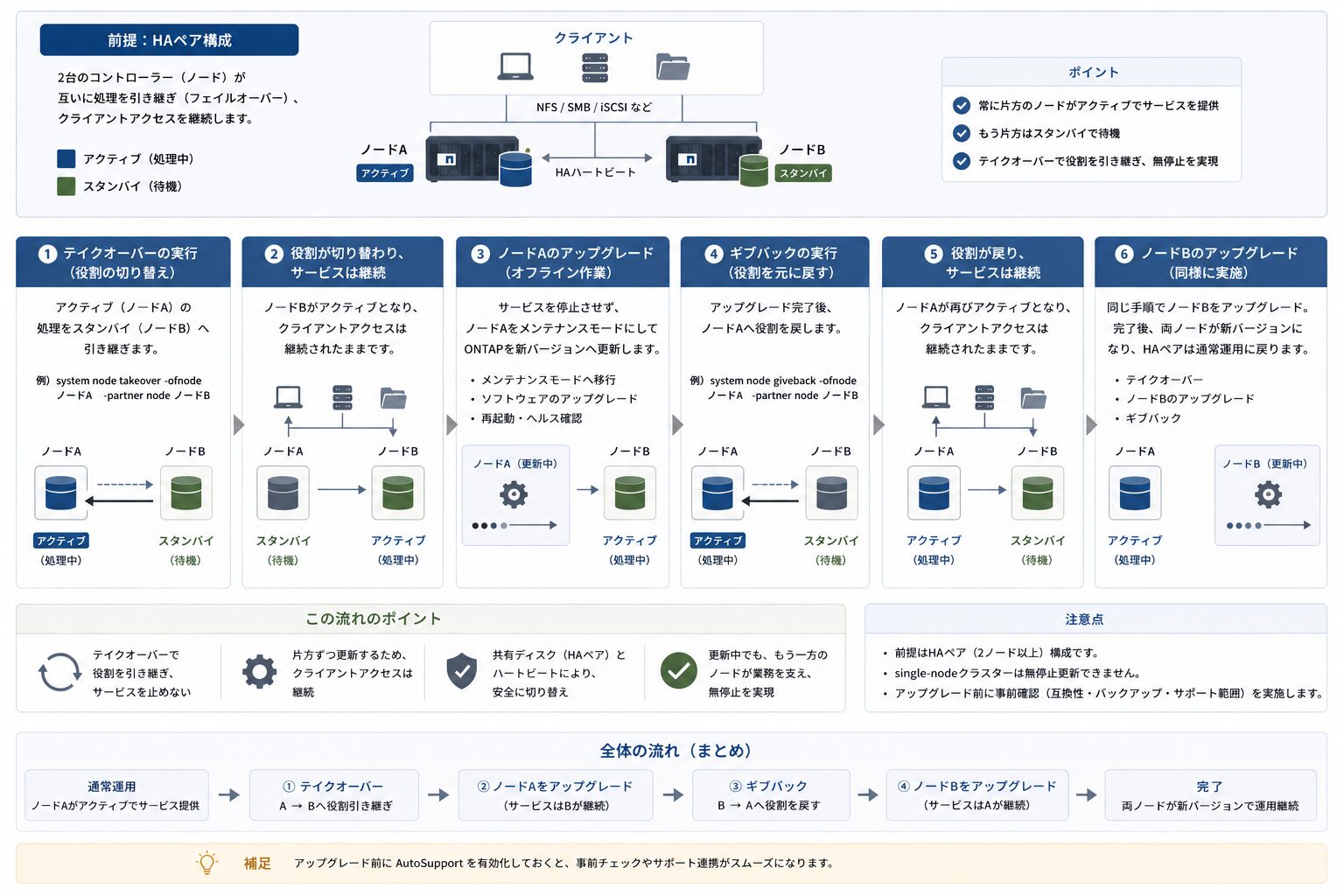
ONTAP は 2 台のコントローラー(ノード)で 1 つの HA ペアを構成し、互いに処理を引き継ぎながら片方ずつ更新することで、クライアントアクセスを止めずにアップグレードします。
NetApp ONTAP システムは、通常 2 台のコントローラー(ノード)で 1 つの HA ペアを構成します。アップグレードの際は、この 2 台が互いに処理を引き継ぐことで、クライアントからのアクセス(NFS / SMB / iSCSI など)を止めずに、片方ずつ順番に更新します。クラスター運用全体の位置づけは、関連記事『NetApp ONTAP 運用の要点|安定稼働と障害対応のポイント』も参考になります。
ただし、この無停止の前提は HA ペア(2 ノード以上)構成です。single-node クラスターでは無停止にならないなど、構成ごとの制約は後述します。
ANDU(Automated Non-Disruptive Upgrade)とは
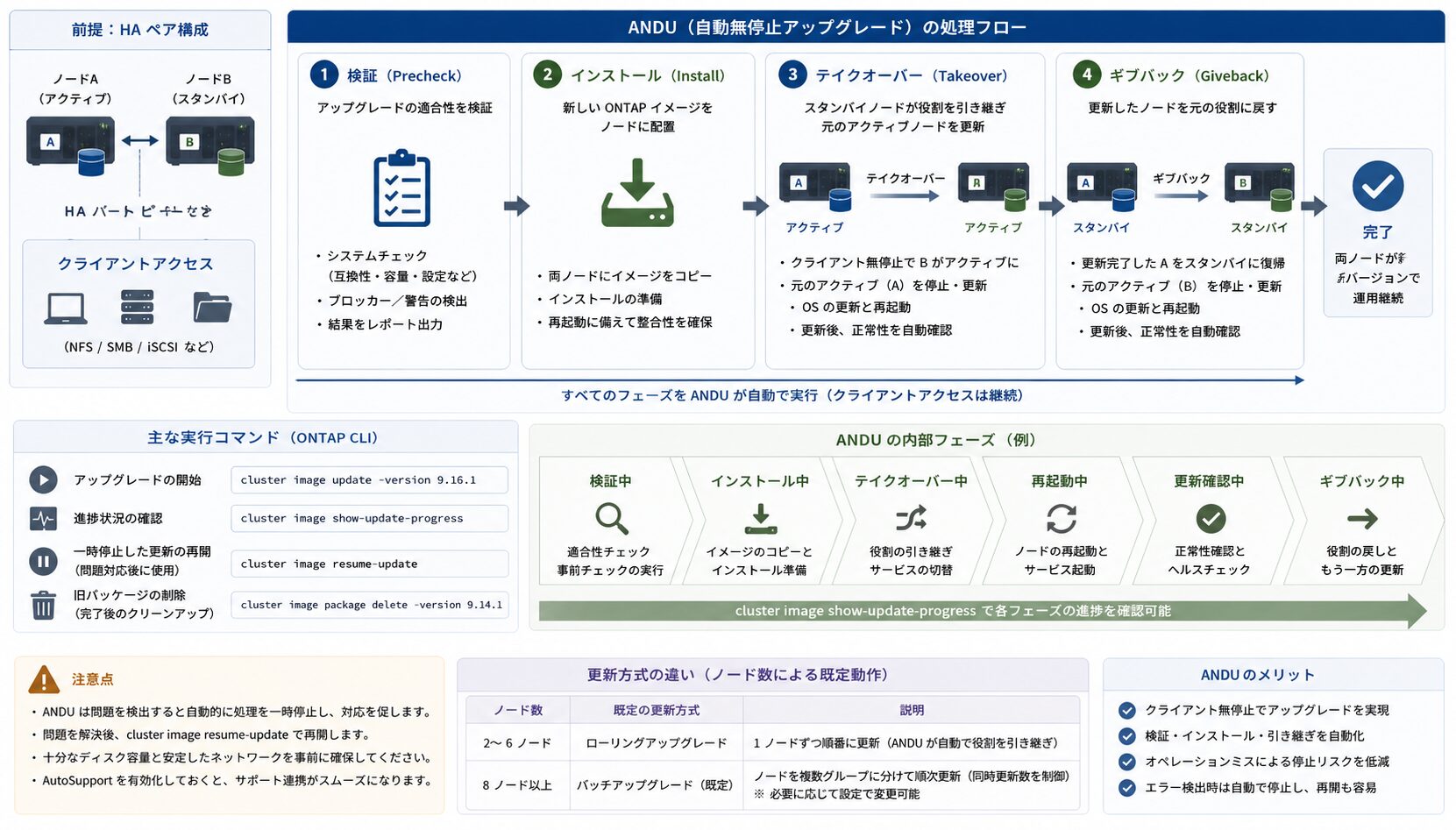
ANDU は、テイクオーバーとギブバックを含む一連の工程をシステムが自動制御する機能です。
かつては「片系を停止させ(テイクオーバー)、更新し、戻す(ギブバック)」という手順を、管理者が手動でコマンド実行していました。手順が多く、オペレーションミスの余地がありました。ANDU(Automated Non-Disruptive Upgrade)は、検証・インストール・再起動・テイクオーバー・ギブバックという一連の工程を、システムが自動で制御する機能です。コマンド 1 つ(または System Manager のクリック操作)で実行でき、手動に比べてオペレーションミスによる停止リスクを下げられます。
現在の ONTAP 運用では、自動アップグレードは System Manager の利用が第一に推奨され、特にパッチアップグレードでは構成を問わず System Manager 経由の ANDU が推奨方式とされています。 System Manager が利用できない構成では、CLI から ANDU を実行します。本記事では CLI を中心に解説しますが、要件に合えば System Manager を優先する選択が無難です。
参考: ONTAP software upgrade methods(NetApp 公式ドキュメント)
“ANDU using System Manager is the recommended upgrade method for all patch upgrades”
(System Manager を用いた ANDU は、すべてのパッチアップグレードで推奨される更新方法)
https://docs.netapp.com/us-en/ontap/upgrade/concept_upgrade_methods.html
事前準備とイメージの検証
アップグレード前に、対象イメージの入手、アップグレードパスの確認、そしてイメージの配置と検証を行います。
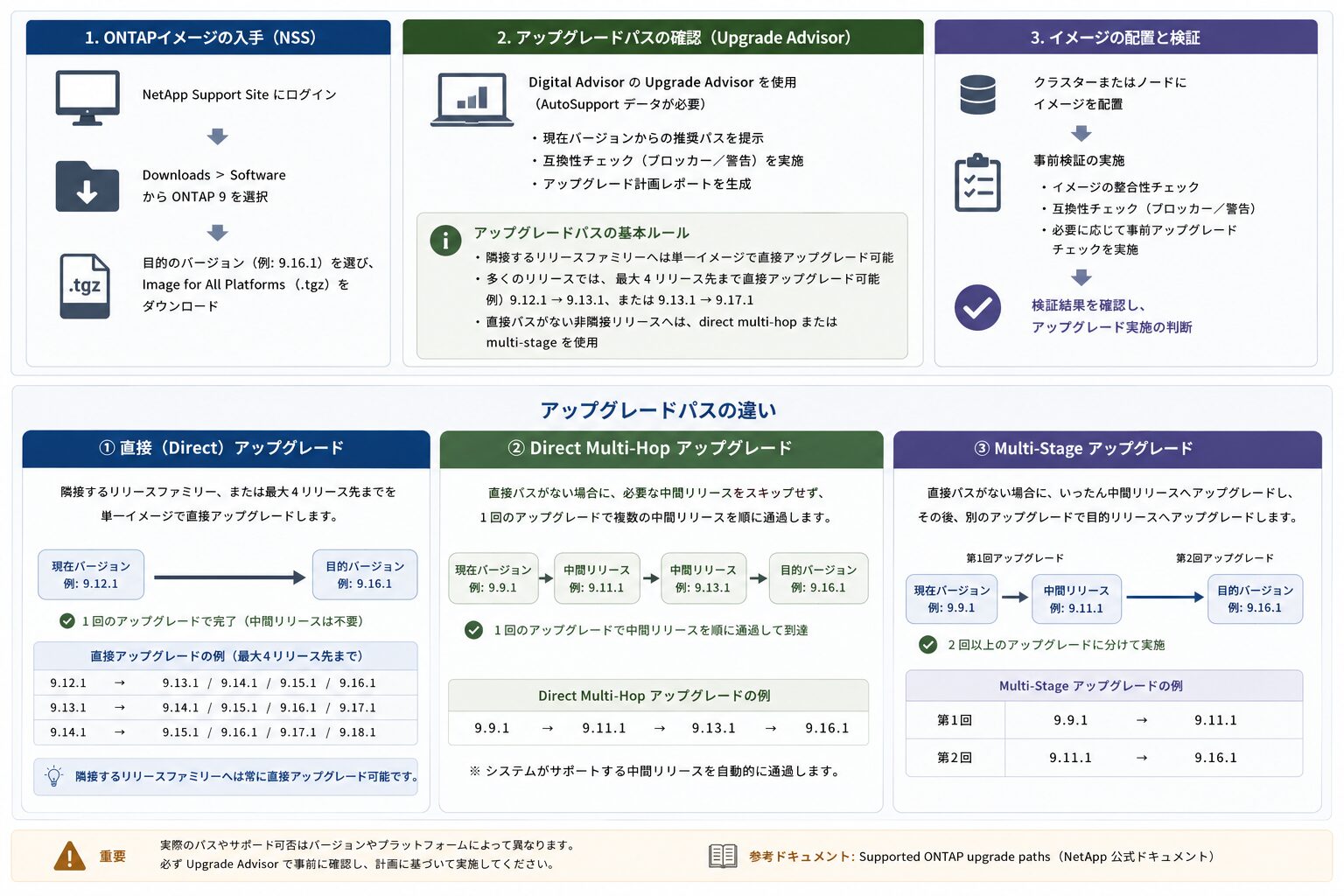
ONTAP イメージの入手とアップグレードパスの確認
アップグレードを行うには、まず NetApp サポートサイト(NSS)から対象の ONTAP ソフトウェアを入手します。
- NetApp Support Site にログインします。
- Downloads > Software から ONTAP 9 を選択します。
- 目的のバージョン(例: 9.16.1 など)を選び、Image for All Platforms(.tgz)をダウンロードします。
ここで重要なのが、現在のバージョンから目的のバージョンへ直接アップグレードできるか(アップグレードパス)の確認です。NetApp の Active IQ Digital Advisor に含まれる Upgrade Advisor を使うと、AutoSupport のデータをもとに、推奨パスや事前チェック(ブロッカー・警告)を含む計画を生成できます(利用には Digital Advisor 向けの SupportEdge 契約が必要です)。AutoSupport の設定は、関連記事『NetApp ONTAP AutoSupport の設定手順|HTTPS とメール通知のポイント』も参考になります。
アップグレードパスの考え方は、以前と変わっている点に注意が必要です。ONTAP では、隣接するリリースファミリーへは単一イメージで直接アップグレードでき、多くのリリースでは最大 4 リリース先まで直接アップグレードが可能です(例: 9.12.1 から 9.13.1、または 9.13.1 から 9.17.1) 直接パスがない非隣接リリースへは、中間リリースのイメージを経由する direct multi-hop、またはいったん中間リリースへ上げてから目的バージョンへ上げる multi-stage の手順をとります。
参考: Supported ONTAP upgrade paths(NetApp 公式ドキュメント)
“You can always upgrade directly to the next adjacent ONTAP release family”
(常に次の隣接する ONTAP リリースファミリーへ直接アップグレードできる)
https://docs.netapp.com/us-en/ontap/upgrade/concept_upgrade_paths.html
HTTP サーバーの準備とイメージ取得
CLI では、HTTP サーバー経由でイメージを取得するのが一般的です。Windows 環境であれば、Mongoose などの軽量 Web サーバーを利用すると配置が簡単です。
- Mongoose を起動し、ルートディレクトリにダウンロードした .tgz ファイル(例: 9161_q_image.tgz)を配置します。
- Web ブラウザーで
http://<PC の IP>/9161_q_image.tgzにアクセスできることを確認します。
かつての software get コマンドは、現在は cluster image package get に置き換わっています。
# Web サーバーからイメージをダウンロード
cluster image package get -url http://192.168.1.100/9161_q_image.tgz
# クラスターのパッケージリポジトリに格納されたことを確認
cluster image package show-repository事前検証(cluster image validate)
イメージの破損有無や、現在のハードウェア構成との互換性を検証します。このステップでエラーが出た場合、アップグレードは開始できません。
# 検証の実行
cluster image validate -version 9.16.1
# 検証結果の確認(エラーや要対応項目がないことを確認)
cluster image show-update-validation自動更新(ANDU)の実行
ONTAP 9 以降では、システムが検証・インストール・テイクオーバー・ギブバックを自動で行う ANDU が標準かつ推奨の方法です。手動に比べ、オペレーションミスによる停止リスクを下げられます。
検証が完了したら、次のコマンドでアップグレードを開始します。
# 自動アップデートの開始
cluster image update -version 9.16.1
# 進捗状況のモニタリング(検証中・インストール中・再起動中などのフェーズを確認)
cluster image show-update-progress特定の警告を無視する必要がある場合は -validation-ignore などのオプションを付与することもありますが、通常は上記のコマンドで開始できます。
参考: How to perform an automated nondisruptive ONTAP upgrade using the CLI(NetApp KB)
“installs the target ONTAP image on each node, and then executes the upgrade”
(対象の ONTAP イメージを各ノードにインストールし、その後アップグレードを実行する)
https://kb.netapp.com/on-prem/ontap/Ontap_OS/OS-KBs/How_to_perform_an_automated_nondisruptive_ONTAP_upgrade_using_the_CLI
アップグレード中に問題が検出されると、ANDU は処理を一時停止し、対応を促します。修正後は、cluster image resume-update で処理を再開できる点を押さえておくと、停止時にも落ち着いて対処できます。 完了後、不要になった旧パッケージは cluster image package delete -version <旧バージョン> で削除できます。
# 一時停止した更新の再開
cluster image resume-update
# 旧パッケージの削除
cluster image package delete -version 9.14.1なお、更新方式はクラスターのノード数で変わります。2〜6 ノードはローリングアップグレード、8 ノード以上は既定でバッチアップグレードが実行されます。
手動での更新手順(CLI)
ANDU があっても、手動コマンドの理解は不要にはなりません。ANDU が一時停止した場合や、ギブバックが自動で進まなかった場合に、管理者が手動でプロセスを進める必要があるためです。ここでは、検索需要の高い旧コマンド(cf)と、現在の対応コマンド(storage failover)を対比して解説します。
storage failover takeover(旧 cf takeover)
片方のノードを停止させ、パートナーノードに処理を引き継がせる操作です。
旧コマンド(7-Mode)
head2> cf takeover新コマンド(ONTAP 9)
# node-01 をテイクオーバーさせる
storage failover takeover -ofnode node-01storage failover giveback(旧 cf giveback)
停止していたノードが復旧した後、ストレージの制御権を元の持ち主に戻す操作です。
旧コマンド(7-Mode)
head2(takeover)> cf giveback新コマンド(ONTAP 9)
# node-01 へ制御権を戻す
storage failover giveback -ofnode node-01
# ギブバックの進捗を監視
storage failover show-giveback参考: Learn about automatic takeover and giveback in ONTAP clusters(NetApp 公式ドキュメント)
“Automatic giveback occurs by default”
(ギブバックは既定で自動的に行われる)
https://docs.netapp.com/us-en/ontap/high-availability/ha_how_automatic_takeover_and_giveback_works.html
sysconfig -a と現在の確認コマンド
ハードウェア構成の詳細を確認する sysconfig -a は、今も多くのエンジニアが使うコマンドです。ONTAP 9 ではノードシェル(下層)に隠蔽されていますが、次の方法で実行できます。
方法 1: クラスターシェルから実行する(推奨)
# node-01 に対して sysconfig -a を実行
system node run -node node-01 -command sysconfig -a方法 2: ONTAP 9 ネイティブのコマンドで確認する
# システム構成の概要
system node show
# ハードウェアの接続状況
system node hardware unified-connect showアップグレード方式の使い分けと制約事項
構成や目的に応じて、System Manager・CLI による ANDU・手動 CLI を使い分けます。
| 方法 | 主な操作 | 主な用途 | 備考 |
|---|---|---|---|
| System Manager(GUI) | クリック操作 | 第一推奨。パッチを含む大半のケース | 構成が対応していれば推奨 |
| CLI による ANDU | cluster image update | GUI 非対応構成、自動化・スクリプト | 無停止(HA ペア前提) |
| 手動 CLI | storage failover takeover / giveback | ANDU 一時停止時、トラブルシュート | 介入手段として理解が必要 |
導入や計画の判断材料として、無停止アップグレードが成立する前提と制約も整理しておきます。
- single-node クラスターでは、アップグレードは無停止になりません。HA ペア(2 ノード以上)構成が無停止更新の前提です。
- 非隣接リリースへのアップグレードでは、中間リリースのイメージが必要になる場合があります(direct multi-hop または multi-stage)
- 混在バージョンのクラスターでも直接アップグレードパスは利用できますが、メジャーバージョンをまたぐ混在はサポートされません。
- 自動ギブバックには既定の遅延(600 秒)があり、クライアントへの影響を抑える挙動になっています。
参考: Install the ONTAP image with automated nondisruptive ONTAP upgrade(NetApp 公式ドキュメント)
“Upgrades of single-node clusters are disruptive”
(single-node クラスターのアップグレードは無停止にならない)
https://docs.netapp.com/us-en/ontap/upgrade/automated-upgrade-task.html
作業後の確認
アップグレードプロセスが完了したら、ターゲットのバージョンが全ノードに適用され、HA 構成が正常に戻っていることを確認します。
バージョンの確認
# クラスター全体のバージョンを確認
version
# 各ノードのイメージ状態を確認
cluster image showここで Current Version が目的のバージョンになっており、Is Current が true であれば更新は成功しています。
HA 構成の健全性確認
最も重要なのが、HA ペア(冗長構成)の状態確認です。アップグレード中は一時的に片系稼働になりますが、作業後は両系稼働かつ、いつでもテイクオーバー可能な状態に戻っている必要があります。かつての cf status に代わり、現在は storage failover show を使います。
# HA ペアの状態確認
storage failover show確認ポイント
- Takeover Possible が true になっていること。
- State が Connected になっていること。
ここが false や Partial Giveback などになっている場合は、まだ復旧が完了していません。エラーログを確認し、ギブバックの完了を待つか、手動での介入を検討します。アップグレード後の性能面の確認は、関連記事『NetApp sysstat の見方|性能分析とボトルネック特定の手順』も参考になります。
まとめ
本記事では、NetApp ONTAP 9 のバージョンアップを、推奨される自動無停止アップグレード(ANDU)と、基礎となる手動コマンドの両面から解説しました。複雑なテイクオーバー/ギブバックを自動化する cluster image update が現在のスタンダードで、手動コマンドは一時停止時やトラブルシューティングでの備えになります。要点を以下にまとめます。
- アップグレードは System Manager または CLI からの ANDU が推奨方式
- アップグレードパスは隣接ファミリーへ直接、最大 4 リリース先まで
- 事前検証は cluster image validate で実施し、要対応項目の解消が前提
- ANDU 一時停止時は cluster image resume-update で再開
- 手動介入の備えとして storage failover takeover / giveback の把握
- 作業後は storage failover show による HA 健全性の確認
- single-node 構成は無停止更新の対象外という前提
以上、最後までお読みいただきありがとうございました。
