

はじめに
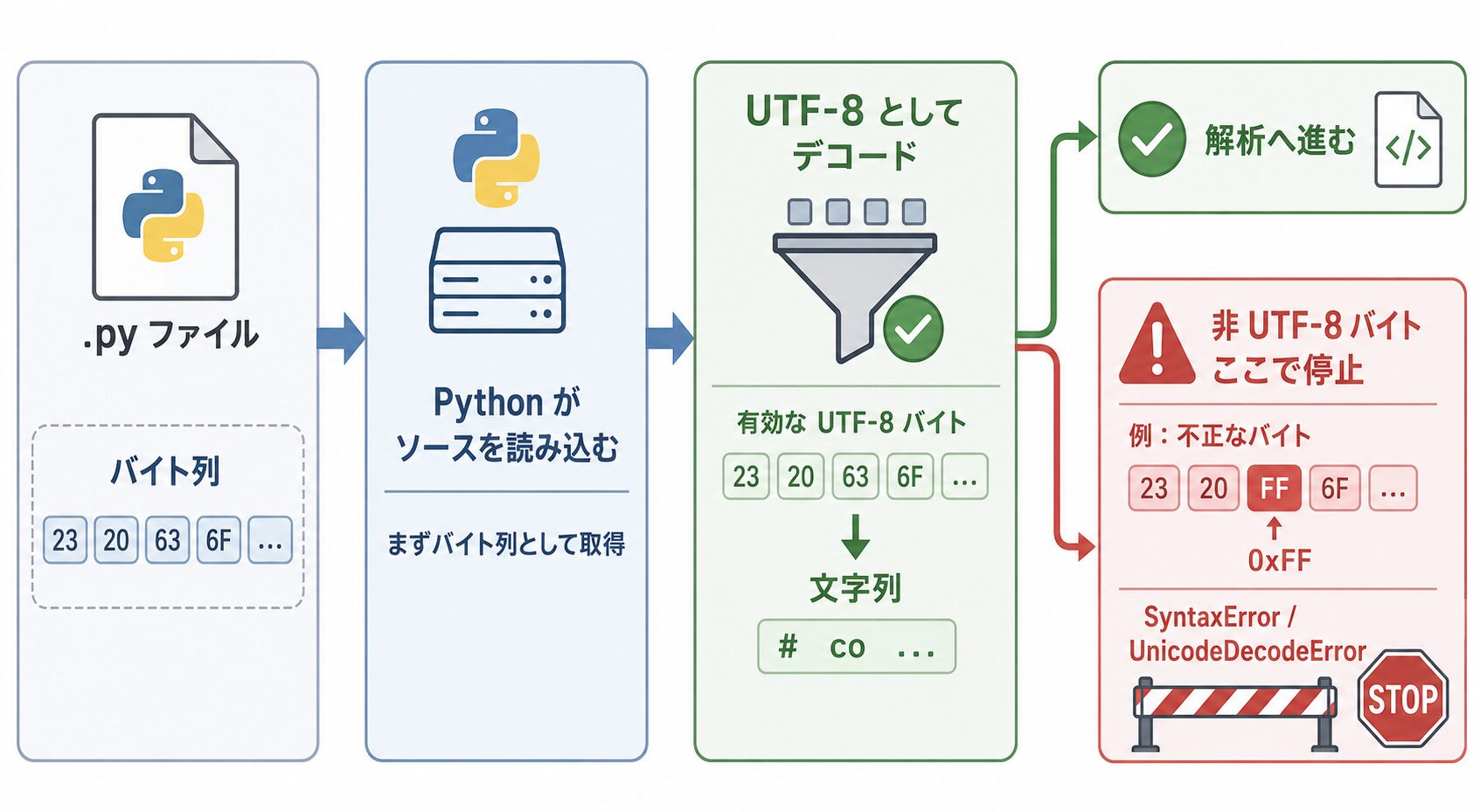
Python スクリプトを実行した際に、次のようなエラーが出て処理が止まることがあります。
SyntaxError: Non-UTF-8 code starting with '\x82' in file test.py on line 10, but no encoding declared; see https://peps.python.org/pep-0263/ for details英語のメッセージに加えて \x82 や \xe3 といったバイトが表示されますが、これはコードの記述ミスではなく、Python がソースファイルの文字コードを UTF-8 として読もうとして、UTF-8 では解釈できないバイトに出会ったことが原因です。スクリプトに日本語(コメントや文字列)が含まれている場合に発生しやすいエラーです。
- 即対処: ソースファイルを UTF-8 で保存し直してエラーを解消する方法
- 見分け方: エラーに出るバイト(
\x82や\xffなど)から実際の文字コードを推測する方法 - 自動判定: charset-normalizer で実際のエンコーディングを判定し、UTF-8 へ変換する方法
- 切り分け: 実行時の
UnicodeDecodeErrorなど、紛らわしい関連エラーとの違い
結論を先に述べると、多くの場合の確実な解決策は、ソースファイル自体を UTF-8 で保存し直すことです。Python 3 のソースコードは UTF-8 が既定のため、ファイルが UTF-8 であればこのエラーは発生しません。ファイルの文字コードが分からない場合は、後述の方法で実際のエンコーディングを判定してから変換します。なお、エラーに表示されるバイトは Shift-JIS とは限らず、\xff のように UTF-16 を示すケースもあるため、「Shift-JIS 決め打ち」での対処は避けるのが安全です。
即対処: ファイルを UTF-8 で保存し直す
最も確実な解決策は、スクリプトファイルの保存形式自体を UTF-8 に変換することです。これにより、文字コードの宣言(マジックコメント)を書かなくてもエラーが解消し、将来の文字化けトラブルも防げます。
VS Code(Visual Studio Code)の場合
- ウィンドウ右下のステータスバーにある現在のエンコーディング表示(「Shift-JIS」や「CP932」など)をクリックします。
- 画面上部に出るメニューから「エンコード付きで保存(Save with Encoding)」を選択します。
- リストから「UTF-8」を選択して保存します。
Windows メモ帳の場合
- 「ファイル」メニューから「名前を付けて保存」を選択します。
- 保存ダイアログ下部の「エンコード」のプルダウンから「UTF-8」を選択します。
- 上書き保存します。
保存し直したあとに再実行し、エラーが解消されていれば対処は完了です。Python 3 ではソースコードの既定エンコーディングが UTF-8 に定められているため、ファイルが UTF-8 であれば、1 行目のマジックコメント(# -*- coding: ... -*-)は不要になります。
参考: PEP 263 – Defining Python Source Code Encodings(peps.python.org)
“Python will default to ASCII as standard encoding if no other encoding hints are given.”
(エンコーディングの指定がない場合の、Python のソースコードの既定の扱いを定義しています。)
https://peps.python.org/pep-0263/
エラーのバイトから文字コードを見分ける
「UTF-8 で保存し直す」が確実な対処ですが、元の文字コードが分からないと、エディタでどのエンコーディングから変換するか迷う場合があります。エラーメッセージに表示されるバイトは、元の文字コードを推測する手がかりになります。
Non-UTF-8 code starting with '\xXX' の \xXX は、UTF-8 として解釈できなかった最初のバイトを 16 進数で示しています。代表的なバイトと、想定される文字コードの対応は次のとおりです。
| 報告されるバイトの例 | 想定される文字コード | 補足 |
|---|---|---|
\x82 \x83 \x81 \x8e \x8f \x95 | Shift-JIS / CP932 | 日本語の 1 バイト目に多い範囲(\x81〜\x9f) |
\xe0〜\xfc の一部(\xe3 など) | Shift-JIS / EUC-JP / UTF-8 のいずれか | 範囲が重なるため、これだけでは確定しにくい |
\xff \xfe | UTF-16(BOM の可能性) | \xff\xfe は UTF-16 LE の BOM |
\xef(\xef\xbb\xbf) | UTF-8 の BOM | BOM 付き UTF-8。通常はそのまま読めるが環境により問題になる場合がある |
ここで重要なのは、報告されたバイトはあくまで手がかりであり、文字コードを確定するものではないという点です。とくに \xe3 のような高位バイトは Shift-JIS・EUC-JP・UTF-8 で範囲が重なるため、見た目だけでは判断できません。\xff が出た場合は Shift-JIS ではなく UTF-16 で保存されている可能性が高く、この場合に coding: shift_jis を宣言しても解決しません。
確実に判断するには、次の方法で実際のエンコーディングを判定するのが安全です。
文字コードを自動判定して UTF-8 へ変換する
元のエンコーディングが分からない場合や、ファイルが多数ある場合は、文字コードを自動判定するライブラリを使うと確実です。ここでは charset-normalizer を使います。これは、未知の文字コードのテキストを読み取るための、Chardet に代わる活発に保守されたライブラリです。
インストール
pip install charset-normalizerエンコーディングの判定
from_path でファイルを解析し、best() で最も確からしい判定結果を取得します。encoding 属性に推定されたエンコーディング名が入ります。
from charset_normalizer import from_path
results = from_path("test.py")
best = results.best()
if best is not None:
print(f"推定エンコーディング: {best.encoding}")
else:
print("判定できませんでした。")なお、charset-normalizer は「元のファイルを符号化した正確なエンコーディング」を突き止めるのではなく、「読めるテキストになるエンコーディング」を推定する設計です。そのため推定結果は確定ではありませんが、UTF-8 へ変換する目的では実用上十分に機能します。
UTF-8 へ変換して保存する
判定結果から UTF-8 のバイト列を取り出し、別ファイルに保存します。output() は既定で UTF-8 のバイト列を返します。元のファイルを直接上書きせず、別名で保存すると安全です。
from charset_normalizer import from_path
results = from_path("test.py")
best = results.best()
if best is not None:
# output() は既定で UTF-8 のバイト列を返す
with open("test_utf8.py", "wb") as f:
f.write(best.output())
print("UTF-8 へ変換して test_utf8.py に保存しました。")変換後のファイルを実行し、エラーが解消されていれば対処は完了です。変換結果に問題がなければ、元のファイルを置き換えます。
コマンドラインでの確認
charset-normalizer はコマンドラインからも実行できます。インストールすると normalizer コマンドが使えるほか、python -m charset_normalizer でも実行できます。エディタを開かずに、ファイルの推定エンコーディングを素早く確認したいときに便利です。
normalizer test.py参考: charset_normalizer API(公式ドキュメント)
“output(encoding: str = ‘utf_8’) … Method to get re-encoded bytes payload using given target encoding. Default to UTF-8.”
(output は指定したエンコーディングで再符号化したバイト列を返し、既定は UTF-8 です。)
https://charset-normalizer.readthedocs.io/en/latest/api.html
暫定対処: マジックコメントでエンコーディングを宣言する
ファイルを UTF-8 へ変換できない事情がある場合は、ソースの先頭(1 行目または 2 行目)に文字コードを宣言するマジックコメント(エンコーディング宣言)を記述する方法があります。これは「元の文字コードのまま Python に読ませる」暫定的な対処です。
重要なのは、宣言する文字コードを、ファイルの実際のエンコーディングに合わせることです。前述の見分け方や自動判定で確認した文字コードを指定します。たとえば実際に Shift-JIS/CP932 で保存されている場合は、次のように記述します。
# -*- coding: cp932 -*-
print("日本語を含んでもエラーになりません")Windows 固有の拡張文字を含む場合は、shift_jis ではなく cp932 を指定すると安定します。なお、宣言の書式は # -*- coding: cp932 -*- のほか、# coding: cp932 の短い形でも認識されます。
ここで注意したいのは、ファイルの実際の文字コードと宣言が一致していなければ、別のエラーになる点です。たとえば、ファイルが Shift-JIS のまま # -*- coding: utf-8 -*- と宣言すると、宣言と実態が食い違い、別のエラーが発生します。このケースは次の「紛らわしい関連エラーの切り分け」で扱います。
なお、文字コード名は表記の揺れが許容されており、utf-8・utf_8・utf8 はいずれも同じコーデックを指すエイリアスです。ハイフンとアンダースコアのどちらで書いても動作します。
紛らわしい関連エラーの切り分け
文字コードに関するエラーは、SyntaxError: Non-UTF-8 code 以外にもいくつかあり、原因と対処が異なります。混同しやすいものを整理します。
(unicode error) ‘utf-8’ codec can’t decode(宣言と実態の不一致)
ファイルを UTF-8 へ変換せず、Shift-JIS のまま 1 行目に # -*- coding: utf-8 -*- と宣言した場合、次のエラーが発生します。
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0x82 in position ...: invalid start byteこれは、宣言では「このファイルは UTF-8」としているのに、実態は Shift-JIS のバイトが入っている、という不一致が原因です。対処は、宣言に合わせてファイル自体を UTF-8 で保存し直すか、宣言を実際の文字コード(cp932 など)に直すことです。
UnicodeDecodeError(実行時にデータファイルを開く場合)
ここまではソースファイル(.py)自体の文字コードの話でしたが、実行時にデータファイルを読み込む際にも、よく似たエラーが発生します。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x82 in position ...: invalid start byteこれは、open() で開いたファイル(CSV やテキストなど)が UTF-8 ではないのに、UTF-8 として読もうとした場合に発生します。Python は、ファイルを開く際の既定エンコーディングが環境に依存するため、明示的に encoding を指定するのが安全です。実際のエンコーディングが Shift-JIS/CP932 であれば、次のように指定します。
# データファイルが CP932 の場合
with open("data.csv", encoding="cp932") as f:
text = f.read()エンコーディングが不明な場合は、前述の charset-normalizer で判定してから開きます。なお、JSON ファイルを読み込む際に「invalid utf-8 start byte」のようなエラーが出る場合も、原因は同じくファイルが UTF-8 でないことにあります。ファイルを UTF-8 に統一するか、読み込み時に正しい encoding を指定することで解決します。
is not utf-8 encoded(バイナリファイルの読み込み)
output.xlsx is not utf-8 encoded のように、Excel ファイル(.xlsx)などをテキストとして UTF-8 で読もうとしてエラーになる場合があります。これは文字コードの問題ではなく、そもそもテキストではないバイナリファイルを、テキストとして開こうとしていることが原因です。この場合は、ファイル形式に対応したライブラリ(Excel なら openpyxl や pandas など)で読み込みます。表形式データの扱いは、関連記事『Backlog API で課題一覧を取得し CSV 出力する手順』も参考になります。
原因の解説: Python はソースコードをどう読んでいるか
Python が日本語 1 文字でエラーになるのは、インタプリタがソースコードを「文字」ではなく「バイト(数値)の列」として読み込んでいるためです。
PEP 263 と既定の UTF-8
Python のソースコードの読み込みルールは、PEP 263 という仕様で定められています。Python 3 では、エンコーディング宣言がない限り、すべてのソースファイルを UTF-8 として扱います。インタプリタはファイルの先頭からバイトを読み、UTF-8 のルールに従って文字へ変換します。ここで Shift-JIS 特有のバイト(例: 0x82)や UTF-16 のバイト(例: 0xff)が現れると、UTF-8 のルールでは解釈できないため、SyntaxError として停止します。
Non-UTF-8 code starting with '\x82' は、「UTF-8 として読み始めたところ、UTF-8 では先頭になり得ないバイト 0x82 が現れた」という指摘です。これが、ソースファイルが UTF-8 でない場合に表示される理由です。
補足: 実行時の UTF-8 モード(最新の動向)
ここまでの話はソースファイルの文字コード(PEP 263)に関するものですが、実行時のファイル入出力や標準入出力の既定エンコーディングについては、別の動きがあります。Python 3.15 からは UTF-8 モードが既定で有効になる予定で、PYTHONUTF8=0 や -X utf8=0 で無効化できます。これにより、とくに Windows 環境で open() の既定エンコーディングに起因する問題が起きにくくなる見込みです。現行バージョンでも、-X utf8 オプションや環境変数 PYTHONUTF8=1 で同じ挙動を先取りできます。
ソースファイルの文字コードと、実行時のファイル入出力の文字コードは別のレイヤーですが、いずれも「UTF-8 に統一しておく」ことで、文字コードに起因するトラブルを減らせます。
参考: PEP 686 – Make UTF-8 mode default(peps.python.org)
“Python will enable UTF-8 mode by default from Python 3.15.”
(Python は 3.15 から UTF-8 モードを既定で有効にします。)
https://peps.python.org/pep-0686/
まとめ
本記事では、Python 実行時に発生する SyntaxError: Non-UTF-8 code starting with の原因と解決策を解説しました。あわせて、文字コードの見分け方や自動判定、紛らわしい関連エラーの切り分けも整理しました。
- 確実な解決はソースファイルを UTF-8 で保存し直すこと
- エラーのバイトは原因の手がかりだが、確定ではない
\xffは Shift-JIS ではなく UTF-16 の可能性が高い- 不明なときは charset-normalizer で判定して変換する
- マジックコメントは実際の文字コードに合わせて宣言する
- 実行時の
UnicodeDecodeErrorはopen()のencoding指定で対処 - ソースも入出力も UTF-8 に統一するとトラブルを減らせる
以上、最後までお読みいただきありがとうございました。

