
はじめに
企業内ネットワークの経路制御で広く採用されているルーティングプロトコルが OSPF(Open Shortest Path First)です。Cisco などの機器に触れたことがあれば、router ospf というコマンドを目にした方も多いと思います。
OSPF は特定のメーカーに依存しないオープン標準(RFC 準拠)のプロトコルで、小規模オフィスから数千台規模のエンタープライズ環境まで、規模を問わず安定して動作します。一方で、学習を始めると「LSA」「エリア」「コスト計算」といった用語が連続し、全体像をつかみにくいのも事実です。
- なぜ RIP ではなく OSPF が選ばれるのか(技術的な根拠)
- LSA・LSDB・コスト・エリア・DR/BDR の仕組み(図解)
- ネットワークタイプやエリア設計で押さえておきたい制約
- 機種別(Cisco / FortiGate / YAMAHA / NEC)の設定手順記事への入口
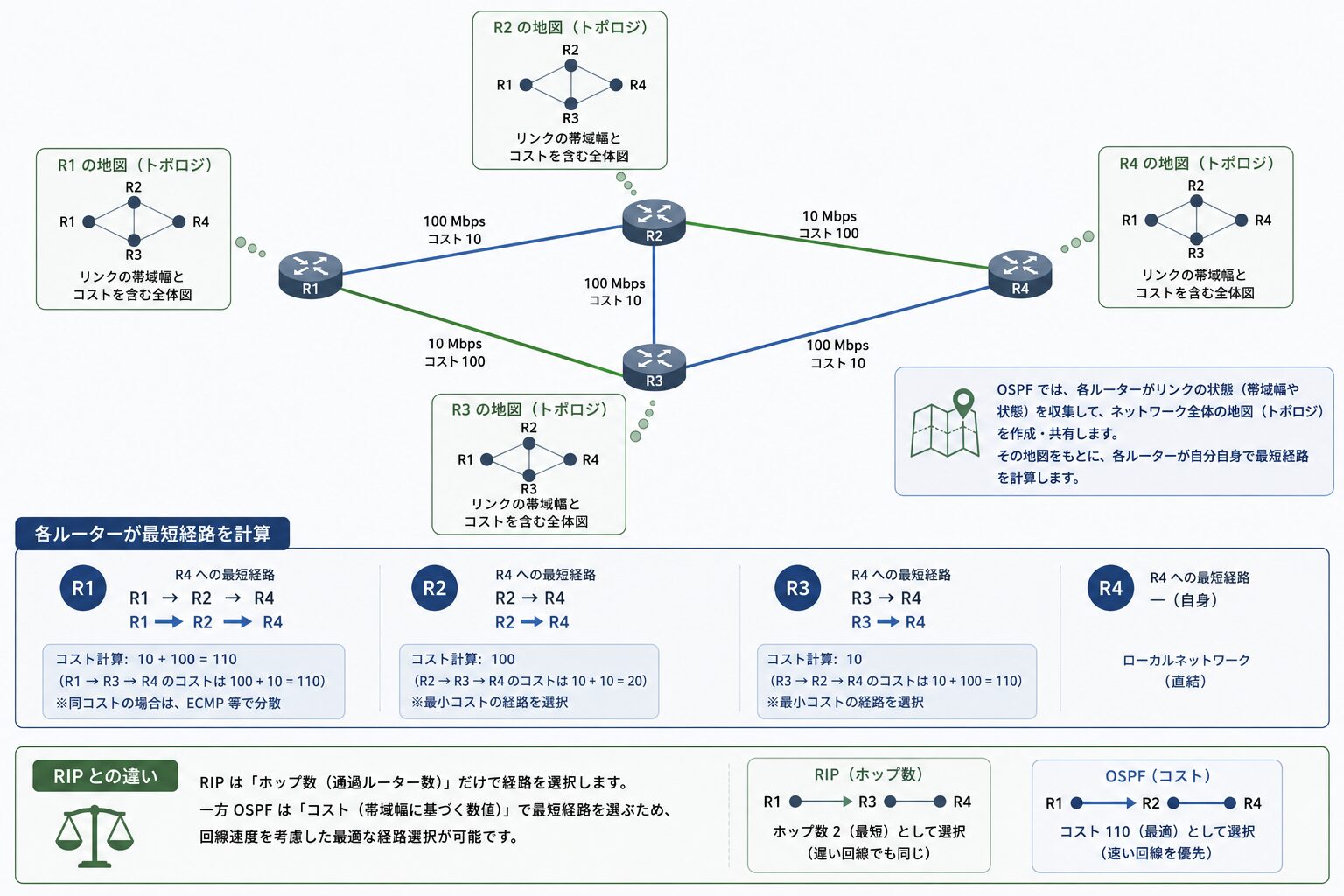
OSPF は、各ルーターがネットワーク全体の地図(トポロジ)を共有し、その地図をもとに帯域幅から算出した「コスト」で最短経路を選びます。RIP のようにホップ数だけで判断しないため、回線速度を反映した経路選択ができる点が最大の違いです。本記事ではこの仕組みを順を追って整理し、機種別の具体的なコンフィグは関連記事へ案内します。
OSPF とは — ネットワークの地図を共有するリンクステート型プロトコル
OSPF は、ネットワーク全体のトポロジ情報を全ルーターで共有し、各自が最短経路を計算するリンクステート型(Link-State)のルーティングプロトコルです。IETF によって標準化されており、IPv4 向けの OSPFv2 は RFC 2328、IPv6 向けの OSPFv3 は RFC 5340 で規定されています。
動作の起点となるのが、各ルーターが自分の周囲の接続状況を記述した LSA(Link State Advertisement)です。ルーター同士が LSA を交換(フラッディング)し、集めた情報を LSDB(Link State Database)という共通のデータベースに蓄積します。同一エリア内の全ルーターが同じ LSDB を持つ状態(同期)を目指すことで、どのルーターからでも一貫した最短経路を導き出せます。
OSPF が支持される 5 つの特徴
OSPF が広く使われる理由は、次の 5 点に集約できます。各項目の詳細は後続のセクションで掘り下げます。
帯域幅ベースの最短経路選択:
ホップ数ではなくコスト(回線速度から算出した値)で経路を選ぶため、低速回線を誤って優先しにくい。
高速な収束:
障害を検知すると差分情報を即座に拡散し、新しい経路を再計算する。
エリアによるスケーラビリティ:
ネットワークをエリア単位で分割し、詳細計算を局所化することで大規模環境でも負荷を抑える。
差分更新による帯域効率:
平常時は小さな Hello パケットのみで、変化があったときだけ差分 LSA を送信する。マルチキャスト(224.0.0.5 / 224.0.0.6)を用いて関係のない端末に負荷をかけない。
マルチベンダー対応:
オープン標準のため、Cisco・Juniper・YAMAHA・Arista など異なるメーカーが混在する環境でも相互接続できる。
RIP・EIGRP との違い
同じ IGP(Interior Gateway Protocol)に分類される RIP・EIGRP と比較すると、OSPF の位置づけが整理しやすくなります。
| 項目 | RIP | OSPF | EIGRP |
|---|---|---|---|
| 種別 | ディスタンスベクター | リンクステート | ハイブリッド(拡張ディスタンスベクター) |
| メトリック | ホップ数 | コスト(帯域ベース) | 複合メトリック(帯域・遅延など) |
| 最大ホップ数 | 15 | 実質制限なし | 255(既定 100) |
| 更新方式 | 定期(30 秒)に全経路 | 変化時に差分 LSA | 変化時に差分 |
| 管理距離(AD) | 120 | 110 | 90(内部)/ 170(外部) |
| 標準化 | オープン標準(RFC 2453) | オープン標準(RFC 2328) | RFC 7868(情報提供目的)※実装は限定的 |
| 適用規模 | 小規模 | 小〜大規模 | 中〜大規模(主に Cisco 環境) |
RIP はホップ数だけで判断するため、低速でも経由ルーターが少ない経路を選んでしまう弱点があります。EIGRP は高機能ですが、もともと Cisco 独自プロトコルとして開発された経緯があり、RFC 7868 として公開されたものの標準化トラックの仕様ではなく、マルチベンダーでの実装は限られています。将来的に他社製品が混在する可能性があるなら、世界標準の OSPF を選ぶ判断が無難です。
参考: Cisco Secure Firewall 設定ガイド(EIGRP)
“it is now an open standard defined in RFC 7868”
(EIGRP は現在、RFC 7868 で定義されたオープン標準となっています。)
https://www.cisco.com/c/en/us/td/docs/security/firepower/720/fdm/fptd-fdm-config-guide-720/fptd-fdm-eigrp.html
最短経路を選ぶ「コスト」の仕組み
OSPF は、完成した LSDB(地図)をもとに、コスト(Cost)という値で経路を選びます。コストは基本的に回線の帯域幅から算出され、帯域が大きい(速い)リンクほどコストが小さくなります。複数経路がある場合は、合計コストが最小となる経路が最短経路として選ばれます。
コストの計算式と既定の参照帯域
コストは、参照帯域(リファレンスバンド幅)をインターフェース帯域で割って求めます。Cisco 機器の既定の参照帯域は 100 Mbps(10^8 bps)です。
参考: Cisco「Review OSPF Frequently Asked Questions」
“The formula to calculate the cost is reference bandwidth divided by interface bandwidth.”
(コストの計算式は、参照帯域をインターフェース帯域で割ったものです。)
https://www.cisco.com/c/en/us/support/docs/ip/open-shortest-path-first-ospf/9237-9.html
既定値(参照帯域 100 Mbps)での計算結果は次のとおりです。算出値が 1 未満になる場合は最小値の 1 に丸められます。
| インターフェース | 帯域 | 既定コスト(参照帯域 100 Mbps) |
|---|---|---|
| Ethernet | 10 Mbps | 10 |
| FastEthernet | 100 Mbps | 1 |
| GigabitEthernet | 1 Gbps | 1(100 / 1000 = 0.1 → 1 に丸め) |
| 10GbE | 10 Gbps | 1 |
| シリアル(T1) | 1.544 Mbps | 64 |
この表からわかるとおり、既定のままでは 100 Mbps 以上の高速インターフェースがすべてコスト 1 となり、1 Gbps と 10 Gbps を区別できません。
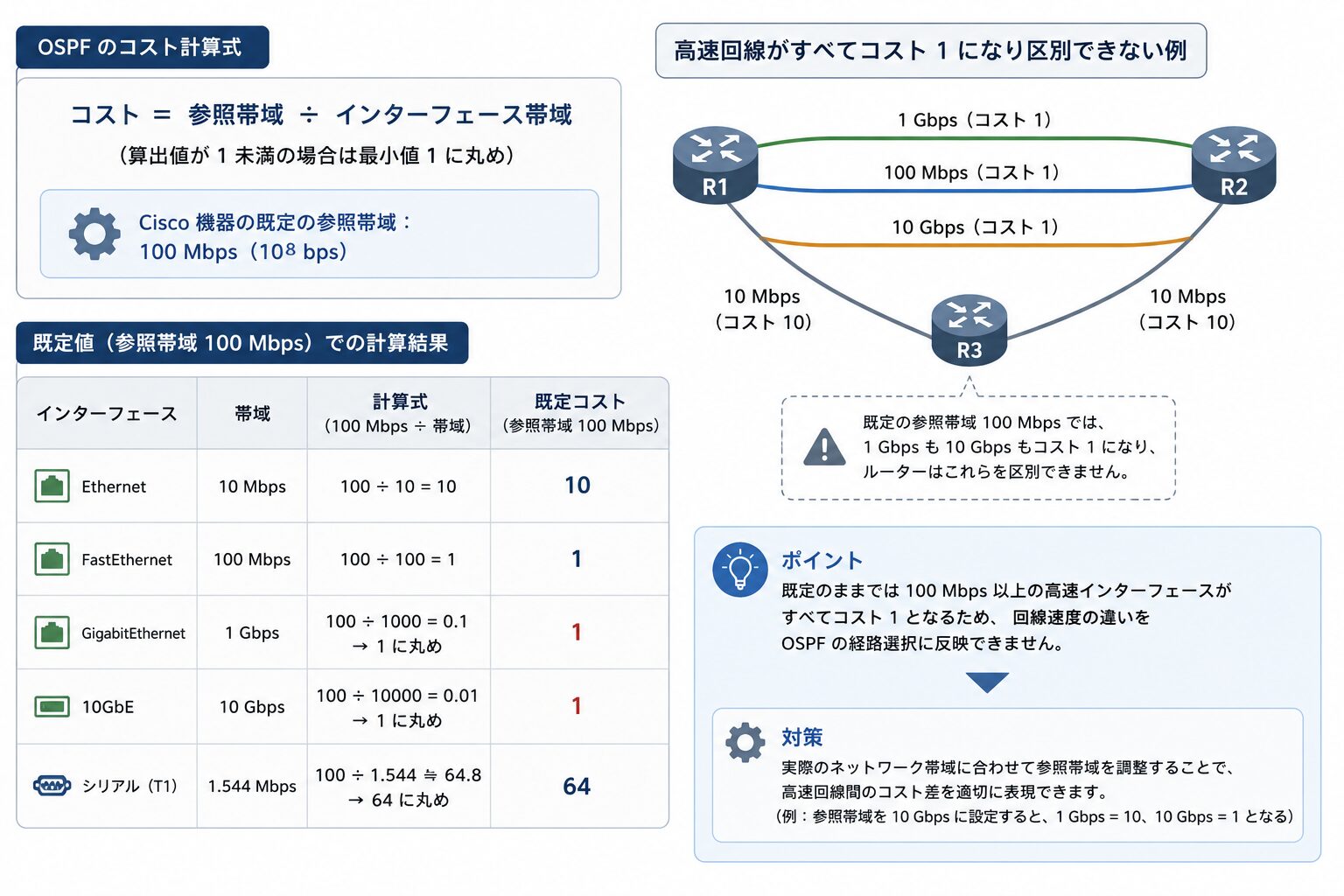
参照帯域の見直し(auto-cost reference-bandwidth)
高速回線を正しく区別するには、auto-cost reference-bandwidth で参照帯域を引き上げます。たとえば 10 Gbps 環境なら 10000、100 Gbps 環境なら 100000(Mbps 単位)を指定します。参照帯域はルーターごとに独立して計算されるため、同一 OSPF ドメイン内のすべてのルーターで同じ値に統一することが推奨されます。値が混在すると、ルーターごとにコスト計算が食い違い、意図しない経路選択につながります。具体的な設定コマンドは Cisco 設定記事で扱います。
等コストロードバランシング(ECMP)
計算した結果、複数の経路がまったく同じコストになった場合、OSPF は自動的に両方の経路へ通信を分散させます。これを ECMP(Equal Cost Multi Path)と呼びます。特別な設定なしで帯域を有効活用できる点が OSPF の利点の一つです。なお Cisco 機器では既定で最大 4 経路まで負荷分散し、maximum-paths コマンドで最大 32 経路まで拡張できます。
高速な収束と効率的な更新
OSPF が大規模ネットワークで信頼される理由は、障害発生時の復旧の速さと、平常時のネットワーク負荷の少なさを両立している点にあります。これを支えるのが、差分のみを伝える更新方式と、隣接ルーターの死活監視の仕組みです。
変化があったときだけ送る差分更新
RIP は変化の有無にかかわらず、30 秒ごとに全経路情報を送信します。これは帯域を消費するうえ、障害時も次の周期を待つため復旧が遅れがちです。
一方 OSPF は、LSDB の同期が完了したあとは Hello パケットによる死活確認のみを行い、リンクダウンなどの変化を検知した瞬間に、差分の LSA だけを即座に拡散します。この差分更新により、平常時の帯域消費を抑えつつ、障害時には新しい経路へ素早く切り替えられます。
Hello / Dead タイマーと障害検知
OSPF は隣接ルーターとの間で Hello パケットを定期的に交換し、一定時間(Dead Interval)応答がなければ、その隣接が失われたと判断します。ケーブルが物理的に抜けた場合を除き、基本的にはこの Dead Interval の満了を待ってから障害と判断します。
参考: Cisco「What Does the show ip ospf interface Command Reveal」
“On broadcast and point-to-point links, the default is 10 seconds.”
(broadcast および point-to-point リンクでは、既定値は 10 秒です。)
https://www.cisco.com/c/en/us/support/docs/ip/open-shortest-path-first-ospf/13689-17.html
Dead Interval は既定で Hello Interval の 4 倍です。broadcast / point-to-point では Hello 10 秒・Dead 40 秒、NBMA では Hello 30 秒・Dead 120 秒が既定値となります。より速い検知が必要な場合は、Hello タイマーを短くするか、BFD(Bidirectional Forwarding Detection)を併用することでサブセカンド級の検知も可能です。タイマー値は隣接するルーター間で一致している必要があります。
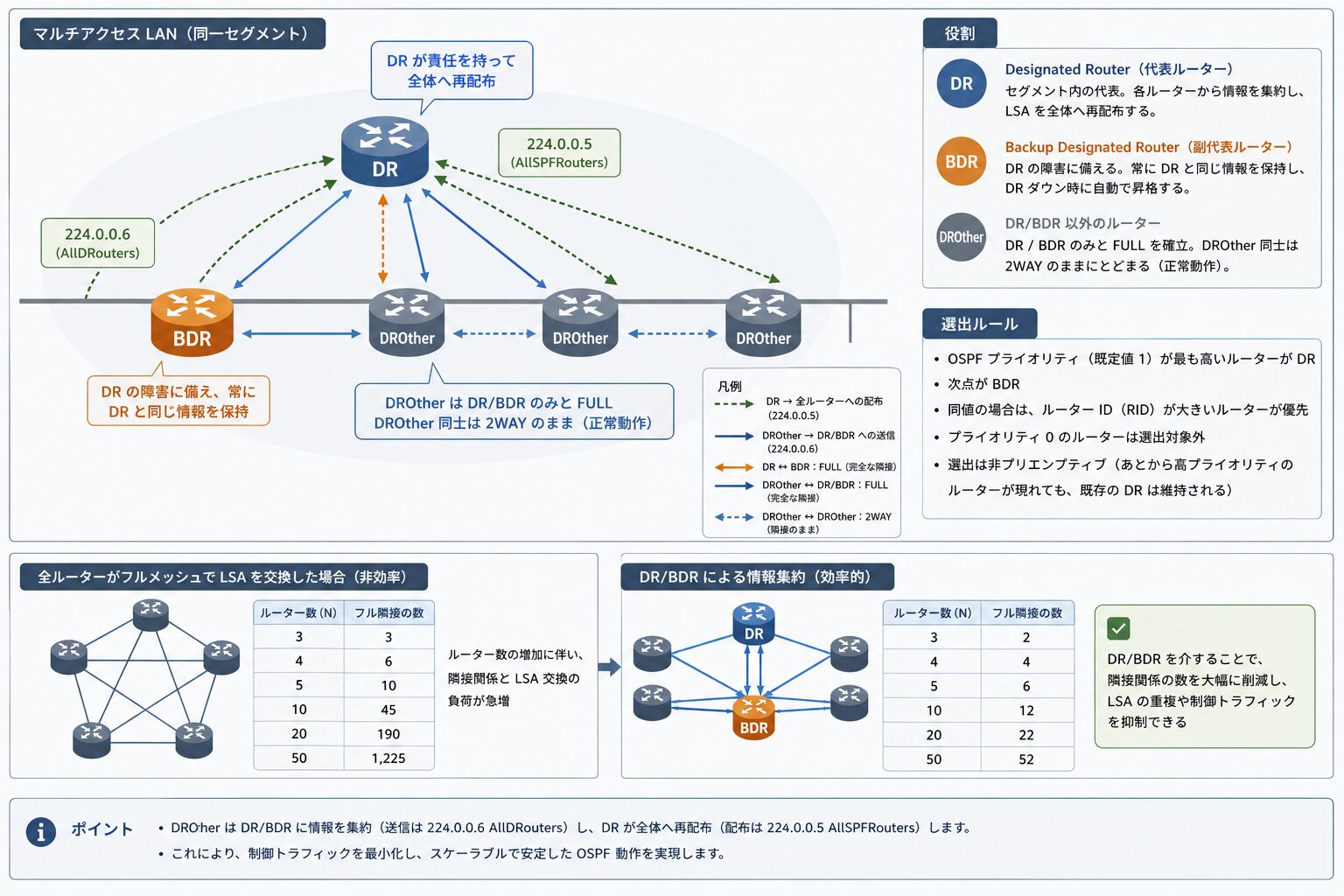
DR / BDR — マルチアクセスでの情報集約
イーサネット LAN のように、同一セグメントに複数のルーターが接続するマルチアクセス環境では、全ルーターが互いに LSA を交換すると情報が重複し、隣接関係の数が増えすぎます。これを整理するために、OSPF はセグメント内の代表ルーターを選出します。
DR(Designated Router):
セグメント内の代表。各ルーターは DR に情報を集約し、DR が責任を持って全体へ再配布する。
BDR(Backup Designated Router):
DR の障害に備える副代表。常に DR と同じ情報を保持し、DR がダウンした際に昇格する。
DR / BDR 以外のルーター(DROther)は、DR / BDR とのみ FULL(完全な隣接)を確立し、DROther 同士は 2WAY のままにとどまります。これは正常な動作で、隣接関係の数を抑える狙いがあります。情報のやり取りには、DROther から DR / BDR への送信に 224.0.0.6(AllDRouters)、DR から全ルーターへの配布に 224.0.0.5(AllSPFRouters)のマルチキャストアドレスを使用します。
DR の選出は、OSPF プライオリティ(既定値 1)が最も高いルーターが DR、次点が BDR となり、同値の場合はルーター ID(RID)が大きいルーターが優先されます。プライオリティ 0 のルーターは選出対象から除外されます。なお選出は非プリエンプティブで、あとから高プライオリティのルーターが現れても、既存の DR は維持されます。
OSPF のネットワークタイプ
OSPF は、インターフェースが接続する媒体の性質に応じて「ネットワークタイプ」を切り替えます。ネットワークタイプによって、DR / BDR を選出するかどうか、既定の Hello / Dead タイマー、ネクストホップの扱いが変わります。両端のインターフェースでタイプが一致していないと、隣接が確立できない、または不安定になる原因となります。
| ネットワークタイプ | 代表的な媒体 | DR / BDR 選出 | 既定 Hello / Dead |
|---|---|---|---|
| broadcast | イーサネット LAN | あり | 10 / 40 秒 |
| non-broadcast(NBMA) | フレームリレー、X.25 | あり | 30 / 120 秒 |
| point-to-point | シリアル、PPP、GRE トンネル | なし | 10 / 40 秒 |
| point-to-multipoint | 部分メッシュ | なし | 30 / 120 秒 |
イーサネットの既定は broadcast で、DR / BDR を選出します。2 台のみを接続する point-to-point では代表選出が不要なため、より早く FULL に到達します。NBMA はマルチキャストが使えない媒体向けで、隣接先を手動指定する必要があります。インターフェースの現在のタイプは show ip ospf interface で確認できます(出力例は機種別の設定記事で扱います)。
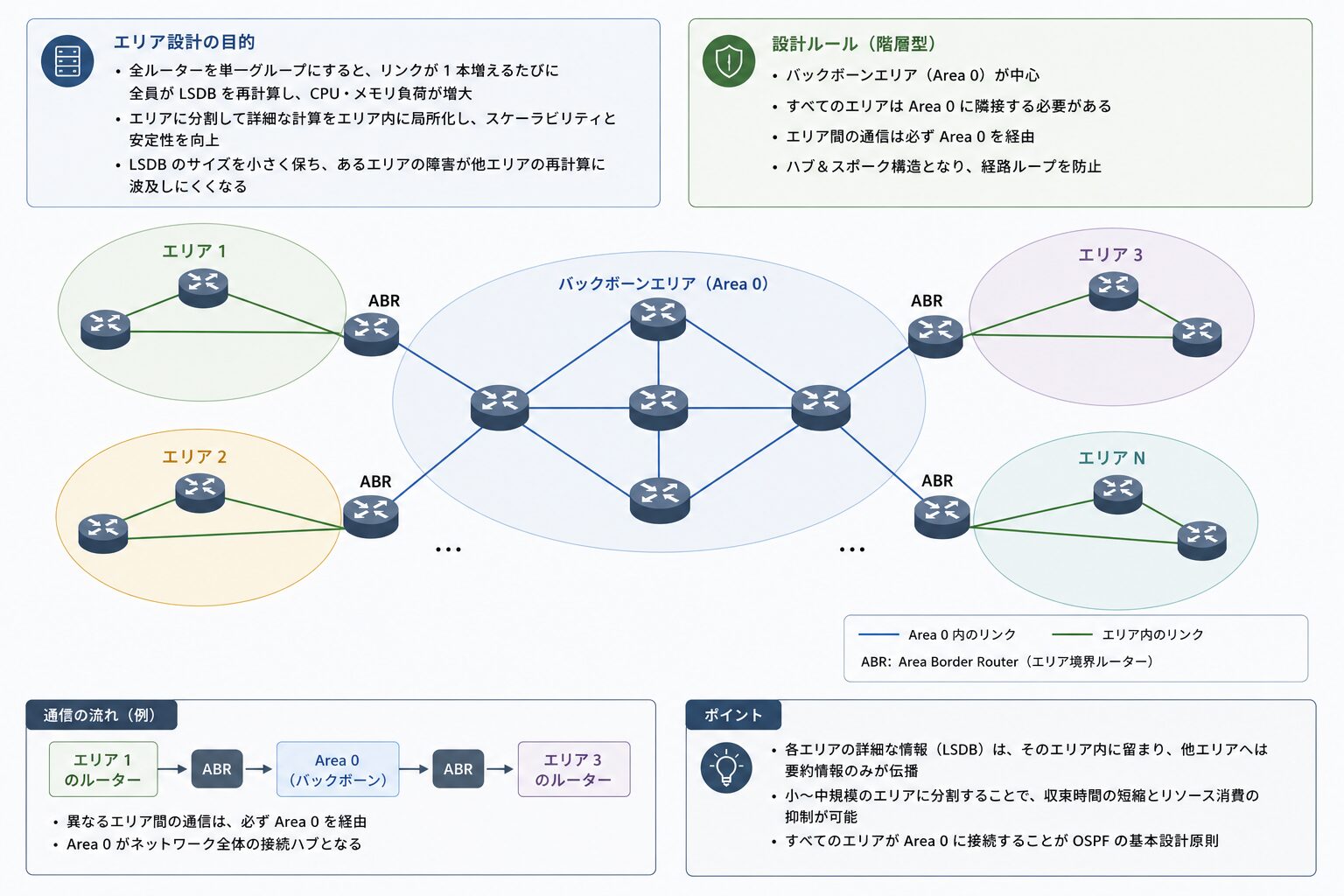
エリア設計 — スケーラビリティとバックボーン
全ルーターを単一のグループに収容すると、リンクが 1 本増えるたびに全員が LSDB を再計算することになり、CPU やメモリの負荷が増大します。OSPF はネットワークを「エリア(Area)」に分割し、詳細な計算をエリア内に局所化することで、この問題を抑えます。エリアを分けることで、LSDB のサイズを小さく保ち、あるエリアの障害が他エリアの再計算に波及しにくくなります。
エリアを接続する際には階層型の設計ルールがあります。中心となるのがバックボーンエリア(Area 0)で、他のすべてのエリアは Area 0 に隣接する必要があります。エリア間の通信は必ず Area 0 を経由するため、ネットワークがハブ&スポーク状の構造となり、経路のループを防げます。
LSA の主なタイプ
LSA は役割ごとに種類が分かれています。OSPFv2 で実務上よく扱うのは次のタイプです。
| タイプ | 名称 | 主な生成元 | 伝搬範囲 |
|---|---|---|---|
| Type 1 | Router LSA | 各ルーター | エリア内 |
| Type 2 | Network LSA | DR | エリア内(マルチアクセス) |
| Type 3 | Summary LSA | ABR | エリア間 |
| Type 4 | ASBR Summary LSA | ABR | エリア間(ASBR への経路) |
| Type 5 | AS External LSA | ASBR | AS 全体(スタブを除く) |
| Type 7 | NSSA External LSA | NSSA 内の ASBR | NSSA 内(ABR で Type 5 へ変換) |
エリアをまたぐ Type 3 / Type 4 は ABR(Area Border Router)が、外部から再配布された経路を表す Type 5 は ASBR(AS Boundary Router)が生成します。
エリアの種類(スタブ・NSSA など)
エリアは、通過させる LSA を制限することで、エリア内のルーターが保持する情報量を減らせます。代表的な種別は次のとおりです。
| エリア種別 | 通過する主な LSA | 外部経路の扱い |
|---|---|---|
| 標準(Normal) | Type 1〜5 | 通常どおり通過 |
| バックボーン(Area 0) | Type 1〜5 | 全エリアの中継点 |
| スタブ(Stub) | Type 1〜3 | Type 5 を遮断し、既定経路で代替 |
| 完全スタブ(Totally Stubby)※Cisco 独自 | Type 1〜2 | Type 3〜5 を遮断し、既定経路のみ |
| NSSA | Type 1〜3、7 | Type 7 で外部再配布を許可 |
| 完全 NSSA(Totally NSSA)※Cisco 独自 | Type 1〜2、7 | Type 3 も遮断 |
スタブエリアは外部経路(Type 5)を遮断して LSDB を小さく保つ設計です。一方で、エリア内に ASBR を置いて外部経路を再配布したい場合は、NSSA(Not-So-Stubby Area)を用います。
参考: Cisco「Configure the OSPF Not-So-Stubby Area (NSSA)」
“Type 5 LSAs are not allowed in NSSA areas”
(NSSA エリアでは Type 5 LSA は許可されません。)
https://www.cisco.com/c/en/us/support/docs/ip/open-shortest-path-first-ospf/6208-nssa.html
NSSA では外部経路を Type 7 として生成し、ABR がこれを Type 5 に変換して他エリアへ伝搬します。完全スタブ・完全 NSSA は Cisco 独自の拡張で、エリア間経路(Type 3)も遮断してさらに情報量を絞り込みます。
OSPF の基本設定 — Cisco ルーターでの有効化
ここでは OSPF を動かすための最小限の設定を確認します。マルチエリア構成や参照帯域の調整、認証など、踏み込んだコンフィグは Cisco 設定記事で扱います。具体的な手順は関連記事『Cisco ルーターでの OSPF 設定手順とマルチエリア構成のコンフィグ例』を参照してください。
OSPF の有効化とエリアへの参加
OSPF はプロセス ID を指定して有効化し、参加させるインターフェースとエリアを network コマンドで指定します。
Router(config)# router ospf 1
Router(config-router)# network 192.168.1.0 0.0.0.255 area 0プロセス ID は 1〜65535 の範囲で、ルーター内で OSPF を識別する局所的な番号です。隣接するルーターと一致している必要はありません。network コマンドのワイルドカードマスクはサブネットマスクのビット反転で、/24(255.255.255.0)なら 0.0.0.255 となります。
参考: Cisco IOS IP Routing: OSPF Command Reference(network area)
“The wildcard-mask argument is logically ORed with the ip-address argument in the network command.”
(ワイルドカードマスク引数は、network コマンドの IP アドレス引数と論理 OR されます。)
https://www.cisco.com/c/en/us/td/docs/ios-xml/ios/iproute_ospf/command/iro-cr-book/ospf-i1.html
状態確認の基本コマンド
設定後は、隣接の確立と経路の学習を確認します。
show ip ospf neighbor:
隣接状態を確認する。FULL であれば LSDB の交換が完了している。マルチアクセスでは DROther 同士が 2WAY で止まるのは正常な動作
show ip route ospf:
学習した OSPF 経路を確認する。先頭の O が OSPF 由来の経路を表す。
show ip ospf interface:
インターフェースのネットワークタイプやタイマー、コストを確認する。
各コマンドの詳細な出力例や、マルチエリア・ルート要約・認証の設定は、機種別の設定記事で扱います。
OSPF を導入する際の注意点・制約
OSPF は柔軟で高機能なプロトコルですが、導入・運用にあたって押さえておきたい制約もあります。メリットだけでなく、これらの前提を理解しておくことで、設計時の手戻りやトラブルを抑えられます。
隣接確立には複数の条件一致が必要
OSPF の隣接(ネイバー)は、いくつかの値が一致しないと確立できません。代表的な確認項目は次のとおりです。
- Hello / Dead タイマーの一致
- エリア ID の一致
- ネットワークタイプの整合(broadcast と point-to-point の混在など)
- サブネットマスク・サブネットの一致
- 認証設定(鍵・方式)の一致
- インターフェース MTU の一致。MTU が食い違うと、隣接が
ExStartやExchangeの状態で停止することがあります。
これらの切り分け手順は、関連記事『OSPF のネイバー確立トラブル|下位レイヤから切り分ける原因特定手順』で詳しく扱っています。
設計とリソースに関する制約
エリア設計の制約:
すべてのエリアは Area 0 に隣接する必要があり、エリアをまたぐ通信は Area 0 を経由します。Area 0 から分離したエリアを作る場合は、仮想リンク(virtual-link)などの追加設計が必要になります。
CPU・メモリ負荷:
大規模な単一エリアでは LSDB が肥大化し、SPF 計算の負荷が増えます。リンクが頻繁に上下動(フラッピング)する環境では、再計算が繰り返され負荷が高まります。エリア分割やスタブ化、ルート要約で LSDB を抑える設計が有効です。
設計難易度:
コスト設計、エリア境界での経路要約、再配布など、適切に運用するには相応の設計知識が求められます。小規模で経路数が少ない環境では、スタティックルートのほうが運用がシンプルな場合もあります。
機種別の設定手順(対応機種の一覧)
OSPF はマルチベンダーで相互接続できますが、設定コマンドや GUI 操作は機種ごとに異なります。本ブログでは機種別に設定手順を用意しています。利用機器に合わせて参照してください。
| 機種・シリーズ | 設定インターフェース | 記事 |
|---|---|---|
| Cisco IOS / IOS XE ルーター | CLI(router ospf) | OSPF 設定手順とマルチエリア構成(公開済み) |
| FortiGate | GUI / CLI | 準備中 |
| YAMAHA RTX シリーズ | CLI(ospf コマンド) | 準備中 |
| NEC IX シリーズ | CLI | 準備中 |
Cisco 環境で Multi-VRF(VRF-Lite)と OSPF を組み合わせる場合は、capability vrf-lite や DN ビットの扱いに固有の注意点があります。詳細は関連記事『capability vrf-lite と DN Bit の役割|OSPF Multi-VRF の落とし穴』を参照してください。
まとめ
OSPF はリンクステート型の IGP として、ネットワーク全体のトポロジ情報を共有し、帯域から算出したコストで最短経路を選びます。RIP のホップ数方式と異なり回線速度を反映でき、エリア分割によって大規模環境にも対応します。仕組みを押さえておけば、機種を問わず設計・運用に応用できます。
- LSA を交換し LSDB(共通の地図)を同期する動作原理
- 参照帯域を基準に算出する帯域ベースのコスト計算
- 既定参照帯域 100 Mbps による高速回線の区別不可と対処
- マルチアクセスでの DR / BDR による情報集約
- 媒体に応じて変わるネットワークタイプとタイマー
- Area 0 を中心とする階層型のエリア設計
- スタブ・NSSA による LSA 制限と LSDB の最適化
以上、最後までお読みいただきありがとうございました。

