

はじめに
「毎日決まった時間に Web サイトを開いて、数値をコピーして Excel に貼り付ける…」 「複数の競合サイトの商品価格を、手作業で調査して一覧にする…」
もしあなたがこのような単純作業に時間を奪われているなら、Python を使った Web スクレイピング がその悩みを一瞬で解決してくれるかもしれません。
Web スクレイピングとは、プログラムを使って Web サイトから情報を自動的に抽出し、利用しやすい形(Excel や CSV、データベースなど)に加工・保存する技術のことです。一度プログラムを書いてしまえば、寝ている間でも Python が勝手に最新データを集めてくれます。業務効率化のインパクト大です。
しかし、便利さと同時に「スクレイピングって違法じゃないの?」「サーバーに負荷をかけて怒られない?」といった不安を感じる方も多いのではないでしょうか。検索候補に「禁止」「違法」と出てくるとドキッとしますよね。
安心してください。スクレイピングは、正しい法律の知識とマナー(ルール)さえ守れば、すごく便利な道具になります。
- Web スクレイピングの仕組み
- 「やっていいこと・悪いこと」の境界線(法律・マナー)
- Python での実践コード(Requests + BeautifulSoup)
- よくあるエラーと対処法
Web スクレイピングとは?
Web スクレイピング(Web Scraping)とは、広義には「Web サイトからデータを収集し、利用しやすい形に加工すること」を指します。
普段、私たちが Web ブラウザ(Chrome や Edge)でサイトを見る時と、Python プログラムがアクセスする時では、見ているものが少し違います。

- 人間(ブラウザ)
-
HTML や CSS を読み込み、綺麗にデザインされた「画面」として見ています。
- プログラム(Python)
-
サーバーから送られてくる 「HTML ソースコード(文字の羅列)」 を直接読み取ります。ここから「
<title>タグの中身」や「class="price"の数字」といった特定の文字を探し出して抜き出すのがスクレイピングの正体です。
API との違い(公式な窓口か、通用口か)
データを取得する手段として、よく API(Application Programming Interface) と比較されます。どちらも「データを自動で取得する」点は同じですが、アプローチが全く異なります。
| 特徴 | API | Web スクレイピング |
| イメージ | 🏢 正面玄関(公式窓口) | 🚪 通用口・裏口 |
| データの形式 | プログラムが読みやすい形式(JSON, XML 等) | 人間が読むための形式(HTML) |
| 提供元 | サイト運営者が「使っていいよ」と用意したもの | 運営者が意図していない場合が多い |
| 安定性 | 高い(仕様変更が少ない) | 低い(デザイン変更で動かなくなる) |
API は、サイト運営者が「データを提供するため」に用意した公式ルートです。もし取得したいサイトに API があるなら(例: X, Amazon Product Advertising API など)、基本的には API を使うのが正解です。
スクレイピングは、API が用意されていないサイトからデータを取得するための 「最終手段」 と言えます。あくまで「人間が見るためのページ」をプログラムで読み取るため、サイトのデザインが変わるとプログラムも動かなくなる(メンテナンスが必要になる)という弱点があります。
【重要】スクレイピングは違法? 禁止事項とマナー
結論から言うと、「スクレイピング=違法」ではありません。 しかし、やり方を間違えると「違法行為」や「迷惑行為」になり、トラブルに巻き込まれるリスクがあります。
「どこまでが OK で、どこからが NG なのか?」という境界線を正しく理解することが、スクレイピングを始めるための最初のステップです。
法律的には「適法」なケースが多い
日本の法律(著作権法)では、「情報解析(AI 開発やデータ分析など)」を目的とする場合、原則として他人の Web サイトからデータを収集・利用することが認められています(著作権法第30条の4)また、「私的利用(自分だけで使う)」の範囲内であれば問題になることは少ないです。
ただし、これには重要な例外があります。以下の行為は絶対に NG です。
- ❌ 取得したデータをそのまま転載・販売する: 著作権侵害になります。
- ❌ サーバーをダウンさせる: 偽計業務妨害罪などに問われる可能性があります。
絶対に守るべき「3つのルール(マナー)」
法律以前の問題として、Webサイトの運営者に迷惑をかけないための「マナー」を守る必要があります。以下の3つは、スクレイピングを行う上での最低限のルールです。
ほとんどのWebサイトは、トップページに robots.txt というファイルを設置しています(例: https://example.com/robots.txt)ここには「このページはロボット(クローラー)でアクセスしないでね(Disallow)」というサイト側の意思が書かれています。 法的な拘束力はありませんが、これを無視するのは他人の家の「立入禁止」の看板を無視して侵入するようなものです。必ず確認し、Disallow と書かれているページへのスクレイピングは避けましょう。
プログラムは人間には不可能な速度でページにアクセスできます。 もし「1秒間に100回」のようなペースでアクセスすると、相手のサーバーがパンクしてしまい(DoS 攻撃と同じ状態)、一般の利用者がアクセスできなくなってしまいます。 必ずアクセスごとに「1秒以上」の間隔(sleep)を空けるようにプログラムしましょう。「相手のサーバーを使わせてもらっている」という意識が大切です。
サイトの「利用規約(Terms of Service)」に、「自動化された手段(スクレイピング等)によるアクセスを禁止する」 と明記されている場合があります。 特に、ログインが必要な会員制サイトでは厳しく禁止されているケースが多いです。規約に違反すると、アカウント停止や法的措置の対象になる可能性があります。必ず事前に規約をチェックしましょう。
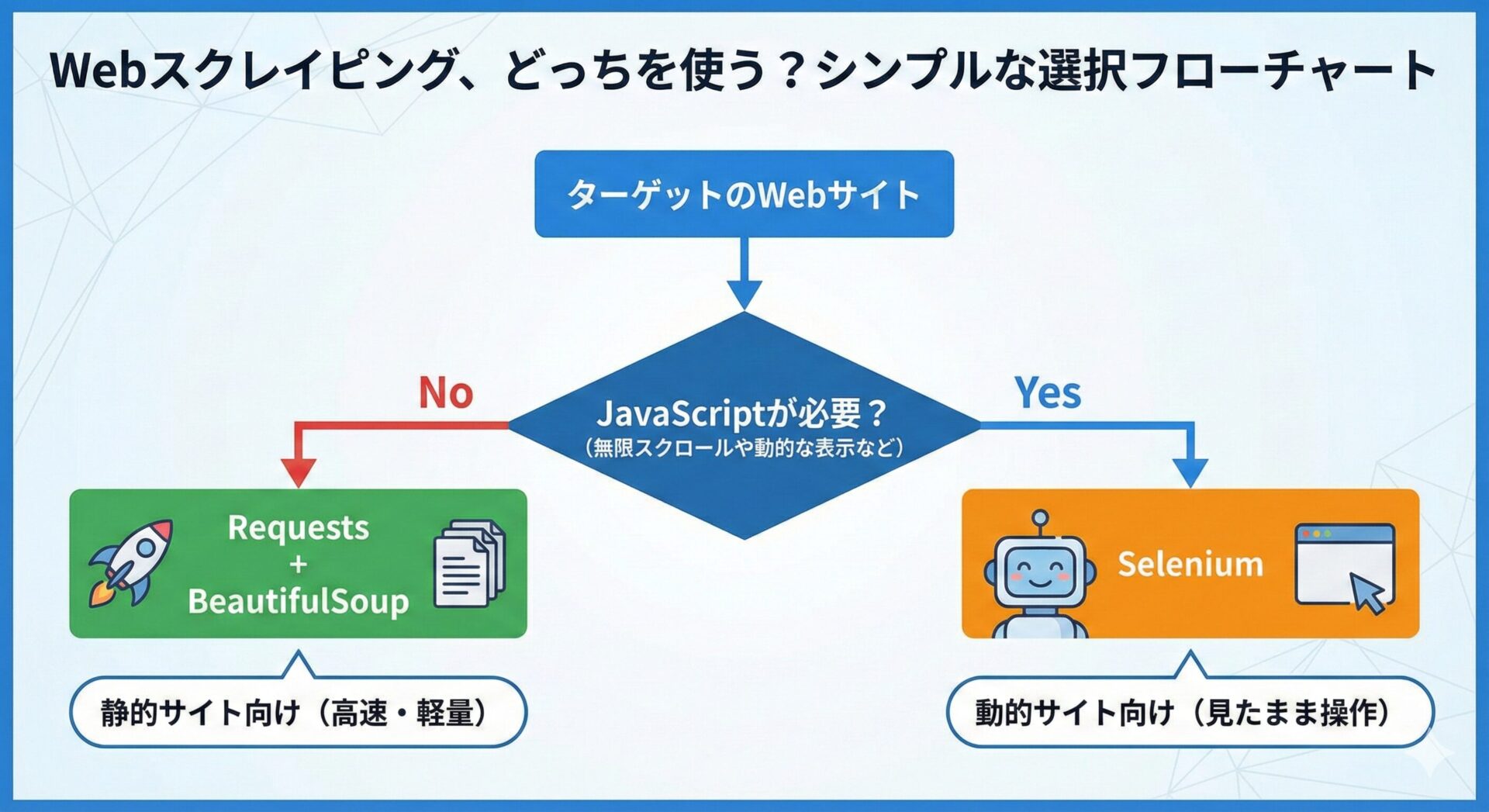
必要なライブラリと選び方
Python でスクレイピングを行う場合、主に以下の2つの組み合わせのどちらかを使用します。 対象の Web サイトがどのように作られているかによって、適切な道具を選ぶ必要があります。
- 特徴
-
- 高速・軽量
- 役割
-
- Requests: Web ページ(HTML)をダウンロードしてくる係
- BeautifulSoup: ダウンロードした HTML から欲しいデータを探し出す係
- 得意なこと
-
- ニュースサイト、ブログ、企業 HP など、ページを開いた瞬間に文字が表示されている(HTML にデータが書かれている)サイト
- 苦手なこと
-
- JavaScript を使って後からデータを読み込むサイト(X や Instagram など)、ログイン操作が複雑なサイト
- 特徴
-
- 万能だが遅い
- 役割
-
- Google Chrome などのブラウザをプログラムで実際に立ち上げて操作する「ブラウザ自動化ツール」
- 得意なこと
-
- ボタンクリック、スクロールが必要なページ、JavaScript でデータが表示されるページ(SPA)
- 苦手なこと
-
- ブラウザを起動するため動作が重く、処理に時間がかかる。
どっちを使えばいいの?
基本的には、まず「Requests + BeautifulSoup」を検討し、それでもダメな場合に「Selenium」を使うのが鉄則です。理由は単純で、Requests の方が圧倒的に処理が速く、コードもシンプルだからです。
本記事では、スクレイピングの基礎を学ぶために、基本となる「Requests + BeautifulSoup」の組み合わせについて解説します。
実践: ニュースサイトのタイトルを取得する
それでは、実際に Python を動かしてデータを取得してみましょう。 今回は例として、Python 公式サイトの「最新ニュース(Latest News)」のタイトル一覧を取得します。
環境準備
まずは必要なライブラリをインストールします。コマンドライン(ターミナル)で以下を実行してください。
pip install requests beautifulsoup4HTML を取得する(Requests)
まずは requests を使って、Web サイトのデータをダウンロードします。ここで重要なのが User-Agent (UA)の設定です。
なぜ UA(User-Agent)の設定が必要なのか?
通常、ブラウザでアクセスすると「私は Chrome です」「iPhone です」という名刺(UA)をサーバーに渡します。 しかし、Python の requests はデフォルトで「私は Python のプログラムです」という名刺を渡してしまいます。多くの Web サイトは、ボットによるアクセスを防ぐために、この「プログラムからのアクセス」を門前払い(403エラー)にします。 そのため、ヘッダー情報を偽装して「私は普通のブラウザですよ」と伝える必要があります。
データを抽出する(BeautifulSoup)
HTML を取得できたら、BeautifulSoup で解析(パース)し、欲しいデータを取り出します。 データの抽出には主に以下の2つのメソッドを使います。
find()/find_all(): HTMLタグ(<div>や<a>)や属性を指定して探す方法select(): CSS セレクタ(#idや.class)を使って探す方法
今回は直感的な select() の方法を使います。
【重要】ブラウザの「検証ツール」を使った要素の探し方
スクレイピングで一番難しいのは、コードを書くことではなく「欲しいデータが HTML のどこにあるかを見つけること」です。これにはブラウザの「検証ツール(デベロッパーツール)」を使います。
取得したい文字(ニュースのタイトルなど)の上で右クリックし、「検証(Inspect)」を選びます。
画面右側(または下)にパネルが開き、該当箇所の HTML がハイライトされます。
<h3 class="event-title">...</h3> のようなタグが見つかります。この .event-title がデータの住所(セレクタ)になります。
最近のサイト(Yahoo!ニュースやメルカリなど)では、class="sc-a1b2c3..." のように意味のない英数字の羅列が使われていることがあります。 これらはサイトの更新ですぐに変わってしまうため、指定しても明日には動かなくなる可能性があります。
- コツ: 親要素の
idや、articleh2といった変わらない構造(タグ)を目印にするのが安定稼働の秘訣です。
サンプルコード: コピペで動く実例
以下のコードは、Python 公式サイトからニュースのタイトルと URL を抽出して表示します。 そのままコピーして実行してみてください。
import requests
from bs4 import BeautifulSoup
import time
# 1. ターゲットURL(今回はPython公式サイトのニュース)
url = "https://www.python.org/blogs/"
# 2. User-Agentの設定(ブラウザのふりをする)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
}
try:
# 3. Webページを取得
# timeoutを設定して、応答がない場合に無限待ちになるのを防ぐ
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # エラー(4xx, 5xx)があればここで例外を発生させる
# 4. BeautifulSoupでHTMLを解析
soup = BeautifulSoup(response.text, "html.parser")
# 5. 要素を抽出(検証ツールで調べたセレクタを指定)
# Python.orgでは <li> の中の <h3 class="event-title"> の中の <a> にタイトルがある
news_list = soup.select("ul.list-recent-posts li h3.event-title a")
print(f"取得件数: {len(news_list)}件")
print("-" * 30)
# 6. ループでデータを取り出す
for news in news_list:
title = news.getText().strip() # タイトル(余白削除)
link = news.get("href") # リンクURL
print(f"タイトル: {title}")
print(f"URL: {link}")
print("-" * 30)
# 【重要】マナーとして1秒待機(サーバー負荷軽減)
time.sleep(1)
except Exception as e:
print(f"エラーが発生しました: {e}")実行結果:
取得件数: 5件
------------------------------
タイトル: Python 3.12.0 Released
URL: https://pythoninsider.blogspot.com/2023/10/python-3120-released.html
------------------------------
タイトル: Python 3.11.6 Released
URL: https://pythoninsider.blogspot.com/2023/10/python-3116-released.html
...よくあるエラーと対処法
スクレイピングをしていると、コードは合っているはずなのにエラーが出る場面によく遭遇します。 ここでは、特に頻発する3つのエラーとその解決策を紹介します。
- 症状
-
requests.get()を実行した瞬間にエラーになり、データが取得できない。 - 原因
-
Web サイト側が「プログラム(Bot)からのアクセス」を検知して拒否しています。
- 対処法
-
User-Agent(UA)を偽装します。

前述のサンプルコードのように、
headers引数で一般的なブラウザの情報を渡すことで、解決する場合がほとんどです。
- 症状
-
elem.getText()やelem.get("href")の部分でエラーが落ちる。 - 原因
-
指定した要素が見つからなかった(None だった) ため、その後の操作ができない状態です。
- 対処法
-
- セレクタの確認: クラス名やIDが間違っていないか、変わっていないかを確認します。
- タイミング:
time.sleep()を入れてアクセス間隔を調整してみましょう。
ブラウザの「検証ツール」では見えるのに、Requests で取得した HTML にはその要素が存在しない場合、それは JavaScript で後から描画されている(動的コンテンツ) 可能性があります。この場合は Selenium への切り替えを検討します。
- 症状
-
取得したテキストが
テストのような意味不明な記号になる。 - 原因
-
Python が Web サイトの文字コード(Encoding)を読み違えています。
- 対処法
-
requestsに自動判定させる設定を追加します。response = requests.get(url) # 文字コードを自動推定して設定する(これを入れると直ることが多い) response.encoding = response.apparent_encoding soup = BeautifulSoup(response.text, "html.parser")
まとめ
本記事では、Python を使った Web スクレイピングの基礎から、法的な注意点、実践コードまでを解説しました。
- スクレイピングは強力なツール
-
手作業で数時間かかる作業を、数秒で終わらせることができます。
- マナー最重要
-
便利な反面、相手のサーバーに負荷をかける攻撃行為にもなり得ます。「
robots.txtを確認する」「アクセス間隔を空ける」といったマナーを必ず守りましょう。 - まずは静的サイトから
-
最初から複雑なサイト(要ログイン、JavaScript多用)に挑むと挫折しがちです。まずは
Requests + BeautifulSoupで抜き出せるシンプルなサイトで練習し、データ抽出の楽しさを体感してみてください。
以上、最後までお読みいただきありがとうございました。


