

はじめに
前回の記事では、Azure Data Factory (ADF)を使って「手動」でデータをコピーする手順を紹介しました。 今回はそれを発展させ、「Blob Storage に CSV を置くだけ」 で自動的にパイプラインが起動し、SQL Database へ取り込む仕組み(イベントトリガー)を構築します。
- 「ファイルを置くだけ」 で動く自動化パイプラインの構築
- ADF イベントトリガー(Blob Created)の設定手順
- ファイル名を動的に受け渡す パラメータ設定 の方法

全体アーキテクチャ
構成は以下のとおり前回と同じです。
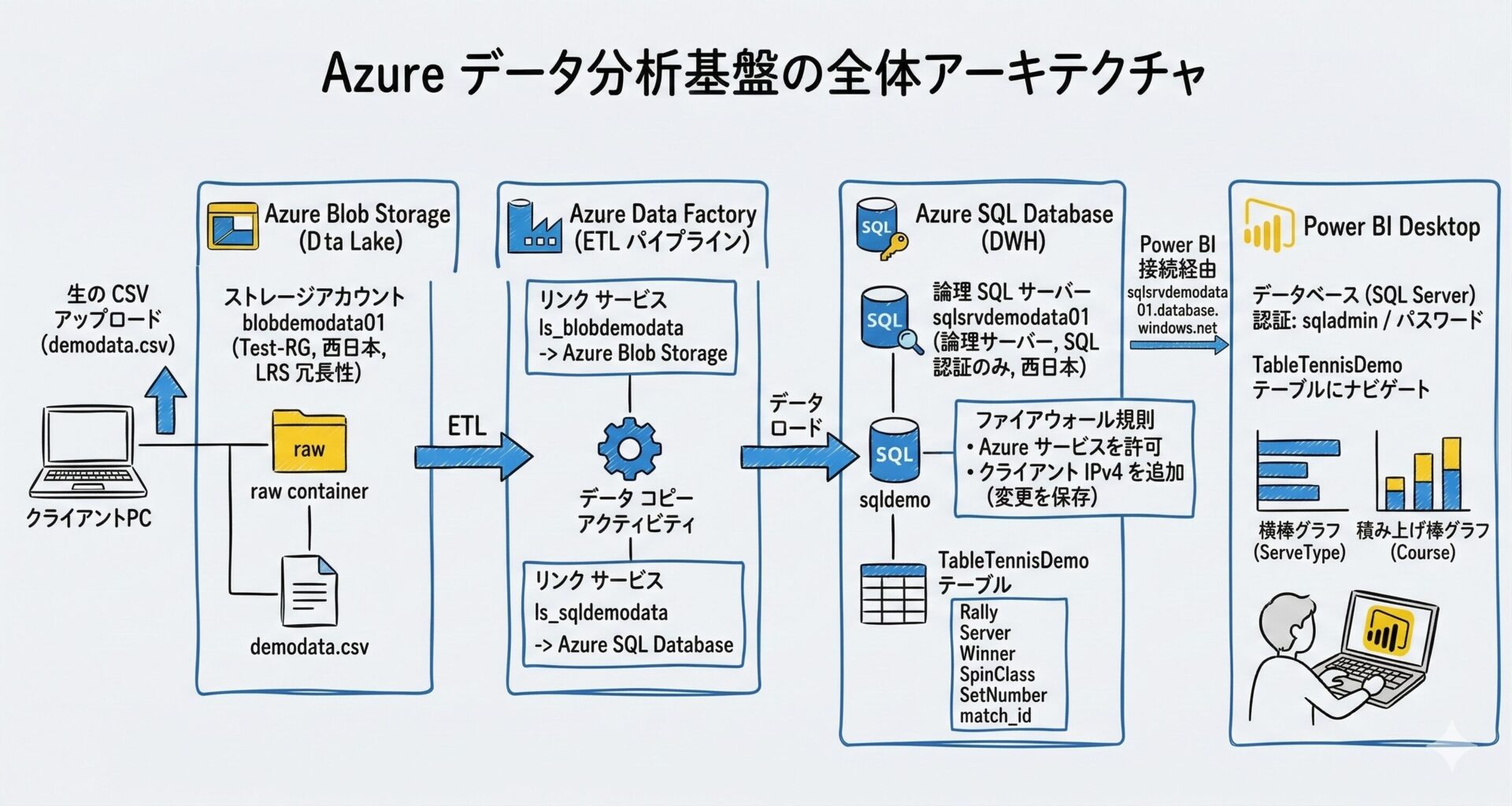
ユーザーが Blob Storage の raw/inbox/ にファイルを配置
ADF の「Storage Event Trigger」がファイルの作成を検知
ADF がデータをコピーし、SQL Database(サーバーレス)へ追記
Power BI(DirectQuery)で最新データを表示
導入手順
ストレージ(ADLS Gen2)の準備
まずはデータレイクとなるストレージを作成し、テストデータを配置します。
Azureポータルから「ストレージアカウント」を新規作成します。今回はデータレイクとして利用するため、「階層型名前空間(HNS)」の有効化が必須となります。実際の画面のタブに沿って以下の通り設定してください。
- リソースグループ:
rg-lake-demo - アカウント名:
stlakedemo01 - リージョン:
Japan West(または任意のリージョン) - パフォーマンス:
Standard - 冗長性:
ローカル冗長ストレージ (LRS) - 詳細設定: 「階層型名前空間を有効にする」にチェックを入れる
入力が完了したら「作成」をクリックし、デプロイを完了させます。
リソースの作成が完了したら、CSV ファイルを格納するフォルダ構成を準備します。
- 作成したストレージアカウントの管理画面を開き、左側メニューの「データ ストレージ」から「コンテナー」を選択します。
- 画面上の「+ コンテナー」をクリックし、名前を raw として作成します。
- 作成した
rawコンテナを開き、「+ ディレクトリの追加」からinboxというサブフォルダを作成します。
これで、以下のようなフォルダ構成が完成します。
raw/
└── inbox/
実際の運用では、ユーザーがこの inbox フォルダに CSV ファイルをアップロードするだけで、それをトリガーに後続の自動処理が走る仕組みになります。
SQL Database(サーバーレス)の準備
データの格納先となるデータベースを用意します。今回は検証・運用コストを最小限に抑えるため、使用した分だけ課金される「サーバーレス」構成を選択します。
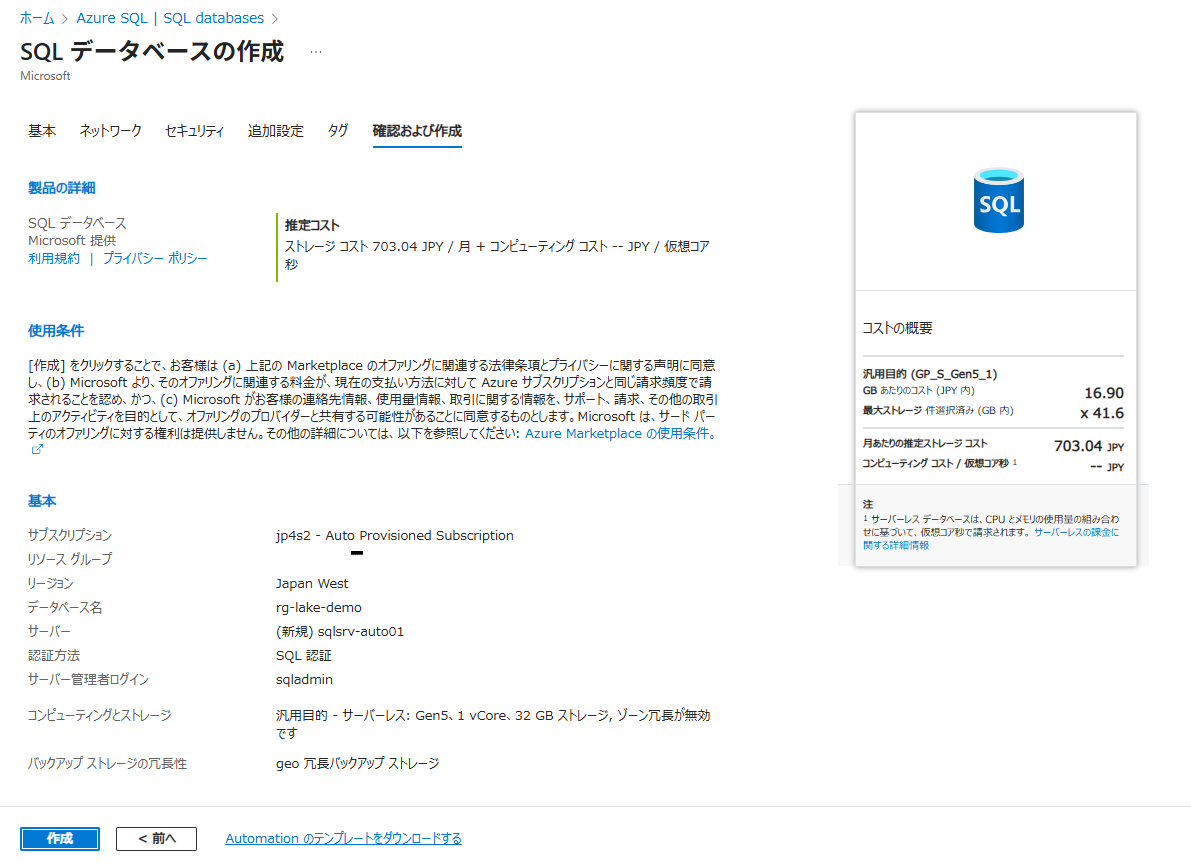
Azure ポータルから「SQL データベース」を新規作成します。ここで論理サーバーを新規作成する際、「SQL 認証(管理者アカウント)」を設定しておくことが、後でクエリエディターを使用するための必須条件となります。
- データベース名:
sqlauto - サーバー: 「新規作成」をクリックし、以下の情報を入力して「OK」を押します。
- サーバー名:
sqlsrv-auto01 - 場所:
Japan West - 認証方法: 「SQL 認証を使用する」を選択
- サーバー管理者ログイン:
sqladmin(任意のユーザー名) - パスワード: (任意の複雑なパスワード)
- サーバー名:
- コンピューティングとストレージ: 「サーバーレス」を選択
- 自動一時停止: 有効(例:1時間)
入力後、「作成」をクリックしてデプロイを完了させます。
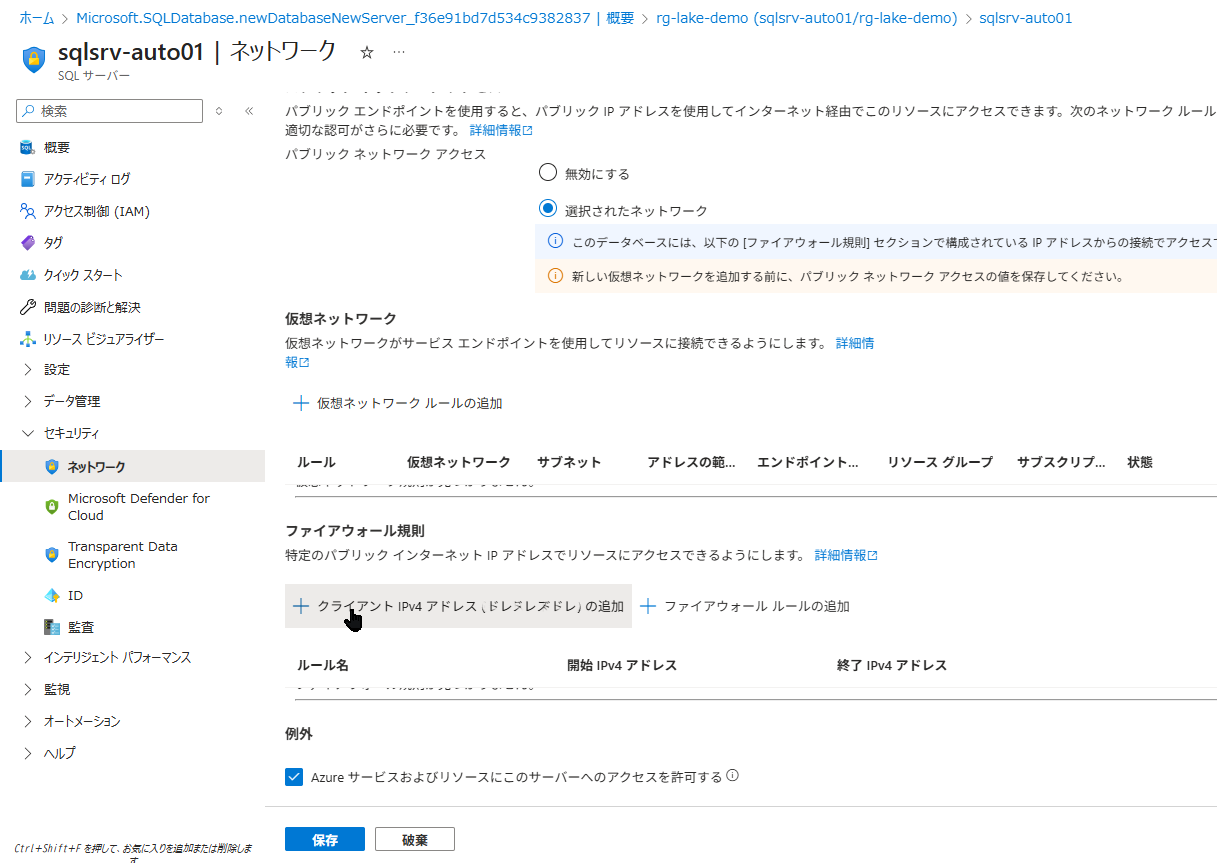
デプロイが完了したら、後続の Data Factory(ADF)やご自身の PC からこのデータベースに接続できるよう、ネットワークの許可設定を行います。
- 作成した SQL データベース(
sqlauto)の概要ページを開き、上部のメニューから「サーバーのファイアウォールの設定」をクリックします。 - 「Azure サービスおよびリソースにこのサーバーへのアクセスを許可する」 のチェックをオンにします(ADF からのデータ書き込みに必須です)
- 「クライアントの IPv4 アドレスを追加する」 をクリックします(ご自身の PC からのクエリエディター操作に必須です)
- 画面左上の「保存」を忘れずにクリックします。
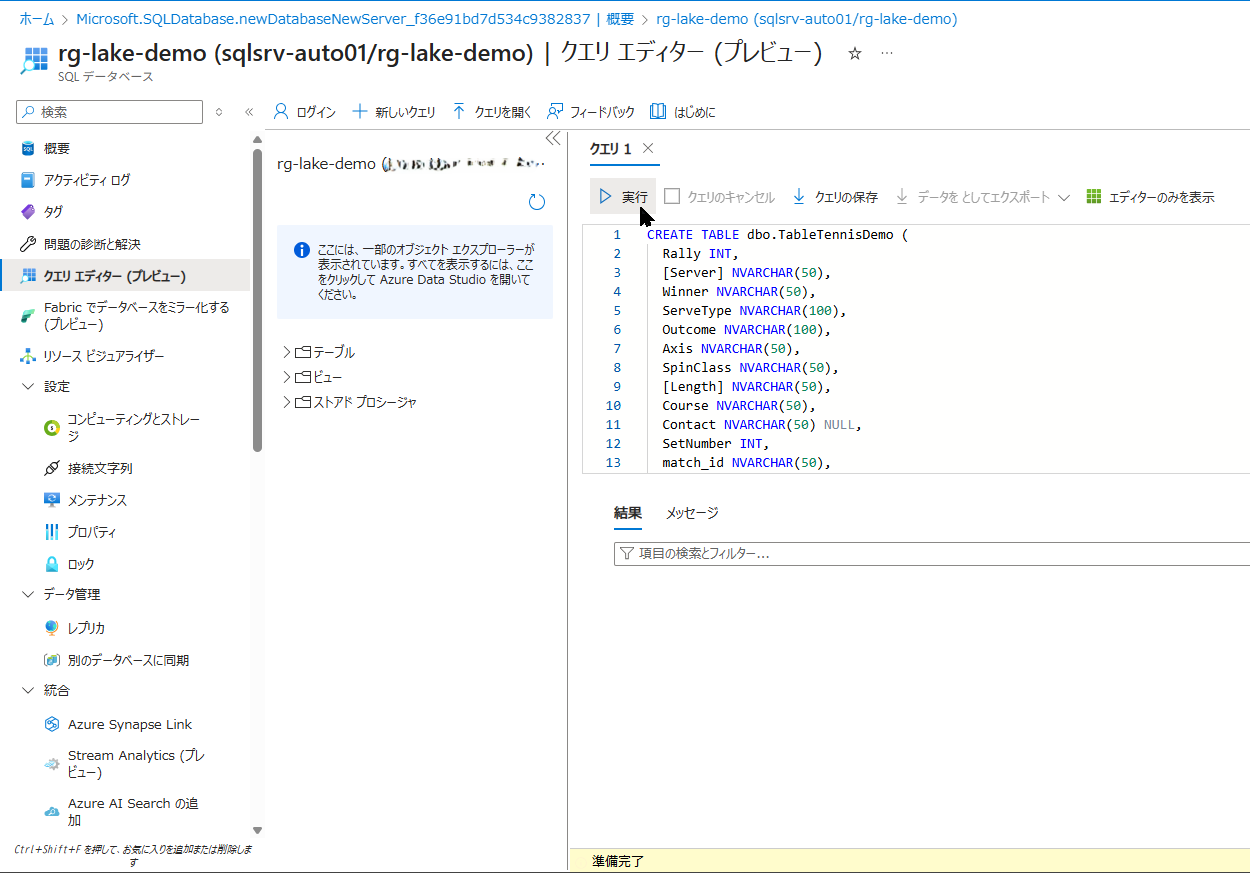
「クエリエディター」を開き、以下の SQL を実行してテーブルを作成します。
- 左側メニューから「クエリ エディター (プレビュー)」を開きます。
- ログイン画面が表示されるので、STEP1で設定した SQL Server 認証のユーザー名(sqladmin)とパスワードを入力して「OK」をクリックします。
- エディター画面が開いたら、以下の SQL 文を貼り付け、左上の「▶ 実行」をクリックします。
CREATE TABLE dbo.TableTennisDemo (
Rally INT,
[Server] NVARCHAR(50),
Winner NVARCHAR(50),
ServeType NVARCHAR(100),
Outcome NVARCHAR(100),
Axis NVARCHAR(50),
SpinClass NVARCHAR(50),
[Length] NVARCHAR(50),
Course NVARCHAR(50),
Contact NVARCHAR(50) NULL,
SetNumber INT,
match_id NVARCHAR(50),
created_at DATETIME2,
player NVARCHAR(50),
opponent NVARCHAR(50)
);
テーブルが正しく作成されたか確認します。エディター内の先ほどの SQL 文を消去し、以下の確認用クエリを実行してください。
SELECT COUNT(*) AS cnt FROM sys.tables WHERE name = 'TableTennisDemo';画面下部の結果ペインに cnt が 1 と表示されれば、データの受け入れ準備は完了です。
Data Factory の構築
ここからパイプラインを作成します。今回は「パラメータ」を使ってファイル名を動的に扱う点がポイントです。
Azure ポータルから「Data Factory」を作成し、ADF Studio(管理画面)を開きます。
- 名前:
adf-lakedemo - リージョン: Japan East
デプロイ完了後、作成したリソースの概要画面を開き、画面中央にある「スタジオの起動(Launch studio)」をクリックして、専用の管理画面(ADF Studio)を開きます。
ADF からストレージとデータベースへアクセスするための接続情報(リンクサービス)を作成します。
- 左側メニューのカバン型アイコン「管理(Manage)」を選択します。
- 「リンク サービス」>「+ 新規」から、以下の 2 つを作成します。
- Azure Data Lake Storage Gen2 用
- 名前:
ls_adls - アカウント:
stlakedemo01
- 名前:
- Azure SQL Database 用
- 名前:
ls_sqlauto - サーバー名:
sqlsrv-auto01/ データベース名:sqlauto
- 名前:
- Azure Data Lake Storage Gen2 用
手順 2 で設定した SQL 認証情報を入力します。
読み込むデータ(CSV)の定義を作成します。ファイル名を動的に受け取るためのパラメータ設定が重要です。
- 左側メニューの鉛筆型アイコン「作成(Author)」を選択します。
- 「ファクトリリソース」ペインの「+」ボタンをクリックし、「データセット」を選択します。
Azure Data Lake Storage Gen2CSV (区切りテキスト)を選択します。- 名前を
ds_raw_csv、リンクサービスをls_adlsに設定し、ファイルパスは一旦空欄のまま「OK」をクリックします。 - 開いた画面の下部にある「パラメーター」タブを選択し、「+ 新規」から以下の2つを追加します。
folder(型: String)file(型: String)
- 「接続」タブに戻ります。ファイルパスの入力欄をクリックし、下に表示される「動的なコンテンツの追加」を選択して以下のように設定します。
- 中央の入力欄(ディレクトリ)に
@dataset().folderと入力 - 右側の入力欄(ファイル名)に
@dataset().fileと入力
- 中央の入力欄(ディレクトリ)に
Directory = などの文字は含めず、上記の @ から始まる値のみを入力してください
書き込み先のデータ定義を作成します。
- 先ほどと同様に「+」ボタン 「データセット」から
Azure SQL Databaseを選択します。 - 名前を
ds_sql_tennis、リンクサービスをls_sqlautoに設定します。 - テーブル名に、手順 2 で作成した
dbo.TableTennisDemoを選択して「OK」をクリックします。
実際のデータコピージョブを組み立てます。
- 「+」ボタン 「パイプライン」 「パイプライン」を選択し、名前を
pl_inbox_to_sqlとします。 - 右側の広いキャンバスの空白部分をクリックし、下部の「パラメーター」タブから以下の 2 つを追加します。
p_folder(型: String)p_file(型: String)
- 左側のアクティビティ一覧から「移動と変換」を展開し、「データのコピー(Copy data)」をキャンバスへドラッグ&ドロップします。
- 配置した「データのコピー」アイコンをクリックし、下部の設定ペインを入力します。
- ソースタブ: ソースデータセットに
ds_raw_csvを選択。表示されたデータセットプロパティに、動的コンテンツで値を割り当てます。- folder の値:
@pipeline().parameters.p_folder - file の値:
@pipeline().parameters.p_file
- folder の値:
- シンクタブ: シンクデータセットに
ds_sql_tennisを選択
- ソースタブ: ソースデータセットに
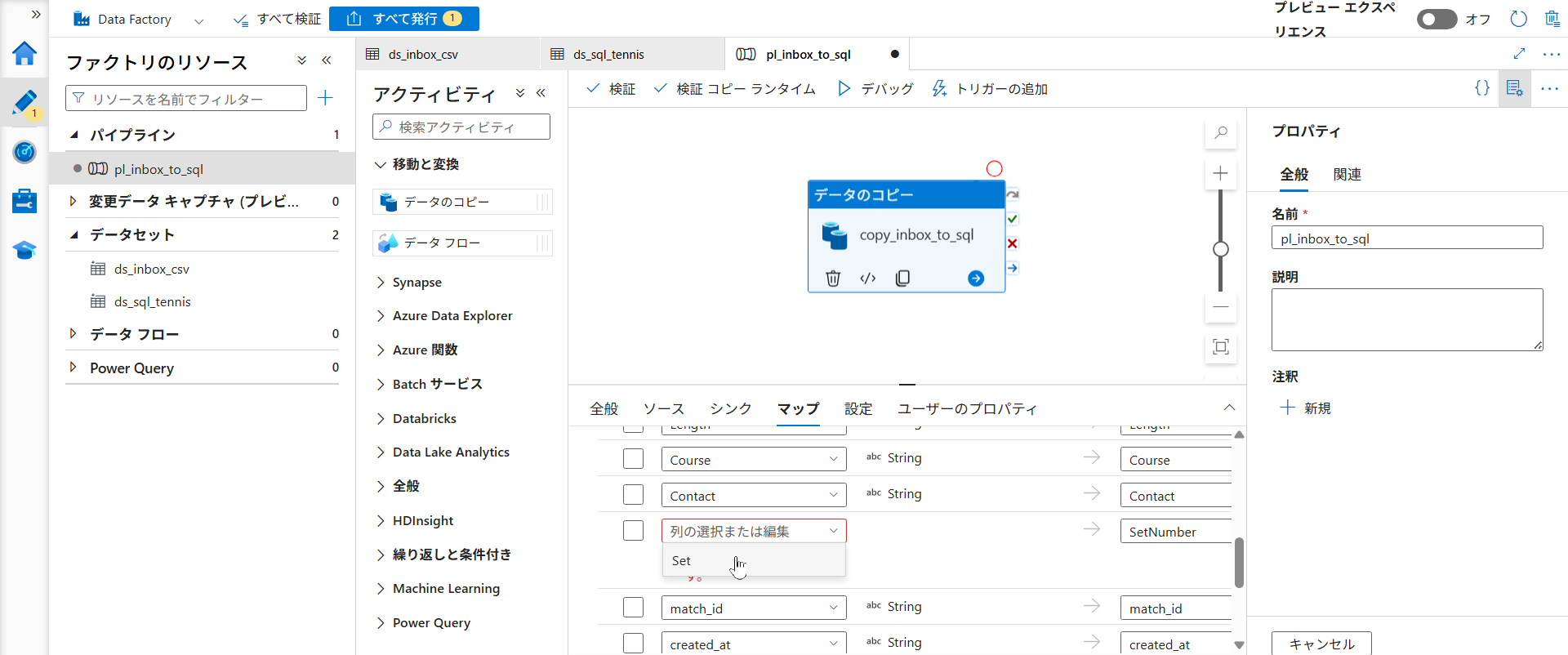
最後に、CSV の列とデータベースの列を正しく紐付けます。
【重要】スキーマをインポートするため、あらかじめストレージの raw/inbox/ フォルダ内に、テスト用の CSV ファイル(demodata.csv)をアップロードしておいてください。
- 「データのコピー」を選択した状態で、下部の「マッピング」タブを開きます。
- 「スキーマのインポート」をクリックします。パラメータの値を求められるので、仮の値として以下を入力します。
- p_folder:
raw/inbox(またはinbox※ご自身の構成に合わせてください) - p_file:
demodata.csv
- p_folder:
- 読み込まれた列の一覧が表示されたら、CSV 側の「Set」列のプルダウンを開き、SQL 側の「SetNumber」に手動で紐付け直します。
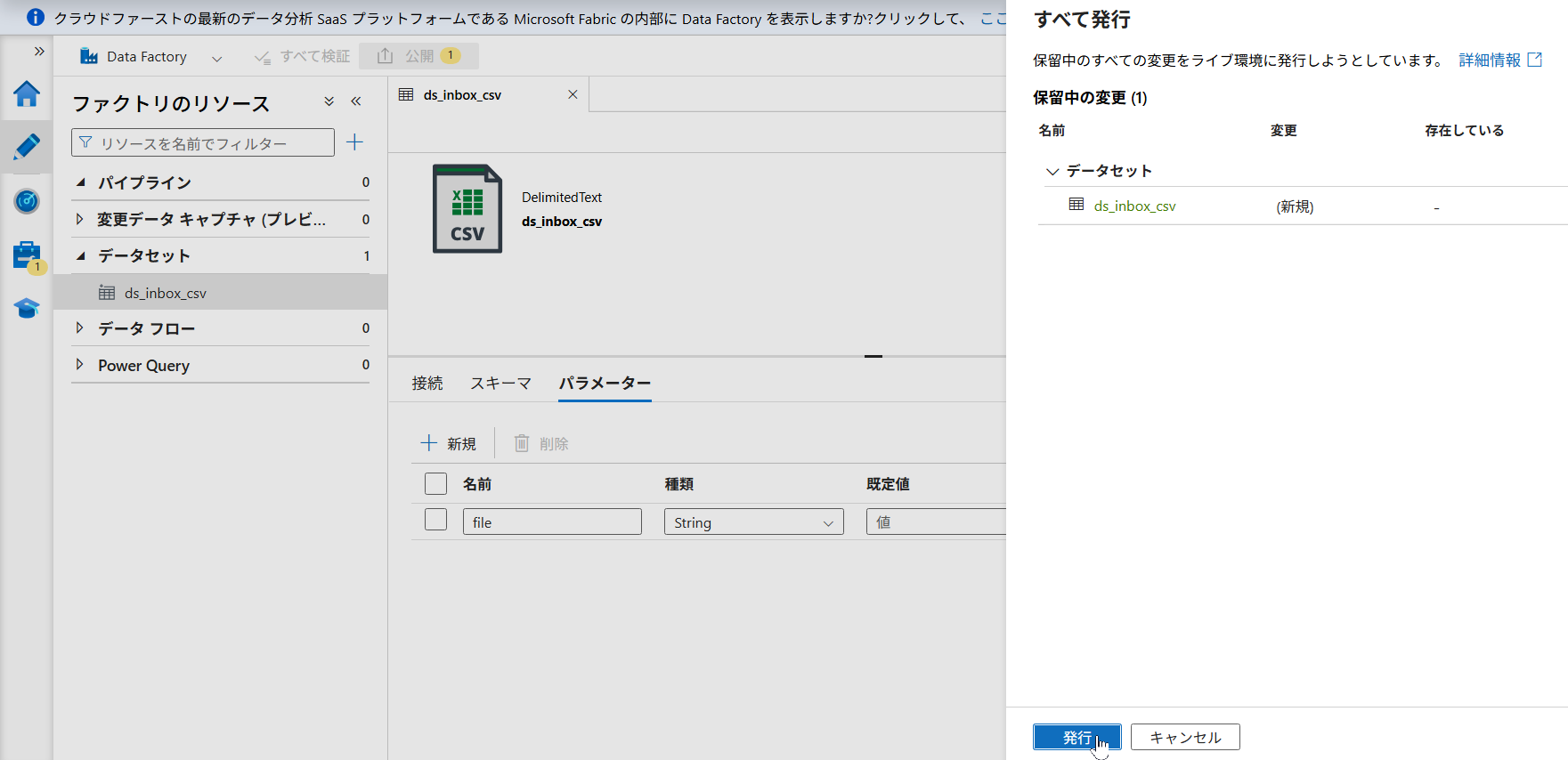
- 設定がすべて完了したら、画面左上の「すべて発行(Publish all)」をクリックして、これまでの作業内容を ADF に保存(デプロイ)します。
イベントトリガーの設定
最後に、ファイルが配置されたことを検知してパイプラインが自動で動くように設定します。
- ADF Studio の左側メニュー「管理(カバン型アイコン)」>「トリガー」>「+ 新規」をクリックします。
- 以下の内容で設定します。
- 名前:
trg_inbox_to_sql - 種類:
ストレージイベント - ストレージアカウント名:
stlakedemo01 - コンテナー名:
raw - BLOB パスの末尾:
.csv(CSV ファイルのみを対象とします)
- 名前:
- 「管理」→「トリガー」→「+ 新規」をクリックします。
- 「次へ」進み、実行するパイプラインに作成した
pl_inbox_to_sqlを選択します。 - トリガーが検知したファイル情報をパイプラインに渡すため、パラメーターの設定画面で以下を入力します。
- p_file:
@triggerBody().fileName - p_folder:
@triggerBody().folderPath
- p_file:
環境によっては folderPath に raw/ が含まれてパスがズレる場合があります。その場合は @replace(triggerBody().folderPath, 'raw/', '') のように replace 関数を使用してください。
- トリガーの設定を完了し、画面左上の「すべて発行」をクリックして保存します。
- トリガーの状態が「開始済み(有効)」になっていることを確認します。
Power BI との連携
SQL Database に蓄積されたデータを、Power BIで可視化します。
今回はデータが追加されたらすぐにグラフに反映されるよう、リアルタイム性を重視した「DirectQuery」モードを使用します。
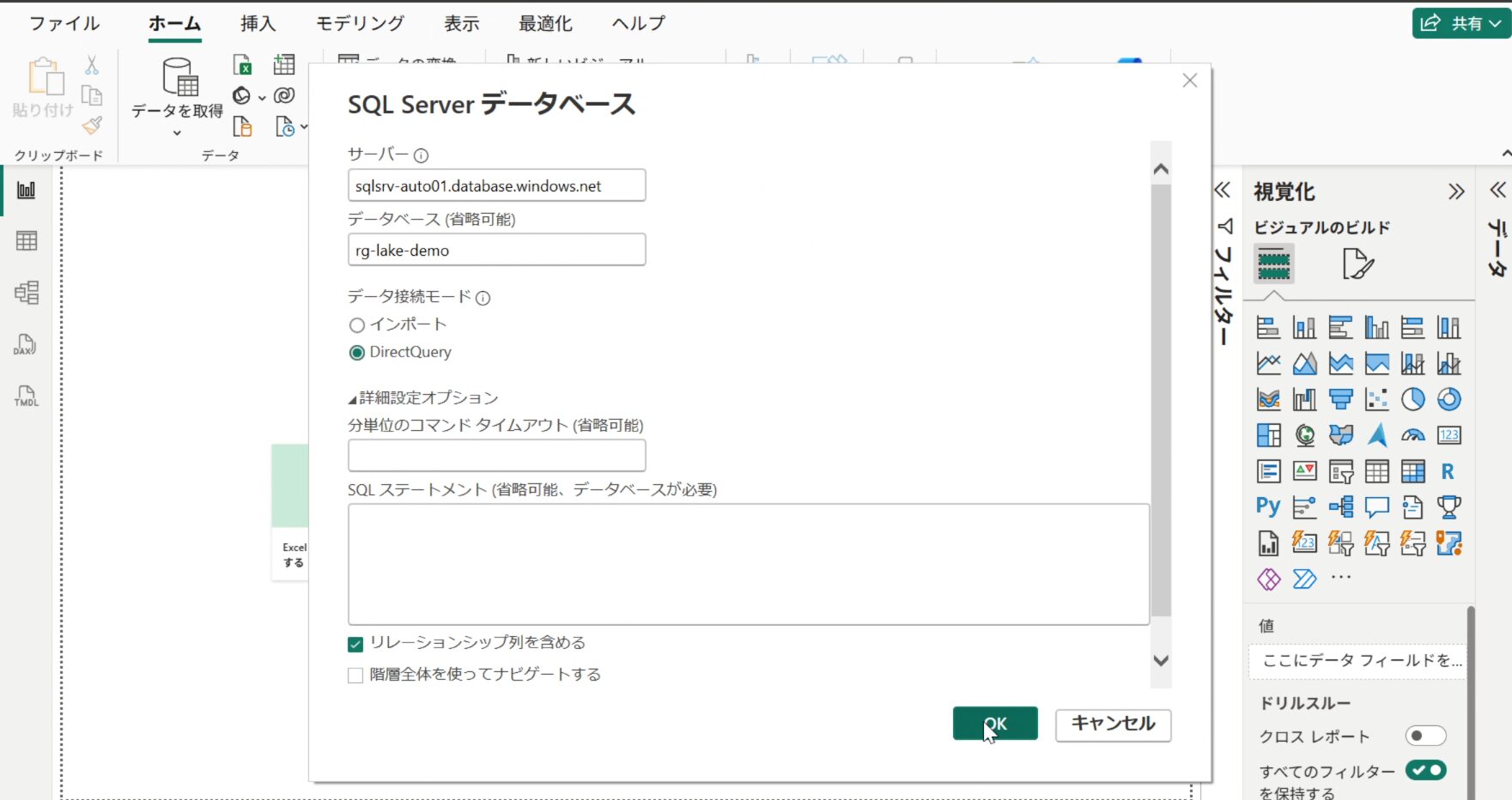
- Power BI Desktop を起動し、「データの取得」「Azure」「Azure SQL データベース」を選択します。
- 以下の情報を入力して接続します。
- サーバー:
sqlsrv-auto01.database.windows.net - データベース:
sqlauto - データ接続モード:
DirectQuery
- サーバー:
- 認証画面が表示されたら、「データベース」タブを選択し、手順 2 で設定した SQL 認証情報(sqladmin / パスワード)でログインします。
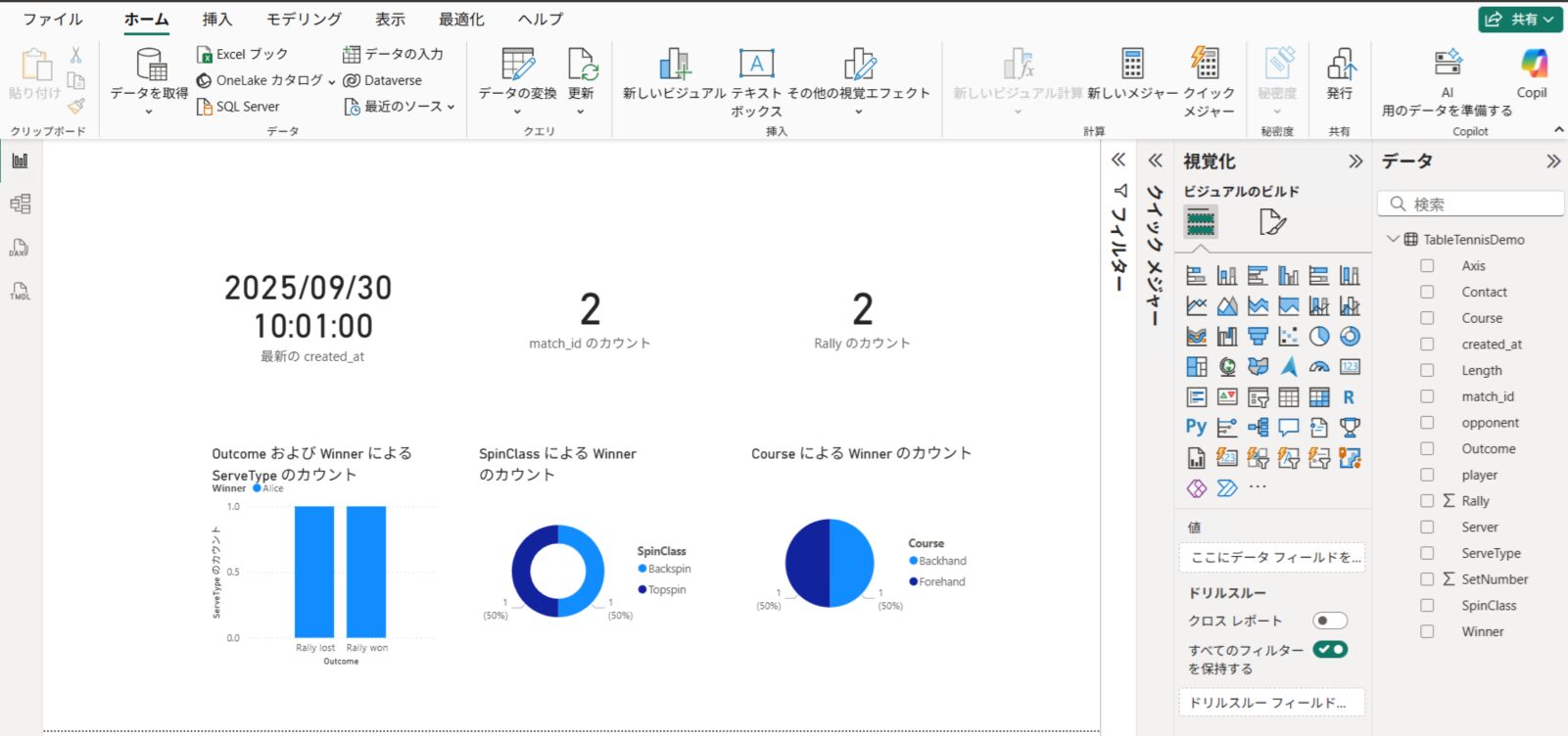
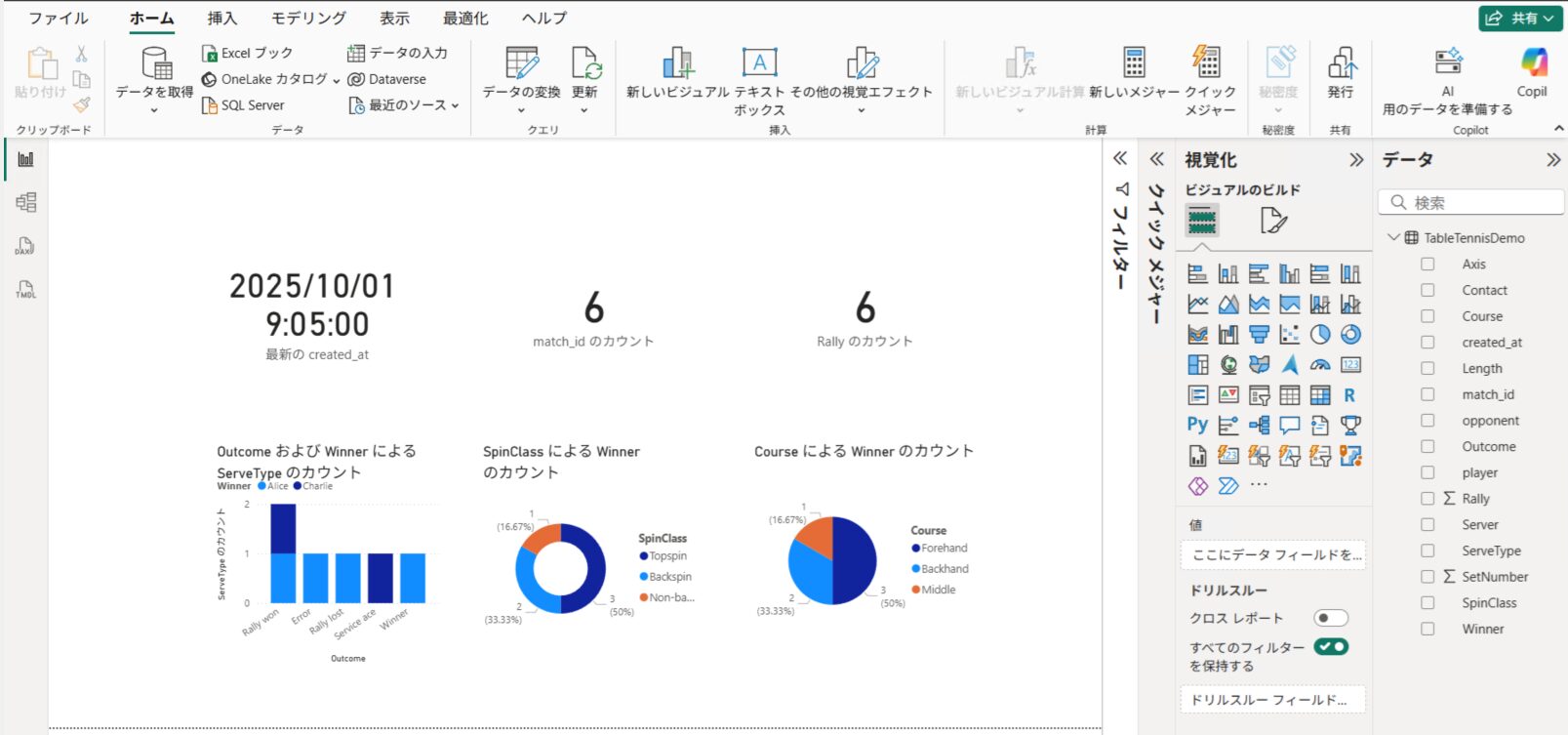
ナビゲーター画面で dbo.TableTennisDemo テーブルを選択して読み込みます。右側のフィールド一覧から項目をキャンバスにドラッグ&ドロップし、グラフや表を作成します。
- 手動更新: Power BI Desktop 上部の「更新」ボタンを押すと最新化されます。
- Auto page refresh: Premium 機能などを使い、数分ごとに自動更新させることも可能です。
- Import + スケジュール: DirectQuery ではなく「インポート」モードを選んだ場合は、Power BI Service 上で1日8回などのスケジュール更新が設定できます。
動作確認
実際に新しいファイルを置き、全自動でPower BIまで反映されるかテストします。
Azure ポータルなどを使い、ストレージの raw/inbox/ フォルダに新しいファイル(例: demodata_new.csv)をアップロードします。
参考: demodata_new.csv の中身
Rally,Server,Winner,ServeType,Outcome,Axis,SpinClass,Length,Course,Contact,Set,match_id,created_at,player,opponent
1,Alice,Alice,Forehand,Winner,Right,Topspin,Short,Forehand,None,1,M001,2025-09-30 10:00:00,Alice,Bob
2,Bob,Alice,Backhand,Error,Left,Backspin,Long,Backhand,Edge,1,M001,2025-09-30 10:01:00,Alice,Bob
3,Charlie,Charlie,Reverse sidespin serve,Service ace,Right,Topspin,Half-long,Middle,,2,M002,2025-10-01 09:00:00,Charlie,Dana
4,Dana,Charlie,Vertical-spin serve,Rally won,Left,Non-backspin,Long,Forehand,,2,M002,2025-10-01 09:05:00,Charlie,Dana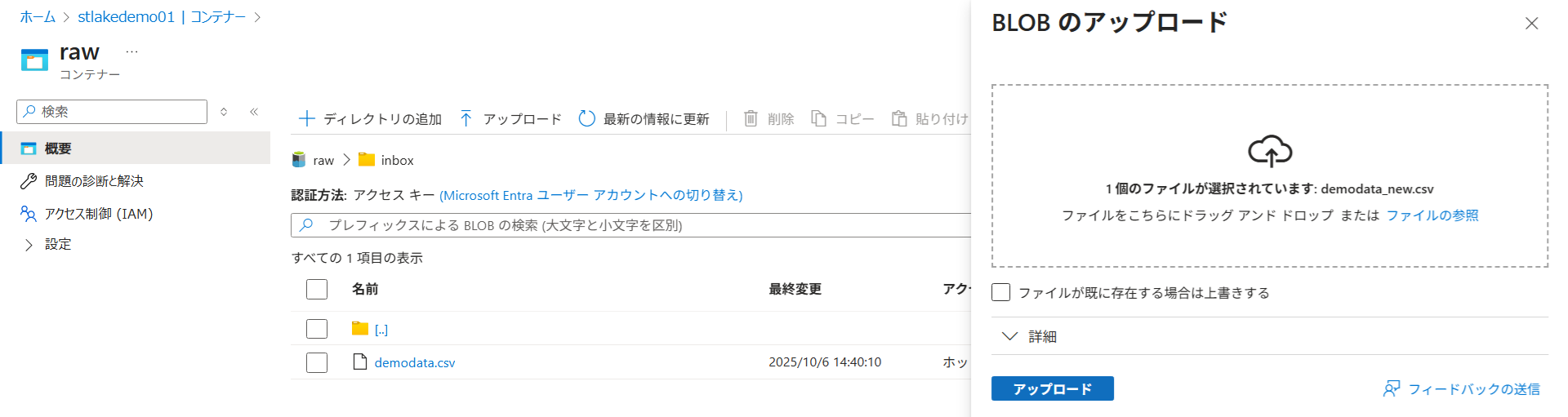
新しく投入する CSV ファイルの列名は、元のサンプルデータと全く同じである必要があります。 手順 3 のマッピング設定で「Set」という列名を「SetNumber」に変換するように設定しているため、アップロードする CSV 側の列名は「Set」のままで問題ありません。CS V側を「SetNumber」に書き換えてしまうと、ADF が「Set という列が存在しない」と判断してエラーになるためご注意ください。
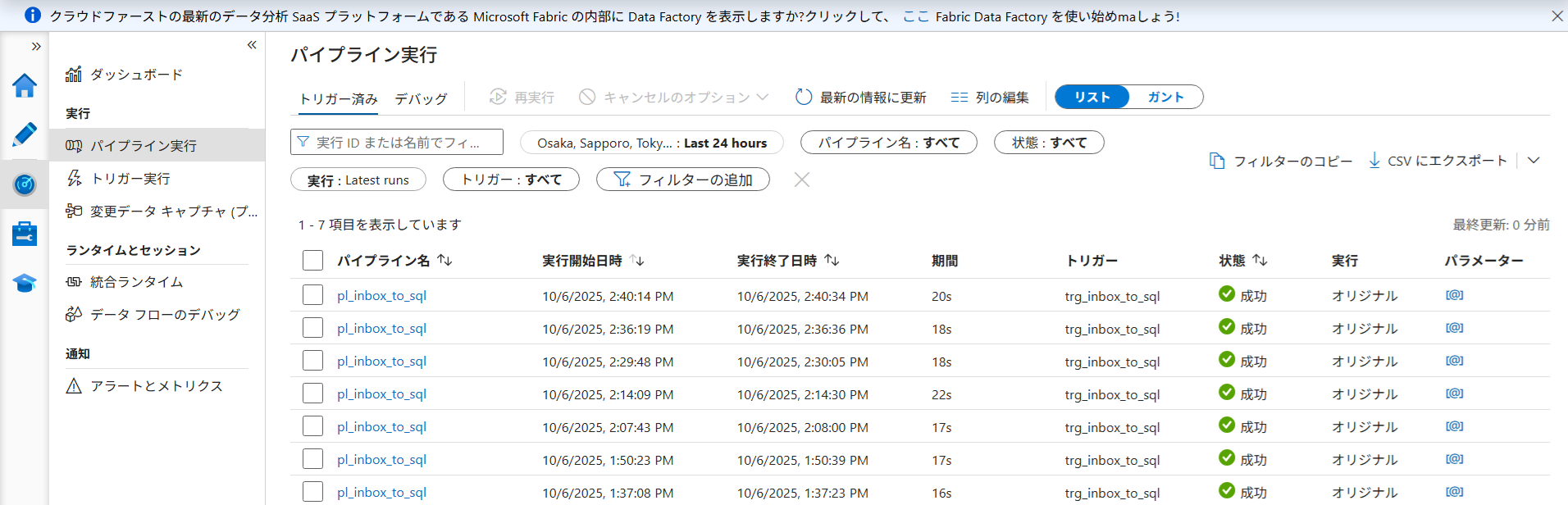
ADF Studio の左側メニュー「監視(メーター型アイコン)」を開きます。ファイルのアップロードを検知してパイプラインが自動起動し、ステータスが「Succeeded(成功)」になっていることを確認します。
Power BI Desktop の上部にある「更新」ボタンをクリックし、新しく追加したデータの分だけグラフが変化することを確認します。
データ削除(クリーンアップ)について
検証を繰り返してデータが重複した場合、以下の方法でデータをリセットできます。
方法1: 手動で削除
Azure ポータルの「クエリエディター」から SQL を実行して削除します。
全件削除: テーブルを空にし、ID の連番もリセットします。
TRUNCATE TABLE dbo.TableTennisDemo;条件削除: 特定の日付以前のデータのみ削除します。
DELETE FROM dbo.TableTennisDemo
WHERE created_at < '2025-09-30';方法2: ADF で自動削除
ファイルを取り込む前に、自動的に既存データを消す設定です。
ADF パイプラインの「Copy Data」アクティビティの前段に、Script Activity を追加し、以下のクエリを設定します。
TRUNCATE TABLE dbo.TableTennisDemo;これを組み込んでおくと、常にクリーンな状態で検証できるため、テスト環境では非常に便利です。
まとめ
今回の仕組みにより、「指定フォルダに CSV を配置するだけ」でデータが自動的に SQL へ格納され、Power BI で最新状況を可視化する完全なパイプラインが完成しました。
- Blob Storage へのファイル配置をイベントトリガーで検知できる。
- ADF のパラメータと動的コンテンツを使用し、ファイル名を柔軟に受け渡すことができる。
- DirectQuery を利用することで、SQL Database の最新データを即座に Power BI に反映できる。
- マッピング設定を活用すれば、ソースデータとデータベースの列名が異なっても自動で変換して取り込める。
以上、最後までお読みいただきありがとうございました。
