

はじめに
VMware vSphere の HA(High Availability)は、ESXi ホスト障害時に仮想マシンを別ホスト上で自動的に再起動させる、仮想化基盤の中核機能です。
しかし、HA をクラスタで有効化した直後、設定自体は正しいはずなのにホストに警告(黄色い三角マーク)が表示され、以下のメッセージが出るケースがよくあります。
- 「このホストには現在管理ネットワークの冗長性がありません」
- 「このホストの vSphere HA ハートビートデータストア数は 0 で、必要数の 2 未満です」
これらは、物理 NIC やストレージのパスが 1 つしかない小規模環境や、検証環境でも頻発する仕様上の警告です。本番環境であれば物理構成の見直しが望ましいですが、検証環境では「意図的な構成」であるため、警告を非表示にしたいケースが少なくありません。
本記事では、これら 2 つの警告を抑制するための HA 詳細オプション(das 系パラメータ) の設定手順を、Broadcom 公式ドキュメントに基づいて整理します。あわせて、警告抑制以外の HA 詳細オプション(Isolation Address、ハートビート数の調整など)や、vSAN 環境での推奨設定についてもリファレンスとしてまとめます。
- 警告が表示される原因と、HA の二重監視(ネットワーク・ストレージ)の仕組み
- das.ignoreRedundantNetWarning / das.ignoreInsufficientHbDatastore による警告抑制手順
- 設定変更後に クラスタ HA を無効化 → 再有効化 する正しい反映手順
- HA 詳細オプションの主要パラメータ一覧(Isolation Address、ハートビート数など)
- vSAN 環境での推奨設定
- 本番環境と検証環境での運用上の判断
なぜ警告が表示されるのか(HA の仕組みと要件)
vSphere HA が正常に機能するためには、ホスト間の生存確認(ハートビート)が継続的に成立している必要があります。ホストが故障していないにもかかわらず通信だけが途切れた場合、HA が誤判定して正常に動作している仮想マシンを別ホストで再起動してしまう「スプリットブレイン」状態を引き起こす可能性があります。
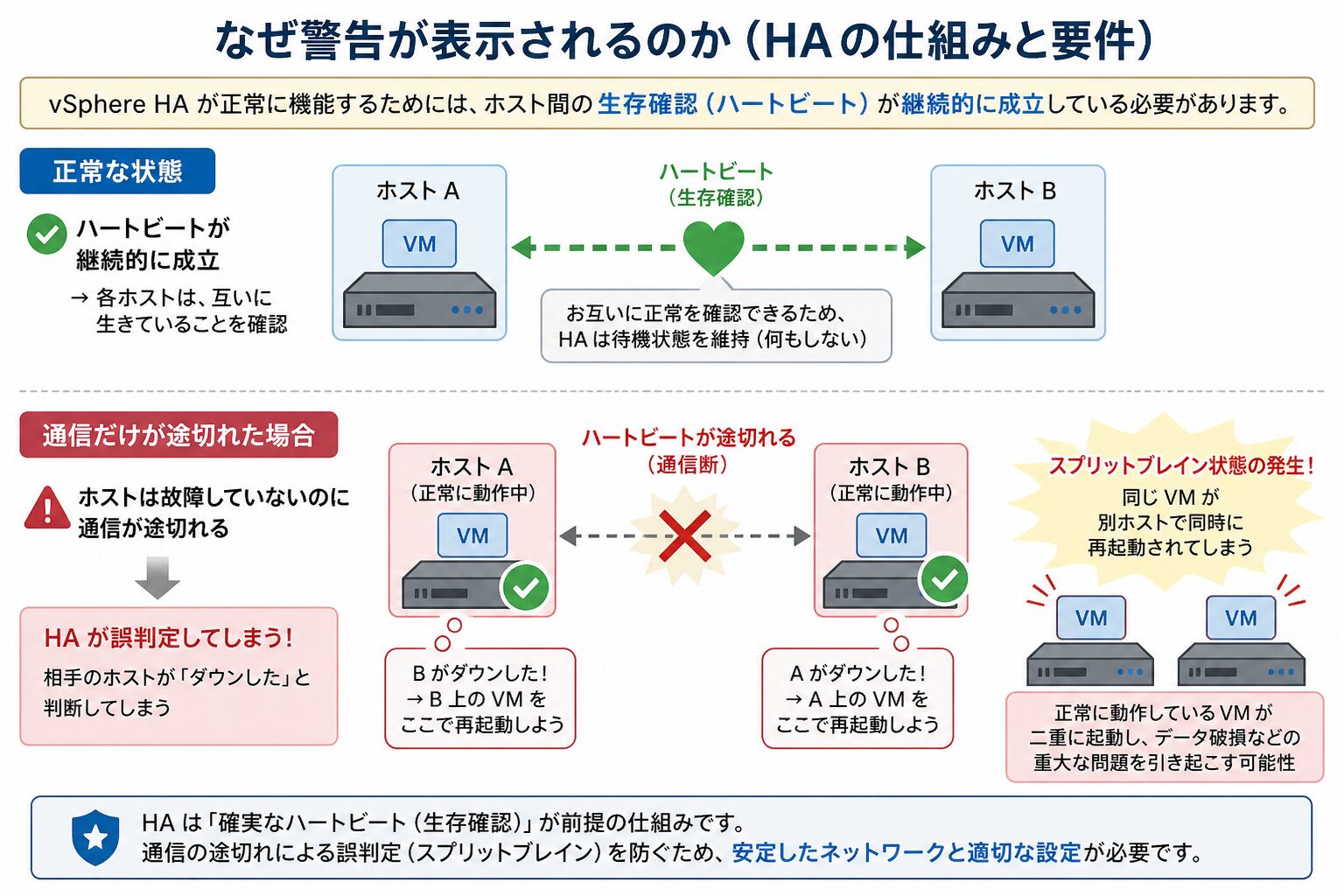
これを防ぐために、vSphere HA は 2 つの独立した経路 で生存確認を行います。
| # | 経路 | 役割 | 推奨構成 |
|---|---|---|---|
| 1 | 管理ネットワーク(Management Network) | 主たる生存確認経路。ホスト間で定期的にハートビート信号を送受信 | NIC を 2 本以上で冗長化(NIC チーミング) |
| 2 | ハートビートデータストア(Datastore Heartbeating) | 補助的な生存確認経路。ネットワーク経路が断絶した際にストレージ書き込みを通じて生存を確認 | 共有データストアを 2 つ以上 |
参考: vSphere HA Provides Rapid Recovery from Outages – Broadcom TechDocs(vSphere 8.0)
“vSphere HA also uses datastore heartbeating to identify the failure type when the master host can no longer communicate with the host’s network.”
(vSphere HA は、マスターホストがネットワーク経由でホストと通信できなくなった際に、障害種別を判別するためデータストアハートビートを使用します)
https://techdocs.broadcom.com/us/en/vmware-cis/vsphere/vsphere/8-0/vsphere-availability/how-vsphere-ha-works.html
このような 二重の冗長性 が満たされていない構成(NIC が 1 本しかない、共有データストアが 1 つだけなど)の場合、vSphere HA はリスクを示す警告を表示します。
警告 1: 管理ネットワークの冗長性がありません
HA を有効化した際、多くの環境で最初に表示されるのがこの警告です。
このホストには現在管理ネットワークの冗長性がありません
(This host currently has no management network redundancy)メッセージの意味
管理ネットワーク(Management Network)に割り当てられている物理 NIC(vmnic)が 1 本しかない、または複数 NIC があっても全てが同一の物理スイッチに接続されており、経路が単一障害点になっている状態を示します。
推奨構成: 物理的な冗長化(NIC チーミング)
本番環境では、物理層の冗長化が望ましい解決策です。
- NIC を 2 本以上にする: 管理ネットワーク用 vSwitch に物理 NIC を 2 本以上割り当て、NIC チーミングを構成
- 物理スイッチを分ける: 可能であれば各 NIC を異なる物理スイッチに接続し、スイッチ障害にも対応
検証環境向けの回避策: 詳細オプションで警告を抑制
ホームラボや物理ポートに余裕がない小型サーバなど、NIC 1 本での運用が前提となる環境では、HA 詳細オプションで警告を抑制できます。
| 設定キー | 設定値 |
|---|---|
das.ignoreRedundantNetWarning | true |
参考: Network redundancy message when configuring vSphere High Availability – Broadcom Knowledge
“To suppress this message on ESXi and ESX hosts in the vSphere High Availability (HA) cluster, set the VMware HA advanced option das.ignoreRedundantNetWarning to true and reconfigure VMware HA on that host.”
(クラスタ内の ESXi ホストでこのメッセージを抑制するには、HA 詳細オプション das.ignoreRedundantNetWarning を true に設定し、対象ホストで HA を再構成します)
https://knowledge.broadcom.com/external/article/317612/network-redundancy-message-when-configur.html
なお、この設定はあくまで 警告表示を抑制するもの であり、ネットワーク経路自体を冗長化するわけではありません。経路が単一障害点である事実は変わらないため、本番環境では物理的な冗長化を優先することをおすすめします。
警告 2: ハートビートデータストア数が 2 未満です
共有ストレージが少ない環境で発生する警告です。
このホストの vSphere HA ハートビートデータストア数は 0 で、必要数の 2 未満です
(The number of heartbeat datastores for host is 0, which is less than required: 2)メッセージの意味
ネットワーク障害時の補助的な生存確認経路(ハートビートデータストア)として、vSphere HA は デフォルトで 2 つ以上の共有データストア を要求します。マウント済み共有データストアが 1 つ以下の環境ではこの警告が表示されます。
推奨構成: データストアの追加
信頼性の観点では、補助経路を複数確保することが望ましい構成です。
- データストアを追加する: 別の iSCSI ターゲットや NFS サーバを用意し、ESXi ホストにマウント
- LUN を分ける: 同一ストレージ筐体でも、別 LUN を切り出してマウントすることで論理的な冗長性を確保できる場合がある
回避策 1: 警告を抑制する(要件を無視)
共有ストレージが 1 台しかない NAS 環境などで要件を満たせない場合は、以下のオプションで警告を抑制します。
| 設定キー | 設定値 |
|---|---|
das.ignoreInsufficientHbDatastore | true |
参考: HA error: The number of heartbeat datastores for host is 1, which is less than required: 2 – Broadcom Knowledge
“Use the below steps with caution as this will only disable the error, not fix the error.”
(以下の手順は警告のみを抑制するものであり、根本原因の解決にはなりません。注意して使用してください)
https://knowledge.broadcom.com/external/article/318871/ha-error-the-number-of-heartbeat-datasto.html
回避策 2: 要求数そのものを変更する(要件を緩和)
警告を完全に無視するのではなく、要求するハートビートデータストアの最小数を調整する という方法もあります。
| 設定キー | 設定値(既定) | 設定可能範囲 |
|---|---|---|
das.heartbeatDsPerHost | 2 | 2〜5 |
ただし das.heartbeatDsPerHost の最小値は仕様上 2 であるため、共有ストレージが 1 つしかない環境では設定を下げることはできません。そのような環境では回避策 1(das.ignoreInsufficientHbDatastore)を選択することになります。
逆に 共有ストレージが豊富な環境では、3〜5 に増やすことで補助経路の信頼性を高められます。可用性を重視する本番環境ではこちらの方向の調整が有効です。
回避策利用時の運用上の注意
das.ignoreInsufficientHbDatastore = true で警告を抑制した場合、ハートビートデータストアによる補助的な生存確認の信頼性が低下します。万が一管理ネットワークが断絶した際に、HA がホスト障害とネットワーク分断を区別できず、誤判定によるフェイルオーバ動作のリスクが残ることに留意が必要です。
HA 詳細オプションのリファレンス(用途別カテゴリ)
ここまで紹介した警告抑制系の 2 つに加えて、vSphere HA には現場で利用頻度の高い詳細オプションが複数存在します。用途別に整理して以下にまとめます。
参考: vSphere HA Advanced Options – Broadcom TechDocs(vSphere 8.0)
“If you change the value of any of the following advanced options, you must deactivate and then re-activate vSphere HA before your changes take effect.”
(以下の Advanced Option の値を変更する場合、変更を反映させるには vSphere HA を一度無効化してから再有効化する必要があります)
https://techdocs.broadcom.com/us/en/vmware-cis/vsphere/vsphere/8-0/vsphere-availability/creating-and-using-vsphere-ha-clusters/configuring-cluster-settings/set-advanced-options/vsphere-ha-advanced-options.html
カテゴリ A: 警告抑制系
冗長性が不足している環境で、警告そのものを表示しないようにするオプションです。
| 設定キー | 既定値 | 用途 |
|---|---|---|
das.ignoreRedundantNetWarning | false | 管理ネットワーク冗長性の警告を抑制 |
das.ignoreInsufficientHbDatastore | false | ハートビートデータストア不足警告を抑制 |
カテゴリ B: ハートビートデータストア制御系
ハートビートデータストアの要求数を制御するオプションです。
| 設定キー | 既定値 | 設定可能範囲 | 用途 |
|---|---|---|---|
das.heartbeatDsPerHost | 2 | 2〜5 | 各ホストに割り当てるハートビートデータストアの数を変更 |
das.iostatsInterval | 120 | 秒単位 | VM 監視機能(VM Monitoring)が VM の I/O 状態を確認する間隔 |
ハートビートデータストアそのものの選定(vSphere が自動選択するか、管理者が手動指定するか)は、vSphere Client の [vSphere の可用性] → [編集] → [ハートビートデータストア] タブで設定できます。詳細オプションではなく GUI 上で完結する設定です。
カテゴリ C: Isolation Address(ホスト分離検出)系
ESXi ホストが「自分はネットワーク的に孤立しているか」を判定するための ping 先アドレスを制御するオプション群です。vSAN 環境や、デフォルトゲートウェイが ICMP に応答しない環境では設定変更が事実上求められます。
| 設定キー | 既定値 | 値の例 | 用途 |
|---|---|---|---|
das.usedefaultisolationaddress | true | false | 既定のデフォルトゲートウェイを Isolation Address として使用するか |
das.isolationaddress0 | (未設定) | 192.0.2.1 | 追加の Isolation Address(0 番目) |
das.isolationaddress1 | (未設定) | 192.0.2.2 | 追加の Isolation Address(1 番目) |
das.isolationaddress2 〜 das.isolationaddress9 | (未設定) | 任意の IP | 最大 10 個(0〜9)まで設定可能 |
das.isolationshutdowntimeout | 300 | 秒単位 | Isolation Response が「シャットダウン」のとき、強制電源オフに切り替わるまでの待ち時間 |
参考: Setting Multiple Isolation Response Addresses for vSphere High Availability – Broadcom Knowledge
“VMware HA supports a maximum of 10 isolation response addresses, in most cases one or two isolation response addresses should be sufficient.”
(VMware HA は最大 10 個の Isolation Address をサポートしますが、ほとんどの環境では 1〜2 個で十分です)
https://knowledge.broadcom.com/external/article/341627/setting-multiple-isolation-response-addr.html
Isolation Address に指定された IP は 並列で ping されます(順次ではない点に注意)。設定後は後述の「クラスタ HA の無効化 → 再有効化」で反映する必要があります。
カテゴリ D: その他の頻出オプション
特定の運用ニーズで利用される代表的なオプションです。
| 設定キー | 既定値 | 用途 |
|---|---|---|
das.maxFtVmsPerHost | 4 | 1 ホストあたりの Fault Tolerance(FT)保護 VM 数の上限を変更 |
das.config.fdm.isolationPolicyDelaySec | 0 | Isolation Response 実行前の追加遅延(秒) |
das.respectVmHostSoftAffinityRules | true | HA フェイルオーバ時に DRS のソフトアフィニティルールを尊重するか |
「無効化 → 再有効化」が必要なオプション
詳細オプションの中でも特に 設定変更後にクラスタ HA の無効化 → 再有効化が必要 なものは以下です。
das.isolationaddress[0〜9]das.usedefaultisolationaddressdas.isolationshutdowntimeoutdas.heartbeatDsPerHost
ホスト個別の [vSphere HA 用に再構成] では反映されないため、設定後の手順には注意が必要です。
vSAN 環境での HA 推奨設定
vSAN 環境では、従来の SAN / NAS 構成とは HA 設計の前提が異なります。デフォルト設定のままでは想定外の挙動につながる可能性があるため、Broadcom がベストプラクティスとして案内している設定を整理します。
vSAN ではハートビートデータストアの考え方が異なる
vSAN 構成のクラスタでは、vSAN データストア自体はハートビートデータストアとして利用できません。vSAN にしかストレージが無い純粋な vSAN 構成では、ハートビートデータストア数が必然的に 0 となり、警告が表示されます。
このため、vSAN 環境では das.ignoreInsufficientHbDatastore = true を設定して警告を抑制するのが一般的な運用です。これは「警告を無視する」のではなく、vSAN がデータストアハートビートに依存しない設計 であることを反映した設定です。
Isolation Address は管理ネットワーク以外を指定する
vSAN クラスタでは、HA のハートビート通信が vSAN ネットワーク経由で行われる という仕様があります。一方で Isolation Address のデフォルトは管理ネットワークのデフォルトゲートウェイです。
以下のような問題が起こりえます。
- 管理ネットワークだけが生きていて vSAN ネットワークが断絶した場合: HA はホストを「孤立していない」と判定するが、実際には vSAN ハートビートは届かず、クラスタの整合性が取れない
- vSAN ネットワークだけが生きていて管理ネットワークが断絶した場合: Isolation Address に到達できず、不要な Isolation Response が発動する可能性
このため、vSAN 環境では Isolation Address を vSAN ネットワーク上のアドレスに変更する のが Broadcom の推奨設定です。
vSAN 環境向けの推奨パラメータ
| 設定キー | 推奨値 | 説明 |
|---|---|---|
das.usedefaultisolationaddress | false | 管理ネットワークのデフォルトゲートウェイを Isolation Address として使わない |
das.isolationaddress0 | vSAN ネットワーク上の到達可能 IP(例: vSAN セグメントの SVI) | vSAN ネットワーク経路の生存を判定するアドレス |
das.ignoreInsufficientHbDatastore | true(vSAN のみのクラスタの場合) | ハートビートデータストア不足警告の抑制 |
参考: Using an Isolation Address to ensure HA functionality in a vSAN environment – Broadcom Knowledge
“It is best practice to set two specific advanced configuration settings in the vSphere HA configuration when there is not already logical or physical segregation between Management network and vSAN network.”
(管理ネットワークと vSAN ネットワークの間に論理的・物理的な分離がない環境では、HA 設定に対して 2 つの特定の詳細オプションを設定することがベストプラクティスです)
https://knowledge.broadcom.com/external/article/313763/using-an-isolation-address-to-ensure-ha.html
vSAN ネットワーク上に到達可能な IP が存在しない場合(vSAN ネットワークが完全に独立した非ルーティング L2 構成など)は、物理スイッチに Switch Virtual Interface(SVI) を作成して vSAN セグメント内の IP を確保する方法が有効です。
Isolation Response(ホスト分離応答)の設計
vSAN 環境では、Isolation Response の設定にも注意が必要です。
| 構成 | 推奨される Isolation Response |
|---|---|
| 通常の vSAN クラスタ | Power off and restart VMs(電源オフして再起動) |
| vSAN 2 ノード ROBO 構成 | Disabled(無効化)/ Isolation Address 設定なし |
vSAN 環境で Shutdown VM ではなく Power off VM が推奨される理由は、ホストが孤立した場合、その VM は他ホストでも稼働できる状態に速やかに移行する必要があるためです。OS のシャットダウン処理を待つよりも、即時電源オフの方がフェイルオーバの安定性が高くなります。
vMotion 連携時の留意点
vSAN クラスタ内のメンテナンスでは、HA と vMotion を組み合わせた運用が一般的です。HA フェイルオーバ動作と、計画メンテナンス時の vMotion による VM 退避は別の機構ですが、両者で共通する CPU 互換性(EVC)やネットワーク要件は事前に整えておく ことが望まれます。vMotion の実行要件については、関連記事『VMware vMotion の 3 種類と実行要件|帯域・CPU 互換性のポイント』で整理しています。
設定反映の正しい手順: クラスタ HA の無効化 → 再有効化
ここが本記事の最重要ポイントです。HA 詳細オプションを追加・変更しただけでは、警告は消えません。設定を反映させるには、クラスタの HA を一度無効化してから再有効化する手順が必要です。
過去の手順では「ホスト右クリック → 『vSphere HA 用に再構成』」が紹介されることが多くありますが、Broadcom 公式 KB(2025 年更新)では クラスタレベルでの HA 無効化 → 再有効化 が公式手順として案内されています。
参考: vSphere HA Advanced Options – Broadcom TechDocs(vSphere 8.0)
“If you change the value of any of the following advanced options, you must deactivate and then re-activate vSphere HA before your changes take effect.”
(以下の Advanced Option を変更する場合、変更を反映させるには vSphere HA を一度無効化してから再有効化する必要があります)
https://techdocs.broadcom.com/us/en/vmware-cis/vsphere/vsphere/8-0/vsphere-availability/creating-and-using-vsphere-ha-clusters/configuring-cluster-settings/set-advanced-options/vsphere-ha-advanced-options.html
vSphere Client(HTML5 版)での操作手順は以下のとおりです。
- vSphere Client にログインし、「ホストおよびクラスタ」ビューを開く
- 対象の クラスタ を選択
- [設定(Configure)] タブをクリック
- 左ペインの [vSphere の可用性(vSphere Availability)] を選択
- 画面右側の [編集(Edit)] ボタンをクリック
- [詳細オプション(Advanced Options)] タブを選択
- [追加(Add)] ボタンをクリックし、以下のパラメータを入力
| 設定キー(Key) | 値(Value) | 目的 |
|---|---|---|
das.ignoreRedundantNetWarning | true | 管理ネットワークの冗長性警告を抑制 |
das.ignoreInsufficientHbDatastore | true | ハートビートデータストア不足警告を抑制 |
- 入力完了後、[OK] をクリックしてウィンドウを閉じる
詳細オプションを追加しただけでは反映されないため、HA を一度無効化します。
- 対象クラスタの [設定] タブ → [vSphere の可用性] → [編集] を再度クリック
- [vSphere HA] のトグルを オフ に切り替え
- [OK] をクリックし、すべてのホストで「HA の構成解除(Unconfigure vSphere HA)」タスクが完了するまで待機
- 再度 [編集] をクリックし、[vSphere HA] のトグルを オン に切り替える
- [OK] をクリックし、すべてのホストで「HA の構成(Configure vSphere HA)」タスクが完了するまで待機
- ホストのステータスが緑色(正常)に戻ることを確認
「HA 用に再構成」では不十分なケース
ホスト個別の [vSphere HA 用に再構成(Reconfigure for vSphere HA)] でも反映されるケースもありますが、特に Isolation Address 系(das.isolationaddress[*]、das.usedefaultisolationaddress、das.isolationshutdowntimeout) のオプションは、クラスタレベルでの HA 無効化 → 再有効化が公式に求められています。確実な反映のためにも、本手順をおすすめします。
運用上の注意点(本番環境でのリスク)
警告抑制系の詳細オプションは便利ですが、警告そのものを消すだけで、根本原因(冗長性の欠如)が解消されるわけではありません。本番環境で利用する際の判断軸を整理します。
警告抑制が運用にもたらす影響
das.ignoreRedundantNetWarning = true を設定すると、管理ネットワークが単一経路でも警告は表示されなくなります。ただし、その単一経路(NIC やケーブル、スイッチ)に障害が発生すると、vSphere HA はホストの状態を正しく判別できず、以下のリスクが残ります。
- 誤フェイルオーバ
-
他ホストとのハートビートが届かなくなり、稼働中の VM が「障害」と誤判定されて他ホストで再起動される可能性
- スプリットブレイン
-
管理ネットワークだけが断絶した状態で補助経路(ハートビートデータストア)も無いと、HA が VM の起動状態を一意に判定できず二重起動の懸念
- 障害検知の遅延
-
補助経路が無いことで、本物のホスト障害発生時にも検知までの判定時間が伸びる場合がある。
das.ignoreInsufficientHbDatastore = true も同様で、補助経路が確保されていない事実は変わらず、ネットワーク障害時の判定精度が低下します。
本番環境での判断基準
本番環境では「警告抑制」ではなく 「警告を発生させない構成にする」 ことが望まれます。具体的な対応として以下の方向が現実的です。
- 管理ネットワークの NIC チーミング化
-
物理 NIC を 2 本以上でチーミング構成にし、可能なら異なる物理スイッチに接続
- 共有データストアの追加
-
iSCSI / NFS / FC のいずれかで 2 つ目以降のデータストアを用意
- vSAN 利用時の専用設定
-
vSAN 環境ではハートビートデータストアの考え方が異なるため、前述の vSAN 環境向けの推奨設定を適用
検証環境やホームラボでは、コストやスペースの制約から警告抑制が現実的な選択になることもあります。重要なのは「警告を抑制した状態で本番運用を続けないこと」です。
なお HA フェイルオーバ後の VM 再起動時には、メモリリソースの逼迫によりバルーニングが発生するケースがあります。HA とリソース管理の組み合わせで発生する事象については、関連記事『VMware メモリバルーニングとは|仕組みと esxtop での確認手順』も参考にしてください。
まとめ
本記事では、VMware vSphere HA で頻発する 2 つの警告と、その抑制手順、および HA 詳細オプションの主要パラメータを整理しました。
- HA は管理ネットワークとハートビートデータストアの 2 経路で生存確認を行い、いずれかの冗長性が不足すると警告が表示される。
- 管理ネットワーク冗長性警告は
das.ignoreRedundantNetWarning = true、ハートビート不足警告はdas.ignoreInsufficientHbDatastore = trueで抑制可能 - ハートビート要求数を調整したい場合は
das.heartbeatDsPerHostを 2〜5 の範囲で設定できる。」 - 詳細オプションの設定変更は「クラスタ HA の無効化 → 再有効化」で反映するのが公式手順(ホスト右クリックの「HA 用に再構成」では不十分なケースがある)
- vSAN 環境では
das.usedefaultisolationaddress = false+das.isolationaddress0(vSAN NW 上の IP)の設定が推奨される。」 - 警告抑制は根本対策ではないため、本番環境では NIC チーミングや共有データストア追加による物理冗長化を優先する。
以上、最後までお読みいただきありがとうございました。

