

はじめに
この記事では、Azure を利用してデータ基盤を構築し、可視化する手順について紹介します。具体的には、Azure Blob Storage に CSV データを格納し、Data Factory を用いて Azure SQL Database に取り込み、Power BI でレポートを作成する流れを解説します。
- Azure を使った データ分析基盤 の基本アーキテクチャ(Blob → ADF → SQL → Power BI)
- Data Factory によるデータコピー手順(GUI 操作で完結)
- CSV データのアップロードから Power BI 可視化までの 一連の流れ
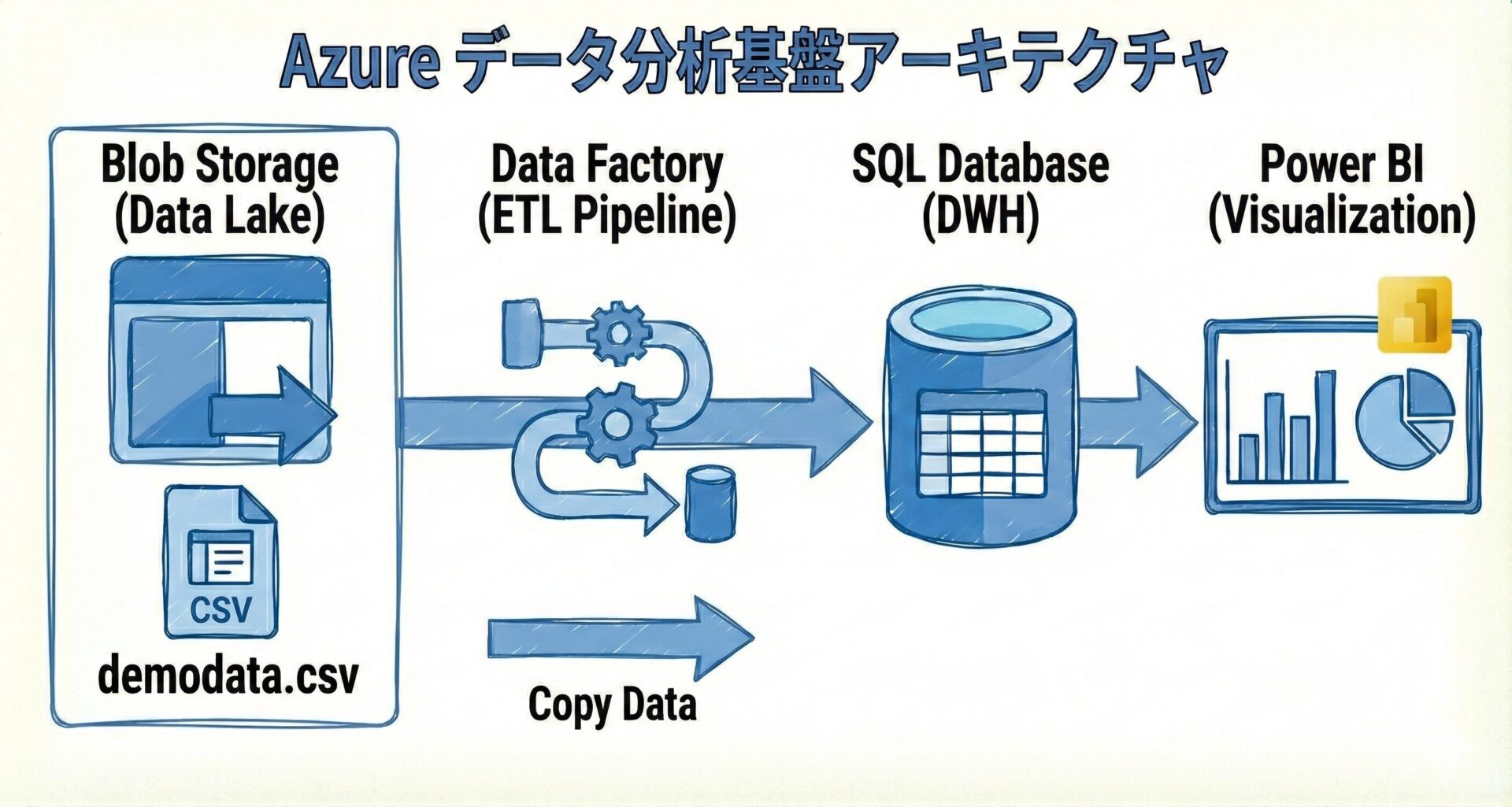
全体アーキテクチャ構成
今回のチュートリアルでは、Azure の主要なデータサービスを組み合わせて、生の CSV データから視覚的なレポートを作成するまでの一連のデータパイプライン(データ分析基盤)を構築します。
今回構築するデータパイプラインの流れ
構成するリソースとその役割は以下の通りです。データの流れ(左から右)に沿って順番に構築していきます。
データレイクの入り口です。今回は分析の元となる CSV ファイルの置き場として機能します。
データの抽出・変換・書き出しを担う ETL パイプラインです。GUI ベースで、Blob からデータベースへのデータコピージョブ(アクティビティ)を作成します。
データの格納先(データウェアハウス:DWH)です。ADF によって運ばれてきたデータを保存し、分析ツールからのクエリに応答します。
データの可視化(BI)ツールです。SQL Database に接続し、データをグラフや表にして直感的なダッシュボードを作成します。
Azure Blob Storage の準備
データの保存先となる「Azure Blob Storage」を利用するには、まず大枠となる「ストレージアカウント」を作成し、その中にデータを格納するフォルダの役割を持つ「コンテナ」を作成する必要があります。
ストレージアカウントとコンテナの作成
Azure Portal の検索窓で「ストレージ アカウント」と検索し、「+ 作成」をクリックします。以下の設定を入力して作成を進めてください。
- リソースグループ:
Test-RG(新規作成) - ストレージアカウント名:
blobdemodata01※世界中で一意である必要があります。 - 地域:
Japan West (西日本)など、任意のリージョン - パフォーマンス:
Standard - 冗長性:
ローカル冗長ストレージ (LRS)※テスト用なので最も安価なもので OK です
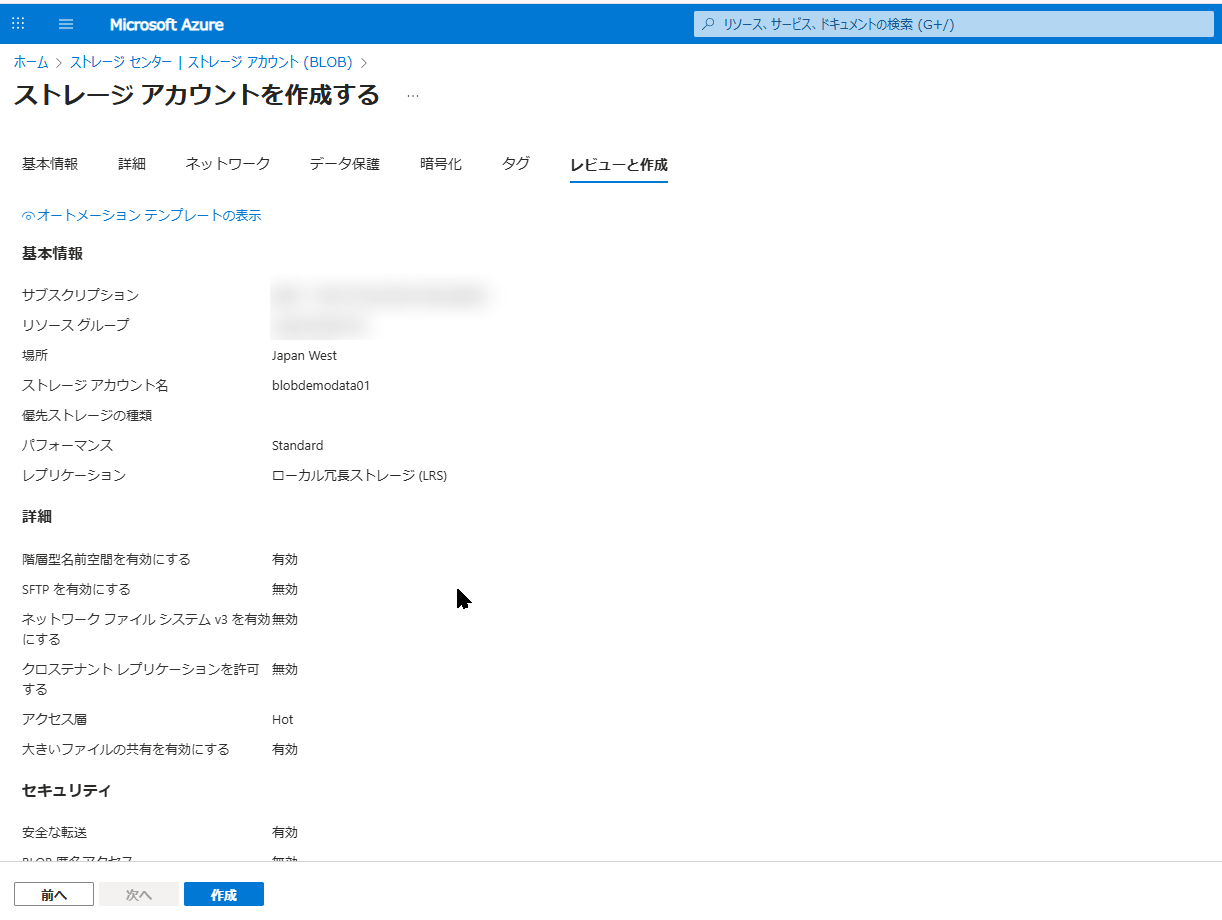
入力が完了したら、「作成」をクリックしてデプロイを完了させます。
デプロイが完了したら「リソースに移動」をクリックし、作成したストレージアカウントの管理画面を開きます。
- 左側のメニューから 「データ ストレージ」 > 「コンテナー」 を選択します。
- 画面上の 「+ コンテナー」 をクリックします。
- 名前を
raw(未加工データを入れるという意味合い)として、「作成」をクリックします。
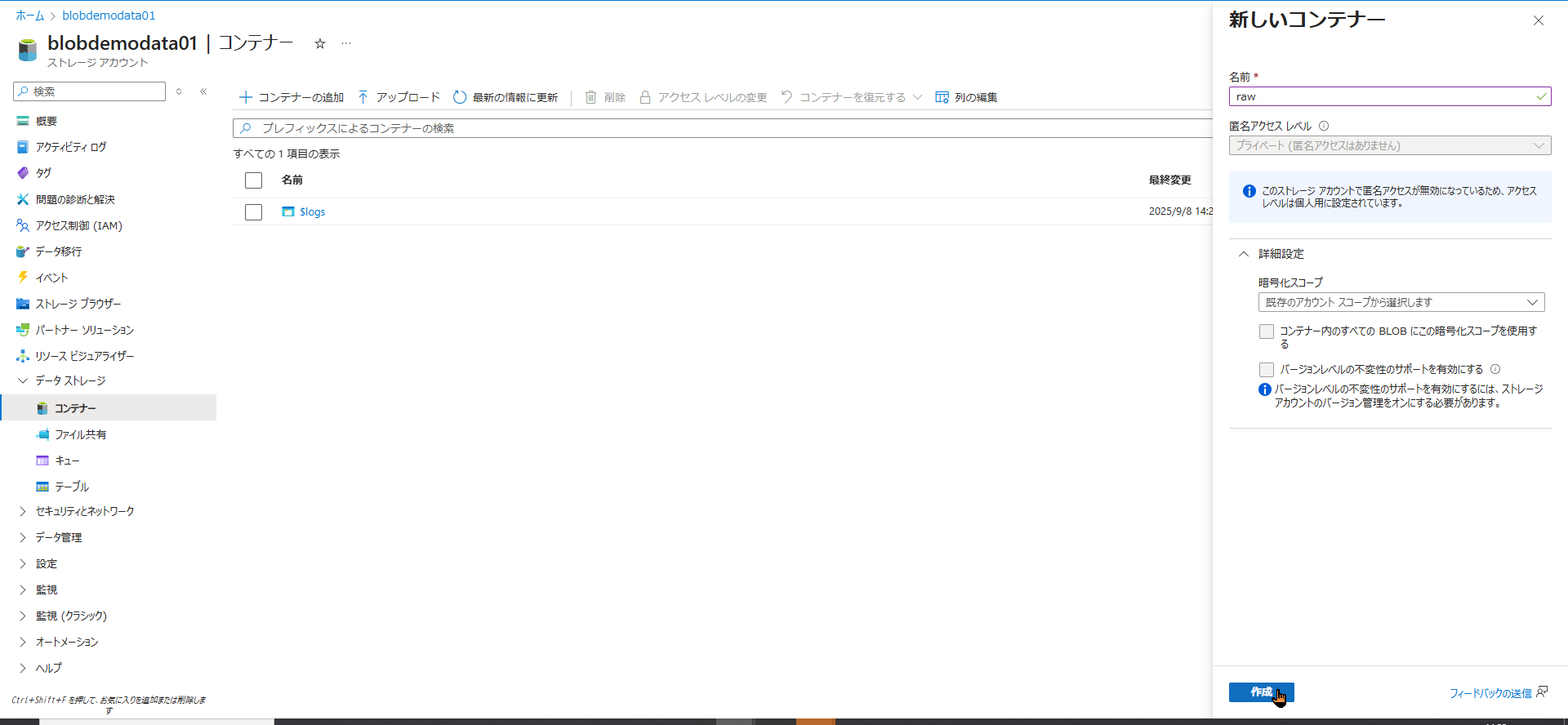
これでデータの受け皿が完成しました。
サンプルデータ(CSV)のアップロード手順
続いて、作成した raw コンテナに分析対象となるサンプルデータ(CSV ファイル)をアップロードします。今回は卓球の試合データ(demodata.csv)を使用します。
- 先ほど作成した
rawコンテナをクリックして開きます。 - 画面上部の 「↑ アップロード」 をクリックします。
- 右側にアップロード用のパネルが表示されるので、PC 内の
demodata.csvを選択します。 - 「アップロード」 ボタンをクリックします。
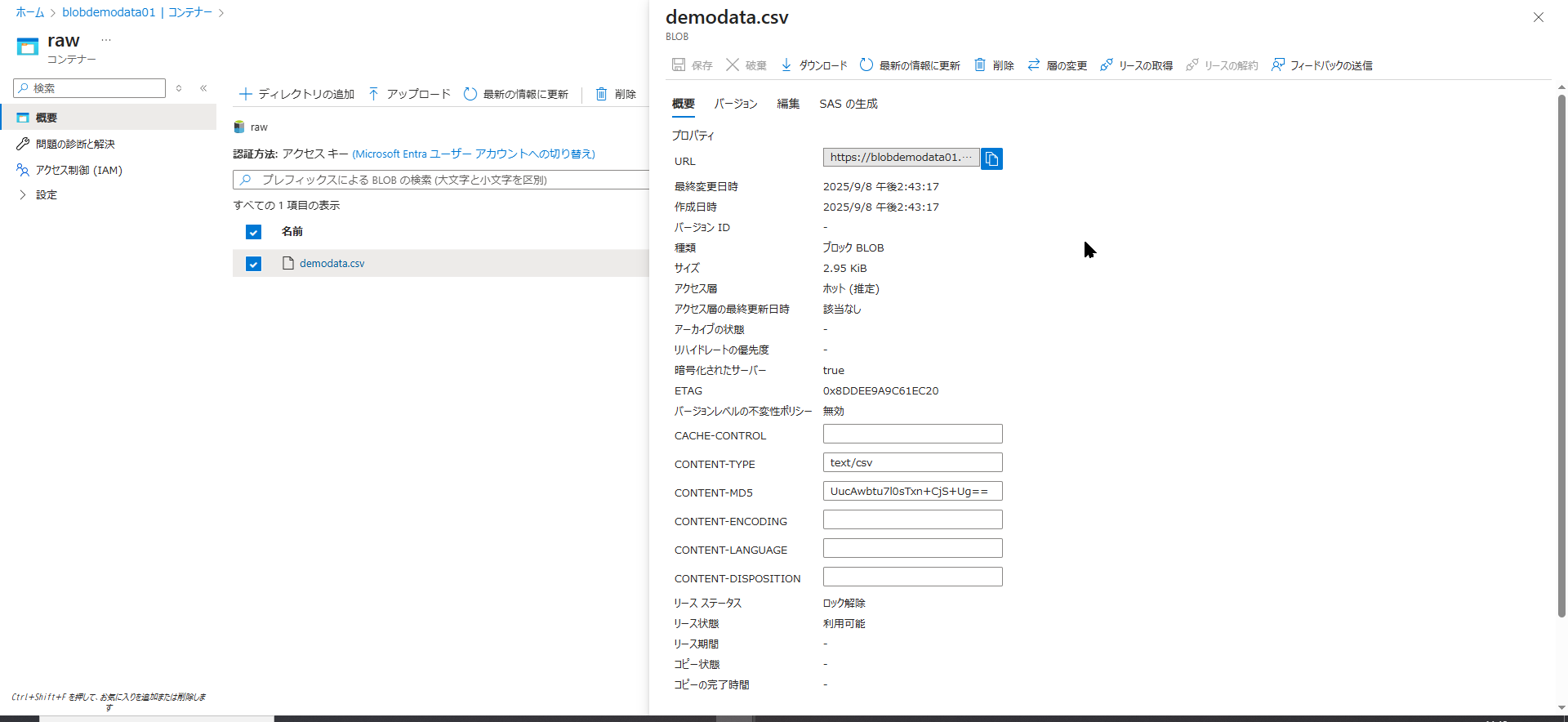
アップロードが完了し、コンテナ内の一覧にファイル名、サイズ、最終更新日時が正しく表示されていれば、STEP1 は完了です。
参考: demodata.csv
Rally,Server,Winner,ServeType,Outcome,Axis,SpinClass,Length,Course,Contact,Set,match_id,created_at,player,opponent
1,HANAKO,HANAKO,Reverse sidespin serve,Service ace,reverse-side,non-backspin,half-long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
2,HANAKO,HANAKO,Reverse sidespin serve,Service ace,reverse-side,non-backspin,half-long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
3,TARO,TARO,Vertical-spin serve,Receive error (self),vertical,non-backspin,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
4,TARO,TARO,Vertical-spin serve,Third-ball point (opponent),vertical,non-backspin,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
5,HANAKO,TARO,Reverse sidespin serve,Rally lost,reverse-side,non-backspin,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
6,HANAKO,HANAKO,Reverse sidespin serve,Rally won,reverse-side,non-backspin,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
7,TARO,HANAKO,Vertical-spin serve,Rally won,vertical,backspin-type,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
8,TARO,TARO,Vertical-spin serve,Rally lost,vertical,backspin-type,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
9,HANAKO,HANAKO,Reverse sidespin serve,Service ace,reverse-side,non-backspin,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
10,HANAKO,HANAKO,Reverse sidespin serve,Third-ball point (self),reverse-side,non-backspin,half-long,backhand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
11,TARO,TARO,Vertical-spin serve,Third-ball point (opponent),vertical,backspin-type,long,backhand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
12,TARO,TARO,Vertical-spin serve,Receive error (self),vertical,non-backspin,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
13,HANAKO,HANAKO,Reverse sidespin serve,Service ace,reverse-side,non-backspin,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
14,HANAKO,HANAKO,Vertical-spin serve,Rally won,vertical,non-backspin,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
15,TARO,TARO,Vertical-spin serve,Rally lost,vertical,non-backspin,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
16,TARO,TARO,Vertical-spin serve,Receive error (self),vertical,backspin-type,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
17,HANAKO,HANAKO,Reverse sidespin serve,Service ace,reverse-side,non-backspin,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
18,HANAKO,HANAKO,Reverse sidespin serve,Service ace,reverse-side,backspin-type,long,forehand,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
19,TARO,TARO,Vertical-spin serve,Receive error (self),vertical,backspin-type,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
20,TARO,TARO,Vertical-spin serve,Rally lost,vertical,non-backspin,long,middle,,1,3d0f0836,2025-09-02T19:28:52+09:00,HANAKO,TARO
Azure SQL Database の構築と設定
データレイク(Blob Storage)の準備ができたら、次はデータを流し込むための器となるデータウェアハウス(DWH)、Azure SQL Database を作成します。
DB 作成前の「SQL サーバー」作成手順と設定項目
Azure では、SQL Database(データベース本体)を作成する前に、それを動かすための土台となる「論理 SQL サーバー」を用意する必要があります。データベース作成のウィザード内で一緒に作成します。
- Azure Portal の検索窓で「SQL データベース」と検索し、「+ 作成」をクリックします。
- 「基本」タブで以下のように入力します。
- リソースグループ:
Test-RG(先ほどと同じものを選択) - データベース名:
sqldemo
- リソースグループ:
- ここで 「サーバー」 の項目の下にある 「新規作成」 をクリックします。すると、サーバー作成用のパネルが表示されます。
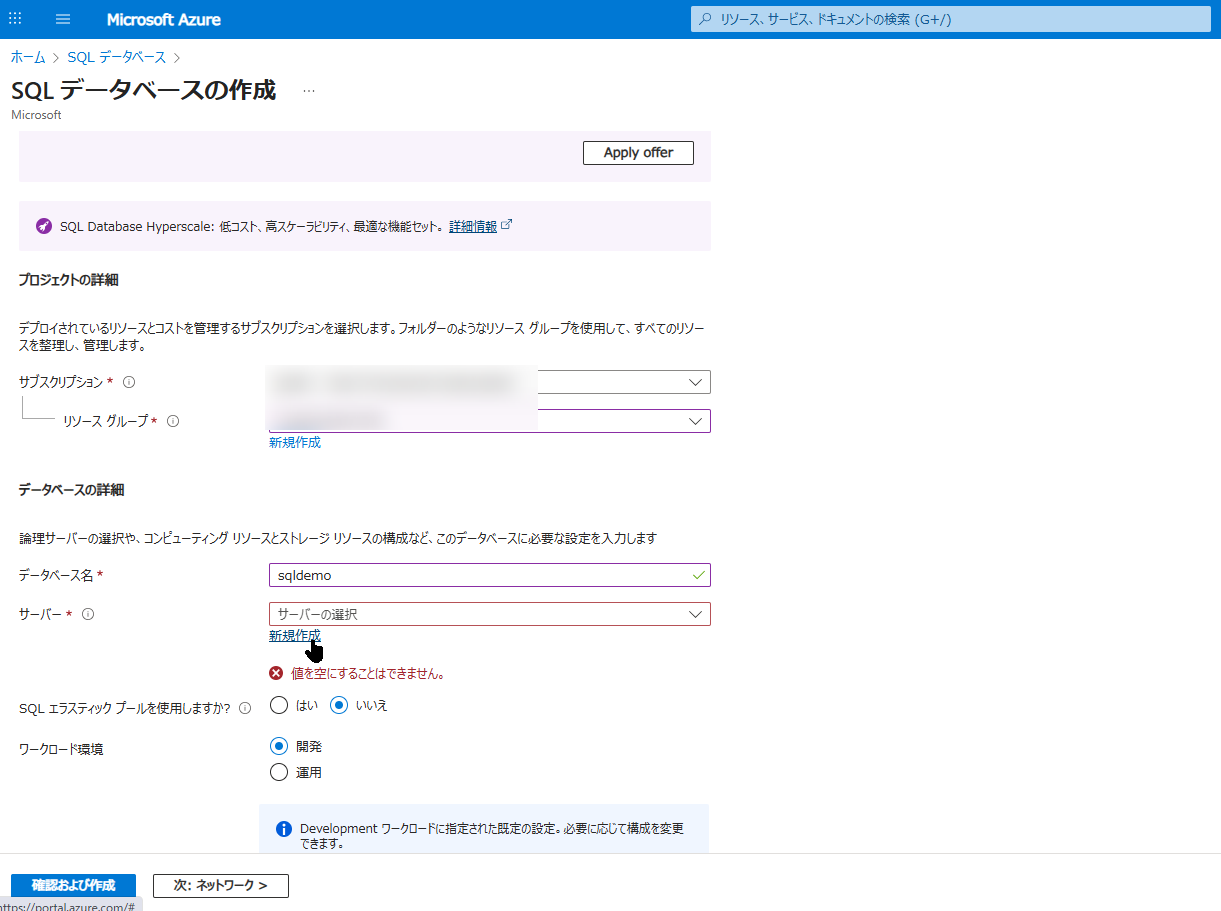
SQL 認証(管理者アカウント)の設定とは?
右側に開いた「新しいサーバー」の作成パネルで、最も重要なのが「認証」の設定です。 これは、後ほど Data Factory からデータを書き込んだり、Power BI や自分のパソコンからこのデータベースに接続したりするための「マスターキー(ID とパスワード)」になります。絶対に忘れないようにメモしておいてください。
以下の項目を入力して「OK」をクリックします。
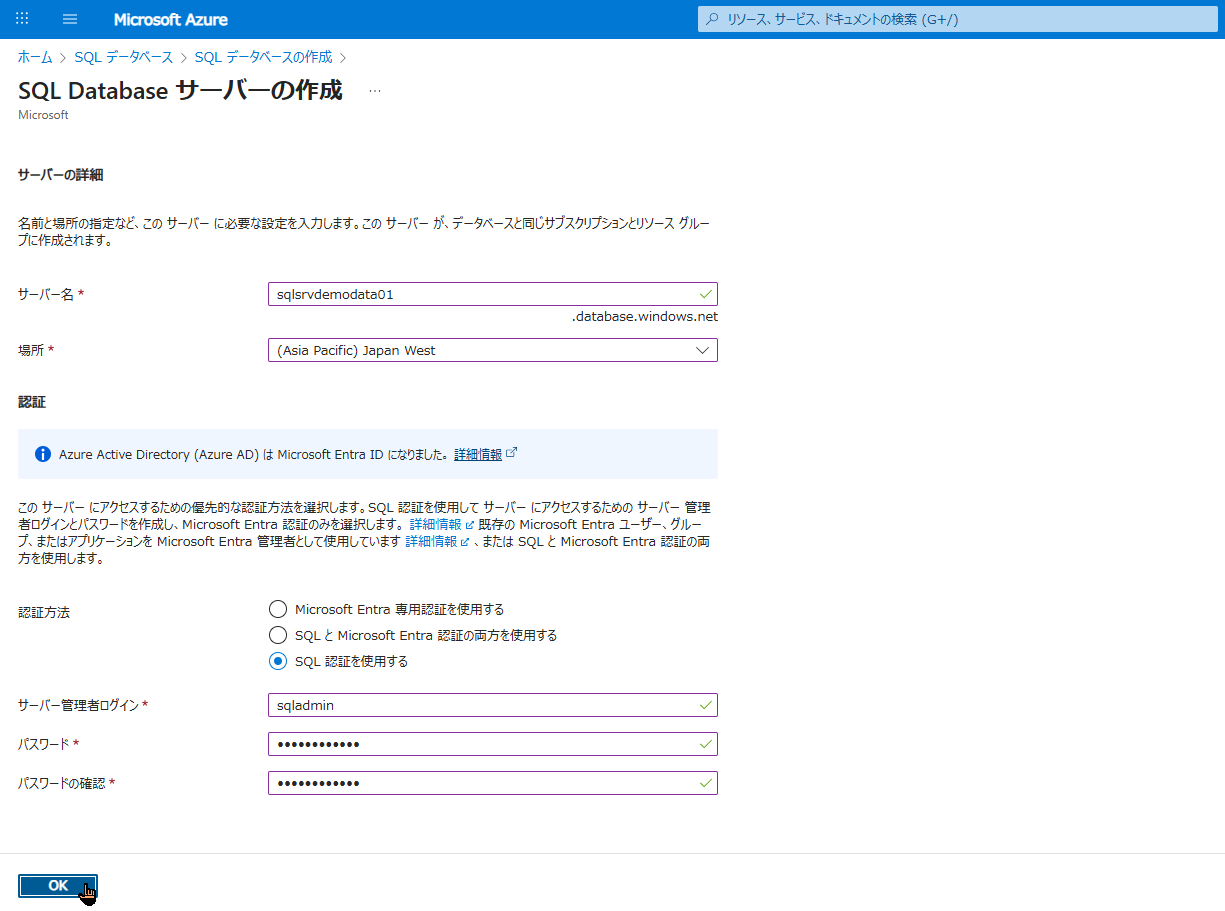
- サーバー名:
sqlsrvdemodata01※世界中で一意である必要があります。 - 場所:
Japan Wast(西日本) - 認証方法: 「SQL 認証を使用する」 を選択します。
- サーバー管理者ログイン:
sqladmin(任意のユーザー名) - パスワード: (大文字・小文字・数字・記号を含む複雑なパスワードを設定)
サーバーが設定できたら、元の画面に戻ります。「コンピューティングとストレージ」は検証用であれば「Basic」など安価なプランに変更し、「確認および作成」をクリックしてデプロイを完了させてください。
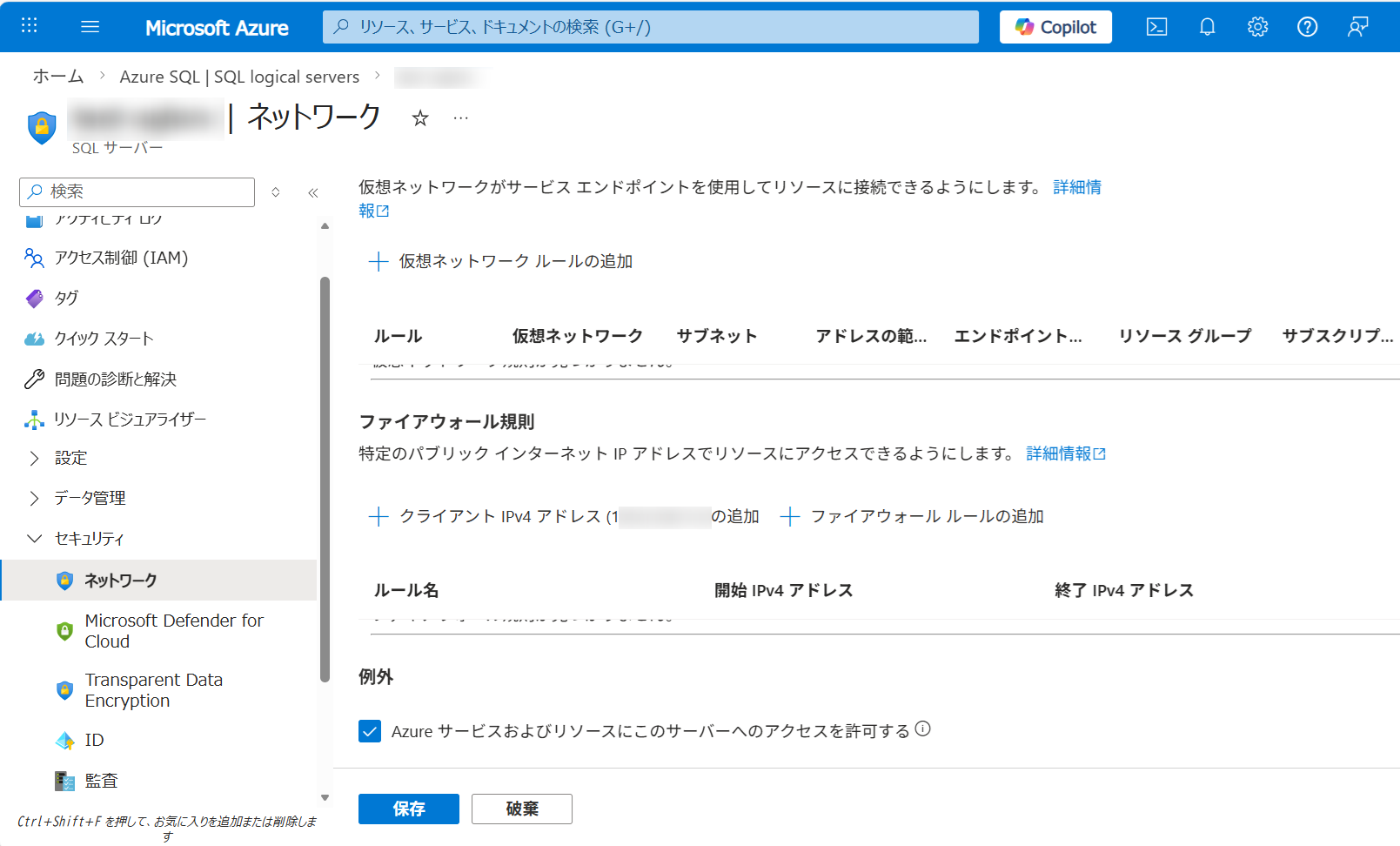
「ファイアウォール規則」設定(Azure サービスへのアクセス許可)
この設定を忘れると、後で Data Factory からデータを流し込もうとした時に「接続拒否エラー」になってしまうため、必ず実施してください。
- デプロイ完了後、「リソースに移動」をクリックして、作成した SQL Database (
sqldemo) の管理画面を開きます。 - 左側のメニューから 「セキュリティ」 > 「ネットワーク」 をクリックします。
- 「パブリック ネットワーク アクセス」タブで、以下の2つの設定を行います。
- 「選択されたネットワーク」にチェックを入れる。
- 画面を下へスクロールし、「例外」の中にある「Azure サービスおよびリソースにこのサーバーへのアクセスを許可する」のチェックボックスをオンにする。

これで Data Factory からアクセスできるようになります。
- さらに、「クライアントの IPv4 アドレスを追加する」をクリックします。
- 最後に、画面左上の 「保存」 をクリックします。
これで、SQL Database を受け皿として使うための準備が整いました。
SQL Database でのテーブル作成(クエリ実行)
空のデータベース(sqldemo)が完成したので、次は CSV データを受け入れるための「テーブル(表の枠組み)」を作成します。 Azure Portal には、ブラウザ上から直接データベースを操作できる「クエリエディター」という便利な機能が用意されています。
クエリエディターへのアクセス方法と SQL 認証でのログイン手順
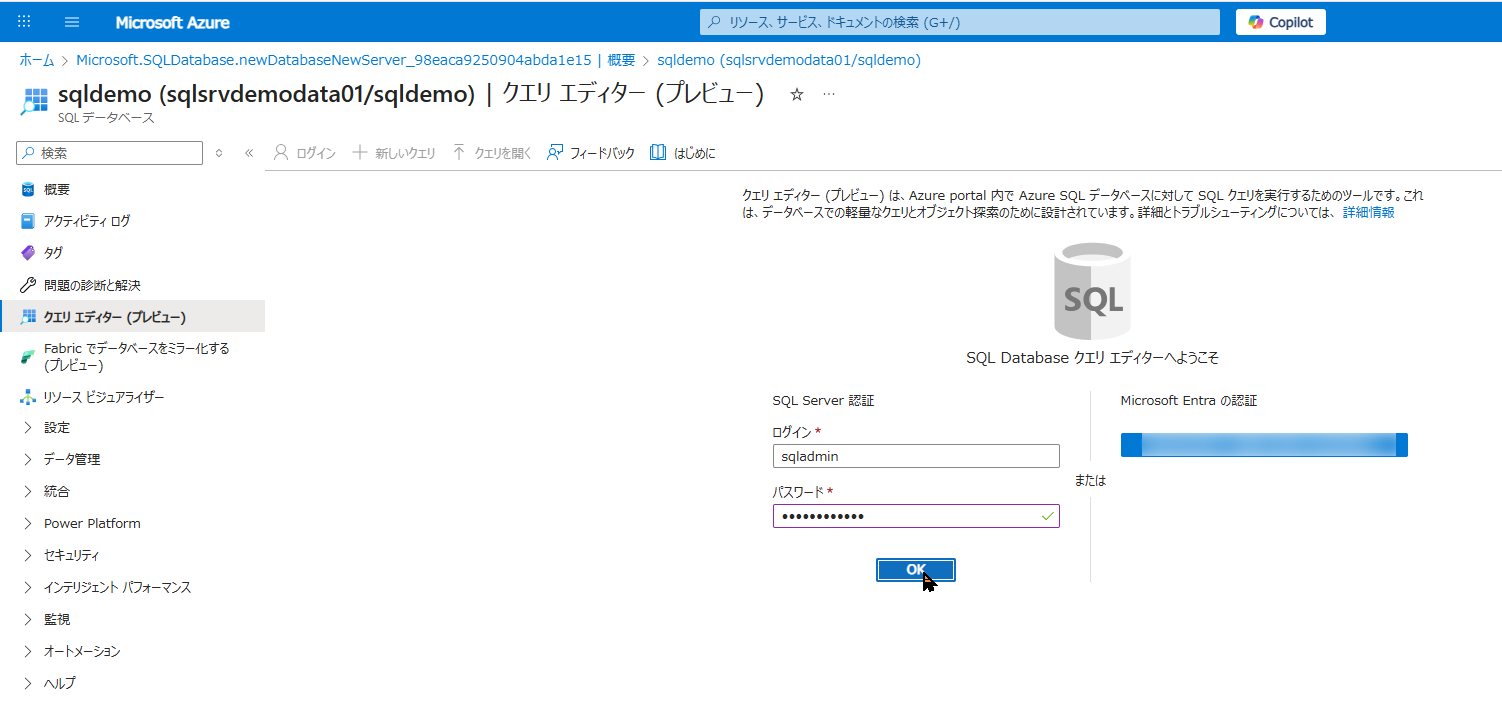
まずは、作成したデータベースにログインして、SQL 文(クエリ)を入力する画面を開きましょう。
- Azure Portal の検索窓、またはリソース一覧から、先ほど作成した SQL Database(
sqldemo)の管理画面を開きます。 - 左側のメニューの中段あたりにある 「クエリ エディター (プレビュー)」 をクリックします。
- すると、データベースに接続するためのログイン画面が表示されます。 ここで、STEP2 で設定した「SQL 認証」の情報を使用します。
- 認証の種類: 「SQL Server 認証」が選択されていることを確認します。
- ログイン:
sqladmin(STEP2 で設定した管理者ユーザー名) - パスワード: (STEP2 で設定したパスワード)
- 入力できたら 「OK」 をクリックします。
もしここで「Client IP is not allowed…」のようなエラーが出た場合は、STEP2の「ファイアウォール規則」で「クライアントの IPv4 アドレスを追加する」の設定が保存されていない可能性があります。もう一度ネットワーク設定を見直してみてください。
テーブル作成用のクエリ(CREATE TABLE)の実行
無事にログインできると、右側にクエリを入力できる真っ白なエディター画面が開きます。 ここに、今回の卓球のサンプルデータ(CSV)の列(カラム)に合わせたテーブルを作成するためのSQL文を貼り付けます。
- 以下の SQL 文をコピーして、エディター画面に貼り付けてください。
CREATE TABLE TableTennisDemo (
Rally INT,
Server NVARCHAR(50),
Winner NVARCHAR(50),
ServeType NVARCHAR(100),
Outcome NVARCHAR(100),
Axis NVARCHAR(50),
SpinClass NVARCHAR(50),
Length NVARCHAR(50),
Course NVARCHAR(50),
Contact NVARCHAR(50) NULL,
SetNumber INT,
match_id NVARCHAR(50),
created_at DATETIME2,
player NVARCHAR(50),
opponent NVARCHAR(50)
);
- 貼り付けたら、画面左上の 「▶ 実行」 ボタンをクリックします。
- 画面下部のメッセージ欄に 「クエリが正常に実行されました」 と表示されれば成功です。
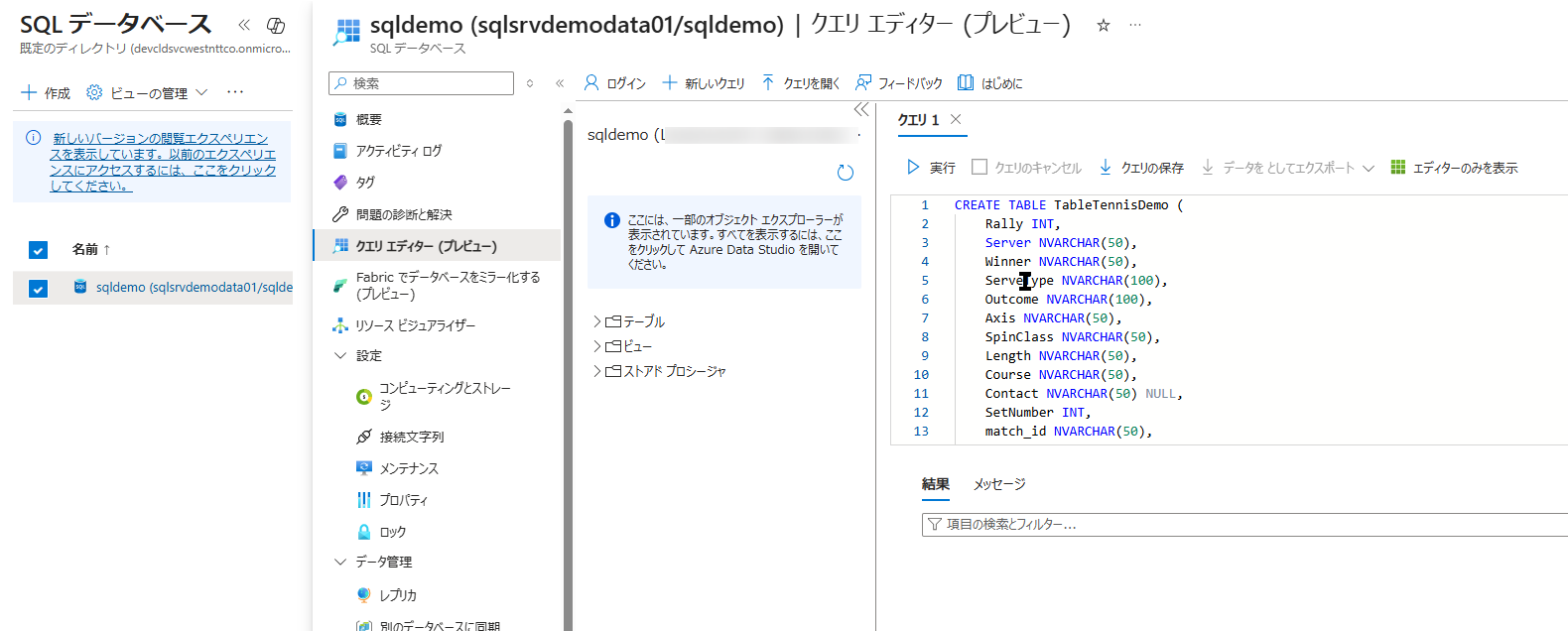
これで、Blob Storage から流し込まれてくるデータを受け止める「TableTennisDemo」という空のテーブルがデータベース内に用意できました。
Azure Data Factory でパイプライン構築
データの「出発地点(Blob)」と「到着地点(SQL DB)」の準備が整いました。ここからは、Azure Data Factory(ADF)を使って、その2つの地点を繋ぐ「データの通り道(パイプライン)」を作っていきます。
Azure Data Factory Studio へのアクセス手順(開き方)
ADF でデータ連携の設定を行うには、Azure Portal とは別の専用画面である「Data Factory Studio」を開く必要があります。
- Azure Portal の検索窓で「データ ファクトリ(Data factories)」と検索し、「+ 作成」をクリックします。
- リソースグループ(
Test-RG)を選択し、任意の名前(例:adf-demo-01)と地域を指定して「確認および作成」でリソースを作成します。 - デプロイが完了したら「リソースに移動」をクリックします。
- 画面の中央にある 「スタジオの起動(Launch studio)」 という大きなボタンをクリックします。
- 新しいブラウザタブが開き、Azure Data Factory Studio の専用画面が表示されます。

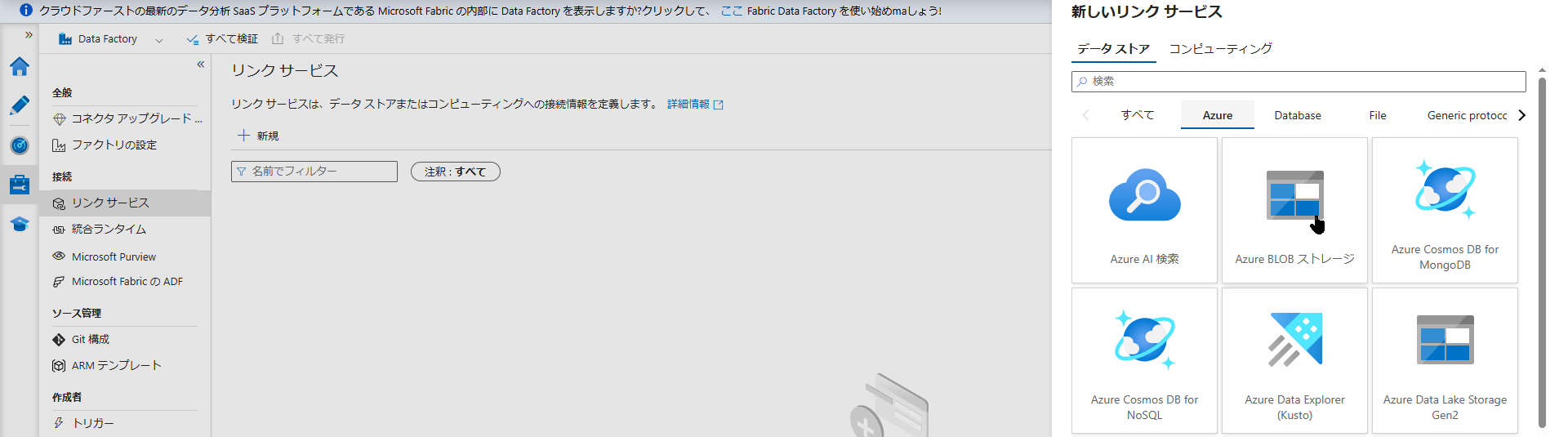
Linked Service(リンクサービス)の作成(Blob 用・SQL DB 用)
ADF Studio が開いたら、まずは ADF に Blob Storage と SQL Database への「アクセス権限(接続情報)」を教える必要があります。これを Linked Service(リンクサービス) と呼びます。
画面左端のツールバーから 「管理(カバン型のアイコン)」 を選択し、「リンク サービス」>「+ 新規」をクリックして、以下の2つを作成します。
- データストア:
Azure Blob Storageを選択 - 名前:
ls_blobdemodata - ストレージ アカウント名: STEP1 で作成した
blobdemodata01を選択 - 「接続のテスト」 をクリックして「成功」と出たら「作成」を押します。
- データストア:
Azure SQL Databaseを選択 - 名前:
ls_sqldemodata - サーバー名 / データベース名: STEP2 で作成したものを選択
- 認証の種類:
SQL 認証を選択 - ユーザー名 / パスワード:
sqladminと STEP2 で設定したパスワードを入力 - 同様に「接続のテスト」が成功したら「作成」を押します。
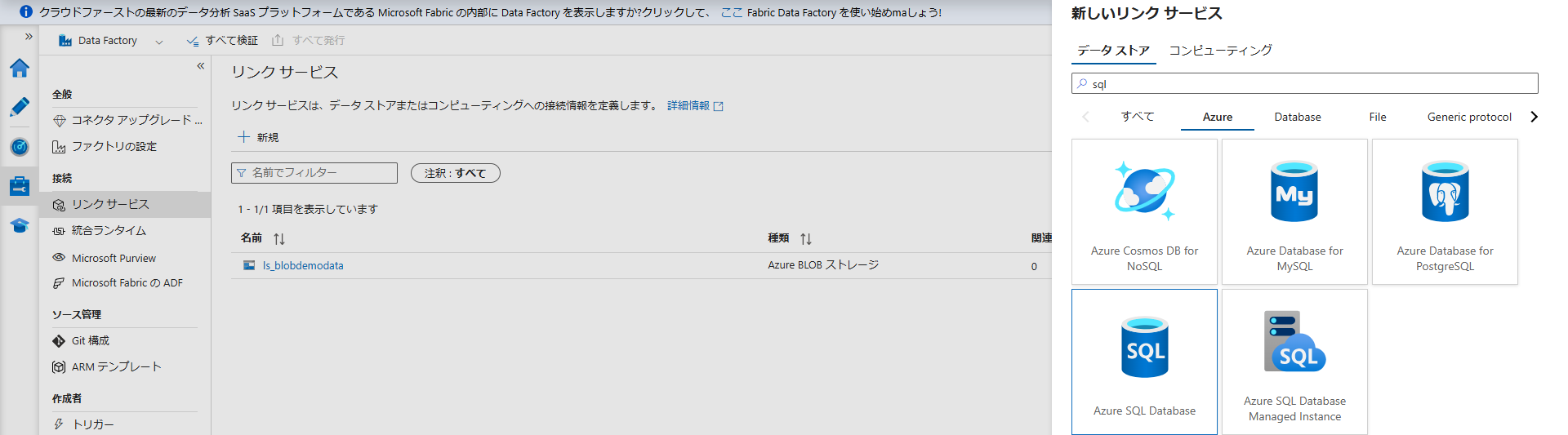
Copy Data アクティビティの設定と列マッピング
接続情報が設定できたら、いよいよ「A から B へデータをコピーする」という具体的な指示(アクティビティ)を作成します。
- 左端のツールバーから 「作成(鉛筆型のアイコン)」 を選択します。
- 「パイプライン」の「+」ボタンをクリックし、「パイプライン」を新規作成します。
- 画面左側の「アクティビティ」一覧から、「移動と変換」の中にある 「データのコピー(Copy data)」 を、右側の広いキャンバスにドラッグ&ドロップします。
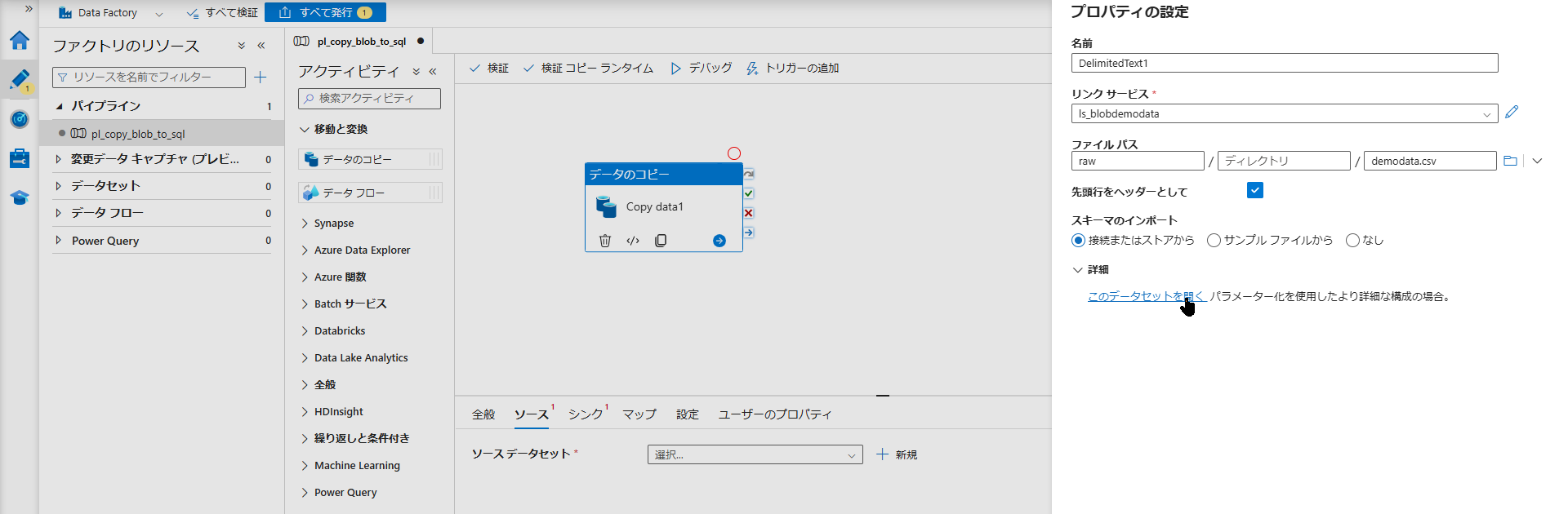
- 画面下部の設定パネルから「ソース」タブを開き、「+ 新規」をクリックします。
Azure Blob Storage>CSV (区切りテキスト)を選択します。- リンクサービスに
ls_blobdemodataを選び、ファイルパスでrawコンテナの中のdemodata.csvを指定して「OK」を押します。
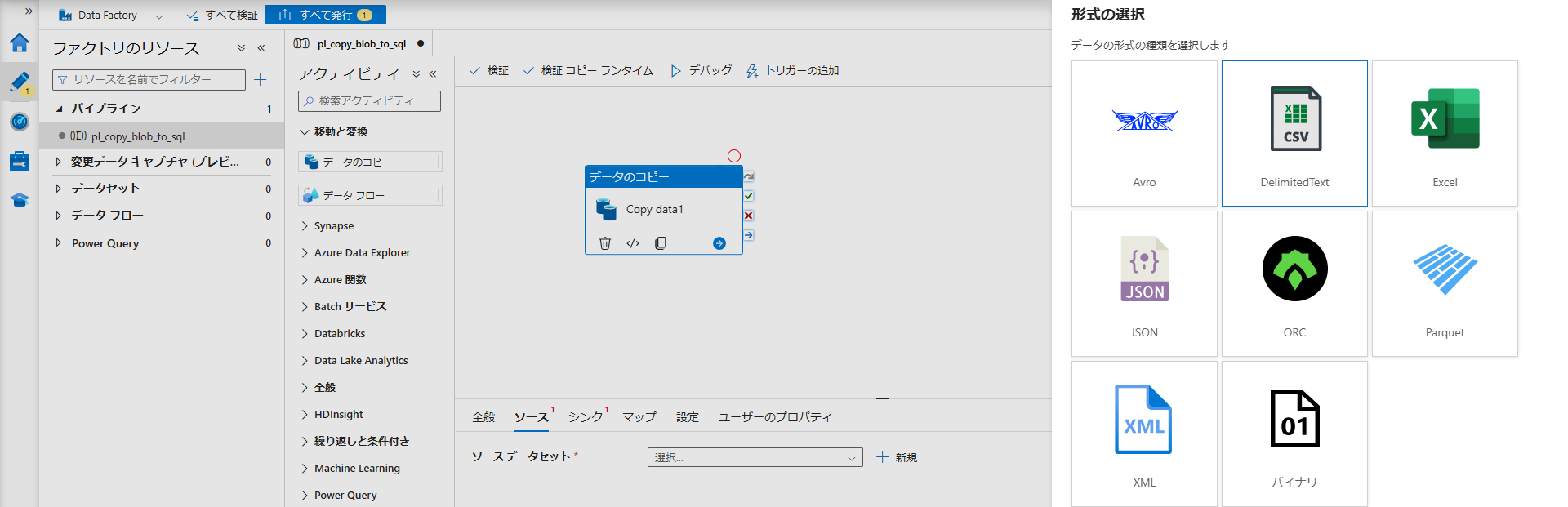
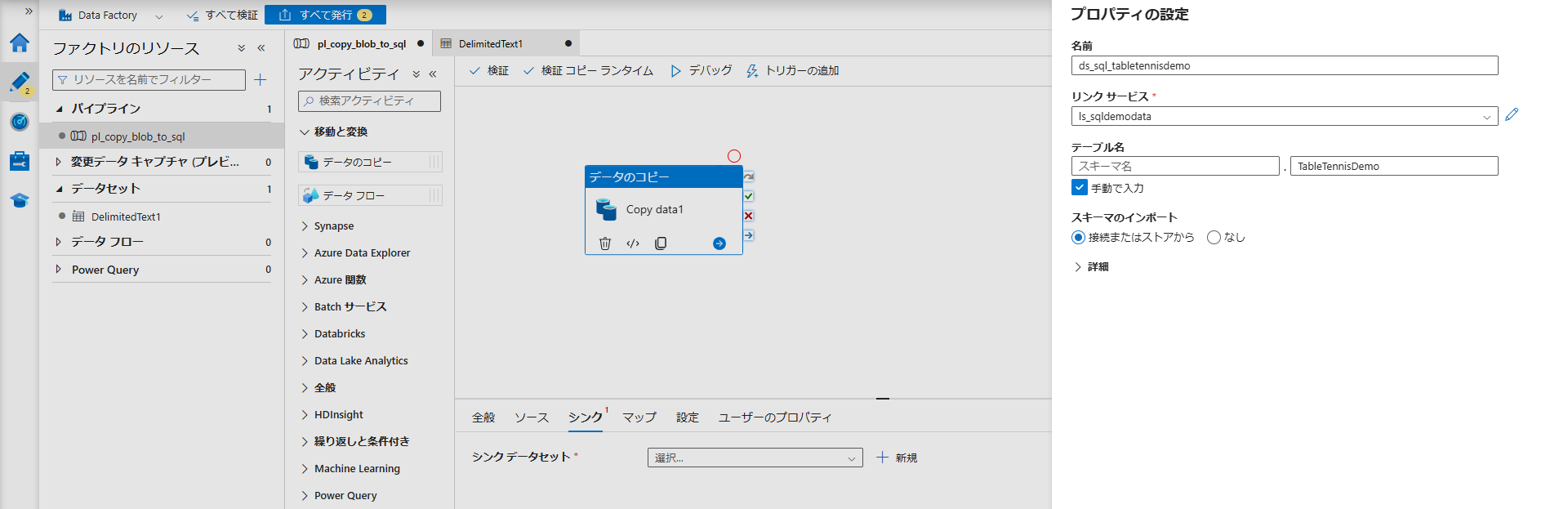
- 続いて「シンク」タブを開き、「+ 新規」をクリックします。
Azure SQL Databaseを選択します。- リンクサービスに
ls_sqldemodataを選び、テーブル名で STEP3 で作成したdbo.TableTennisDemoを指定して「OK」を押します。
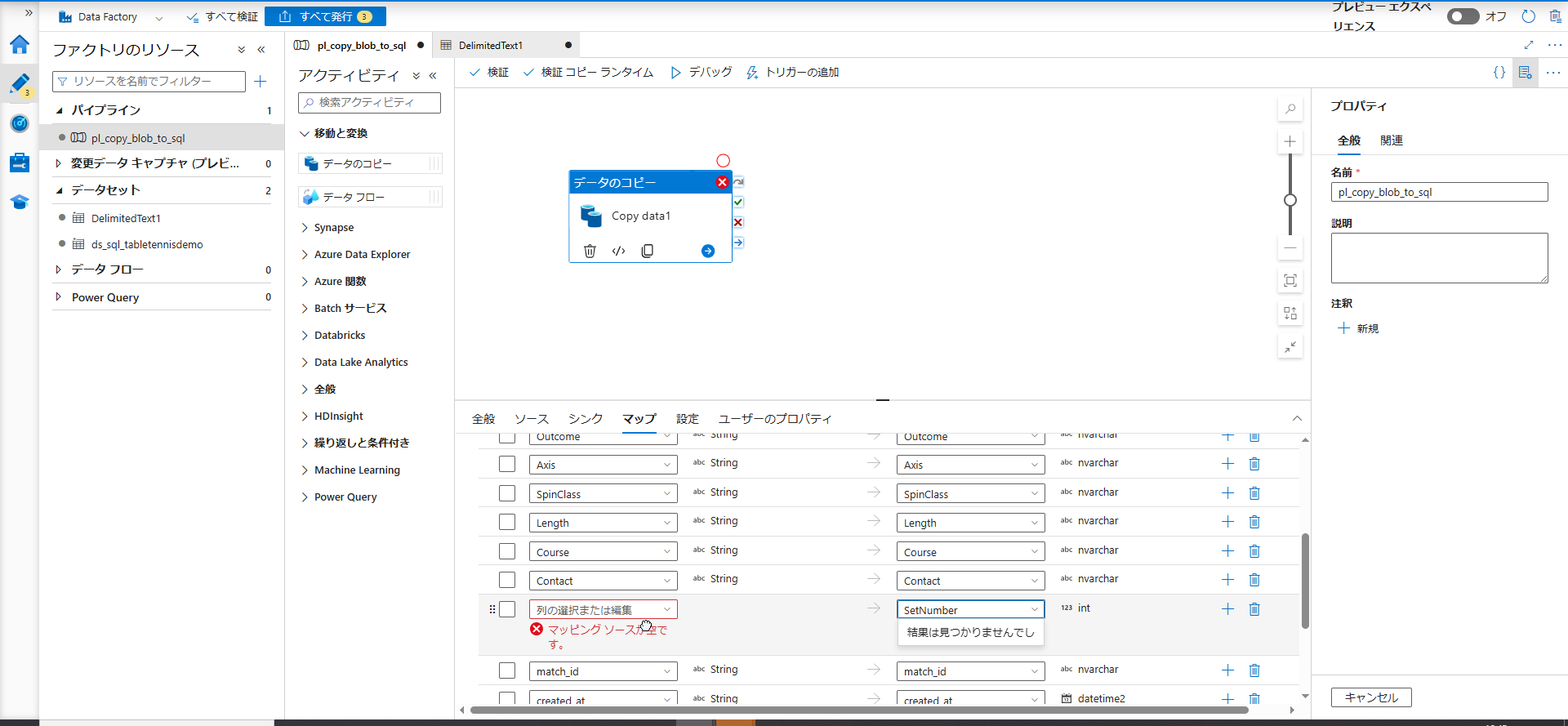
CSV の列名と SQL Database の列名(カラム名)を正しく紐付けます。
- 「マッピング」タブを開き、「スキーマのインポート」 をクリックします。
- 基本的には自動で同じ名前の列が紐づきますが、異なる名前がある場合(例: CSV 側が
Setで DB側がSetNumberの場合など)は、ここで手動でプルダウンから正しい列名を選択して調整します。
デバッグ実行によるデータコピー
設定がすべて完了したら、実際にデータを流し込んでみましょう。
- キャンバスの上部にある 「デバッグ」 ボタンをクリックします。
- 画面下部の「出力」タブに実行状況が表示されます。
- ステータスが「実行中」から 「成功(Succeeded)」 に変われば、Blob から SQL Database へのデータコピーは無事完了です。
データ格納の確認と Power BI での可視化
ADF のパイプライン実行が「成功」したら、最後にデータの到着確認と、BI ツールを使った可視化を行います。
SQL DB でのデータ格納確認コマンド(SELECT クエリの実行)
「本当にデータがコピーされたの?」と不安な場合は、Azure Portal から直接データベースの中身を覗いてみましょう。
- Azure Portal で、作成した SQL Database(
sqldemo)の管理画面を開きます。 - STEP3 と同じように、左側メニューの 「クエリ エディター (プレビュー)」 を開き、
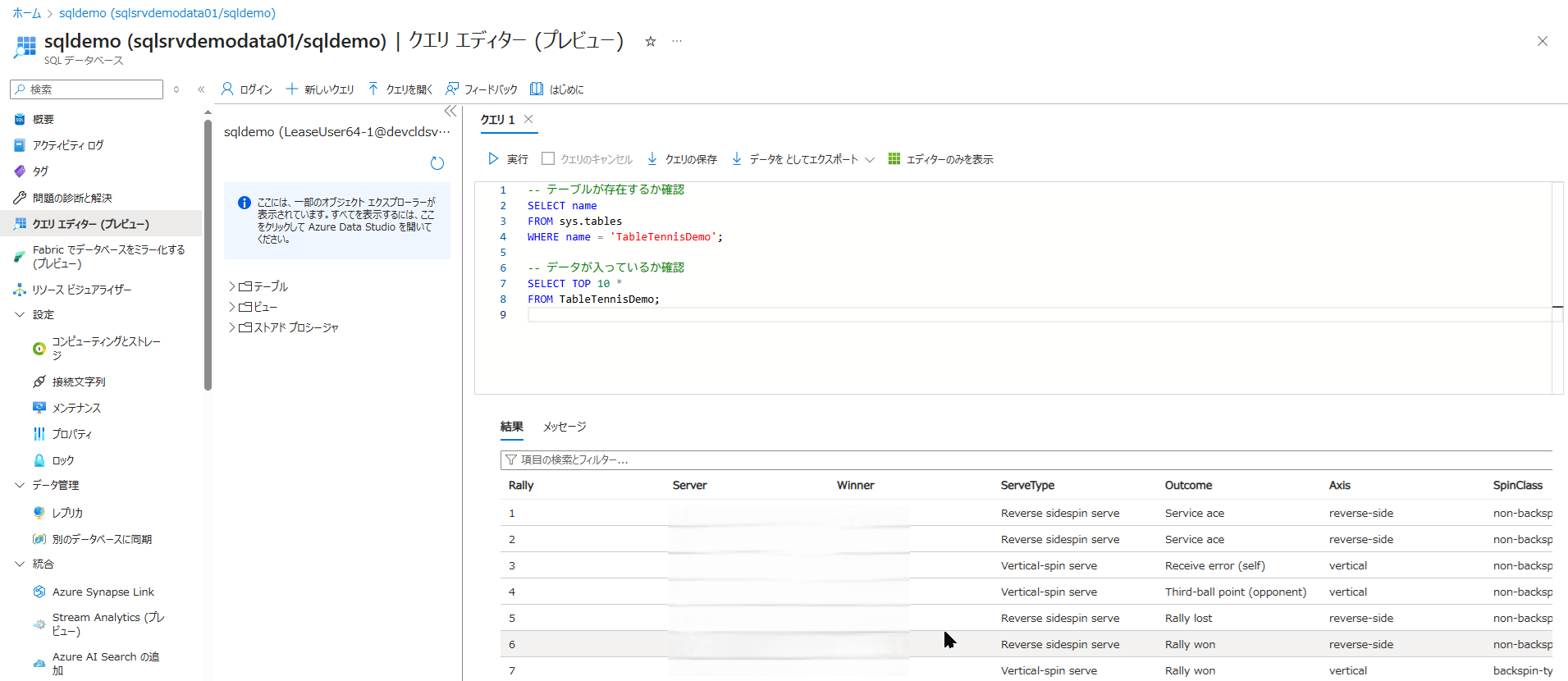
sqladminとパスワードでログインします。 - エディター画面が開いたら、以下の確認用コマンド(SELECT クエリ)を貼り付けます。
-- テーブルの中身を最初の10件だけ表示して確認するコマンド
SELECT TOP 10 * FROM TableTennisDemo;- 左上の 「▶ 実行」 をクリックします。
- 画面下部の「結果」タブに、CSV にあった卓球のデータが表形式でズラリと表示されれば、成功です。
Power BI Desktop から Azure SQL Database への接続手順
データが DWH(SQL Database)に無事格納されたので、いよいよ PC にある Power BI Desktop からこのデータベースに接続します。
- Power BI Desktop を起動し、ホーム画面の 「データの取得」 をクリックします。
- 検索窓で「Azure」と検索し、「Azure SQL データベース」 を選択して「接続」をクリックします。
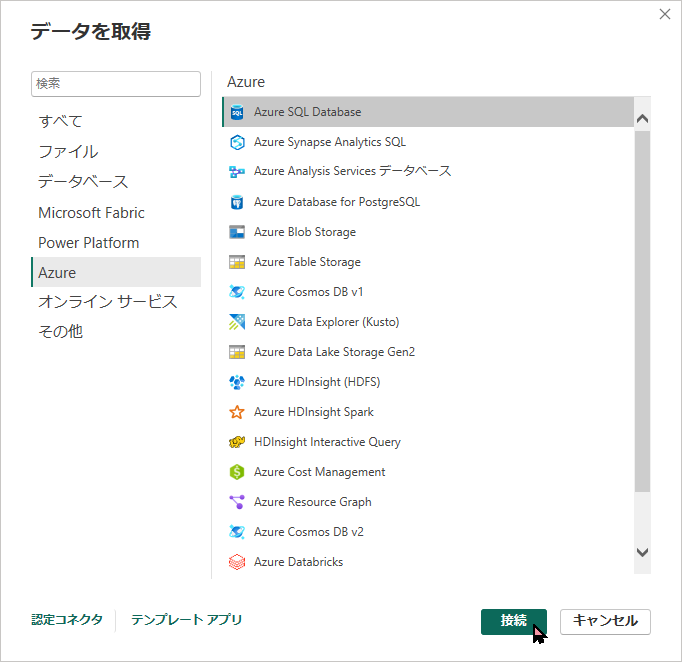
- 接続情報の入力画面が出たら、以下を入力して「OK」をクリックします。
- サーバー:
sqlsrvdemodata01.database.windows.net - データベース:
sqldemo
- サーバー:
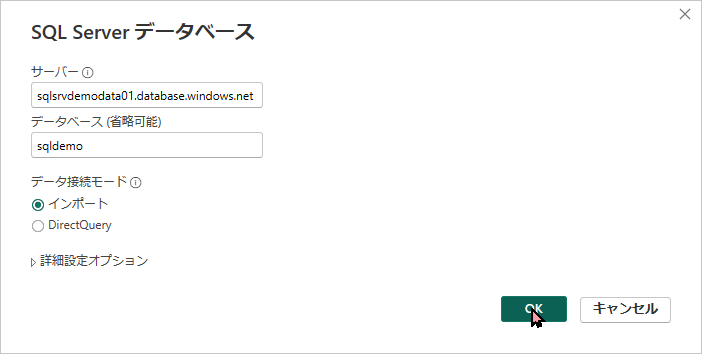
sqlsrvdemodata01.database.windows.netDB 名:
sqldemoサーバー名: sqlsrvdemodata01.database.windows.netは STEP2 で作成したサーバー名の後ろに .database.windows.net を付けたものです。Azure ポータルの SQL データベースの概要画面からコピーできます。
- 次の画面で「どの方法でログインするか」を聞かれます。ここで左側のタブから必ず 「データベース」(環境によっては「SQL Server」)を選択してください。
- ユーザー名:
sqladmin - パスワード: (STEP2 で設定したパスワード) を入力し、「接続」をクリックします。
- ユーザー名:
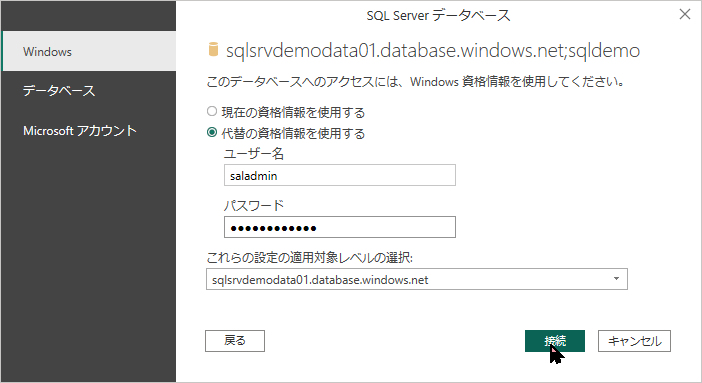
sqladmin)- ナビゲーター画面が表示されたら、
TableTennisDemoのチェックボックスをオンにして、右下の 「読み込み」 をクリックします。
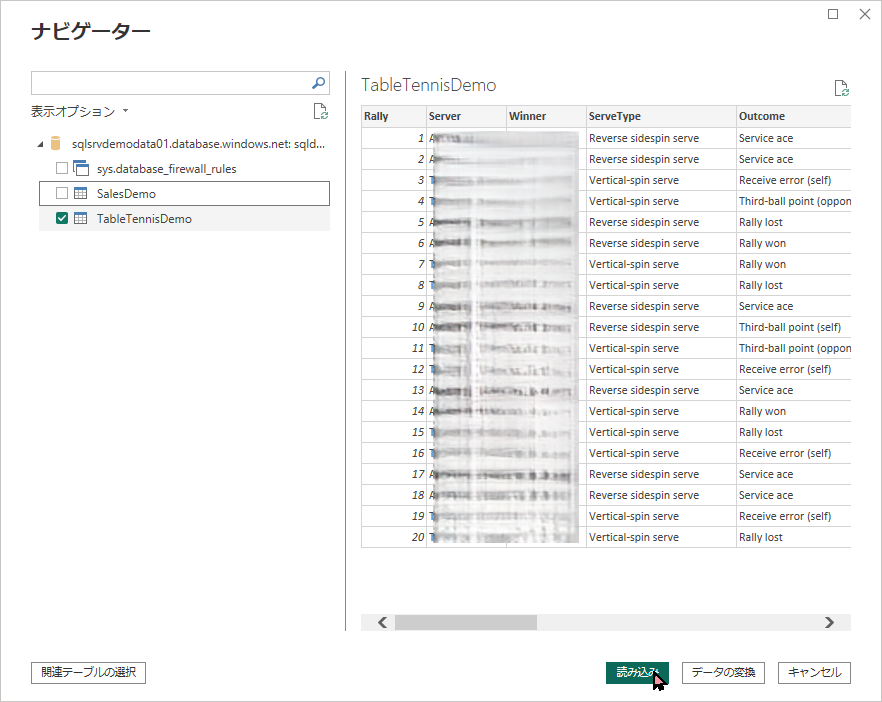
TableTennisDemo を読み込み可視化の実行例
画面右側の「データ」ペインに TableTennisDemo の項目が表示されたら準備完了です。あとは自由にドラッグ&ドロップしてレポートを作成しましょう。
例えば、以下のように設定すると簡単にグラフが作れます。
- 横棒グラフ: 「サーブの種類(ServeType)」ごとの得点傾向を分析
- 積み上げ棒グラフ: 「サーブのコース(Course)」ごとの得点傾向を分析
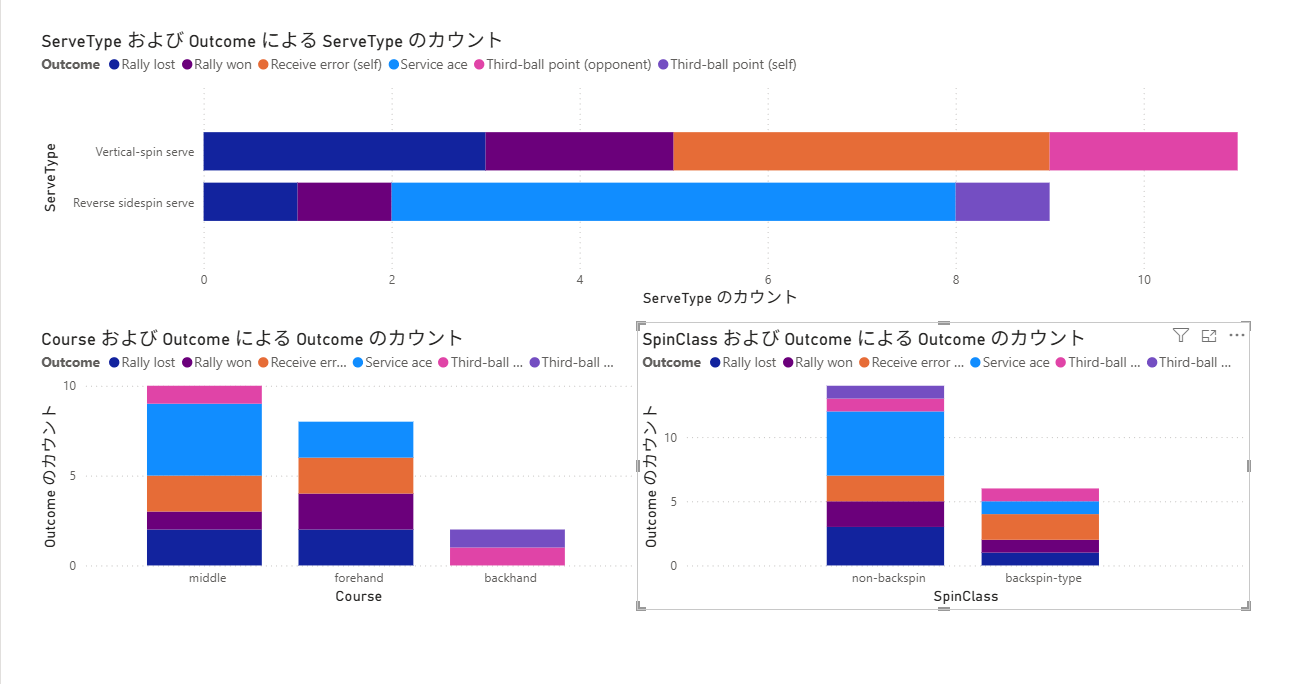
これで Azure を使ったデータ分析基盤の一連の構築はすべて完了です。
まとめ
今回は、Azure を利用して生データ(CSV)から視覚的なレポートを作成するまでの一連のデータ分析基盤(Blob → ADF → SQL → Power BI)を構築する手順を解説しました。
- まず「論理 SQL サーバー」を作成し、管理者アカウント(SQL 認証)を確実に設定しましょう。
- ADF からの通信拒否を防ぐため、DB 作成後に「Azure サービスへのアクセス許可」を必ずオンにします。
- データ格納の確認は、ポータル上のクエリエディターで
SELECTコマンドを実行するのが一番手軽で確実です。
以上、最後までお読みいただきありがとうございました。


